Enable switchdev mode
The VF representor has switchdev ops
Switchdev mode is a mode in E-Switch, that binds between representor and VF.
Representor is a port in DPDK that is
connected to a VF in such a way that assuming there are no offload flows, each packet that is sent from the
VF will be received by the corresponding representor. While each packet that is sent to a representor will be received by the VF.
This is very useful in case of SRIOV mode, where the first packet that is sent by the VF will be received by the DPDK application which will
decide if this flow should be offloaded to the E-Switch. After offloading the flow packet that the VF that are matching the flow will not be received any more by the DPDK application. Enable SRIOV mode: mlxconfig -d <mst device> set SRIOV_EN=true Configure the max number of VFs: mlxconfig -d <mst device> set NUM_OF_VFS=<num of vfs> Reset the FW: mlxfwreset -d <mst device> reset Configure the actual number of VFs: echo <num of vfs > /sys/class/net/<net device>/device/sriov_numvfs Unbind the device (can be rebind after the switchdev mode): echo -n "<device pci address" > /sys/bus/pci/drivers/mlx5_core/unbind Enbale switchdev mode: echo switchdev > /sys/class/net/<net device>/compat/devlink/mode
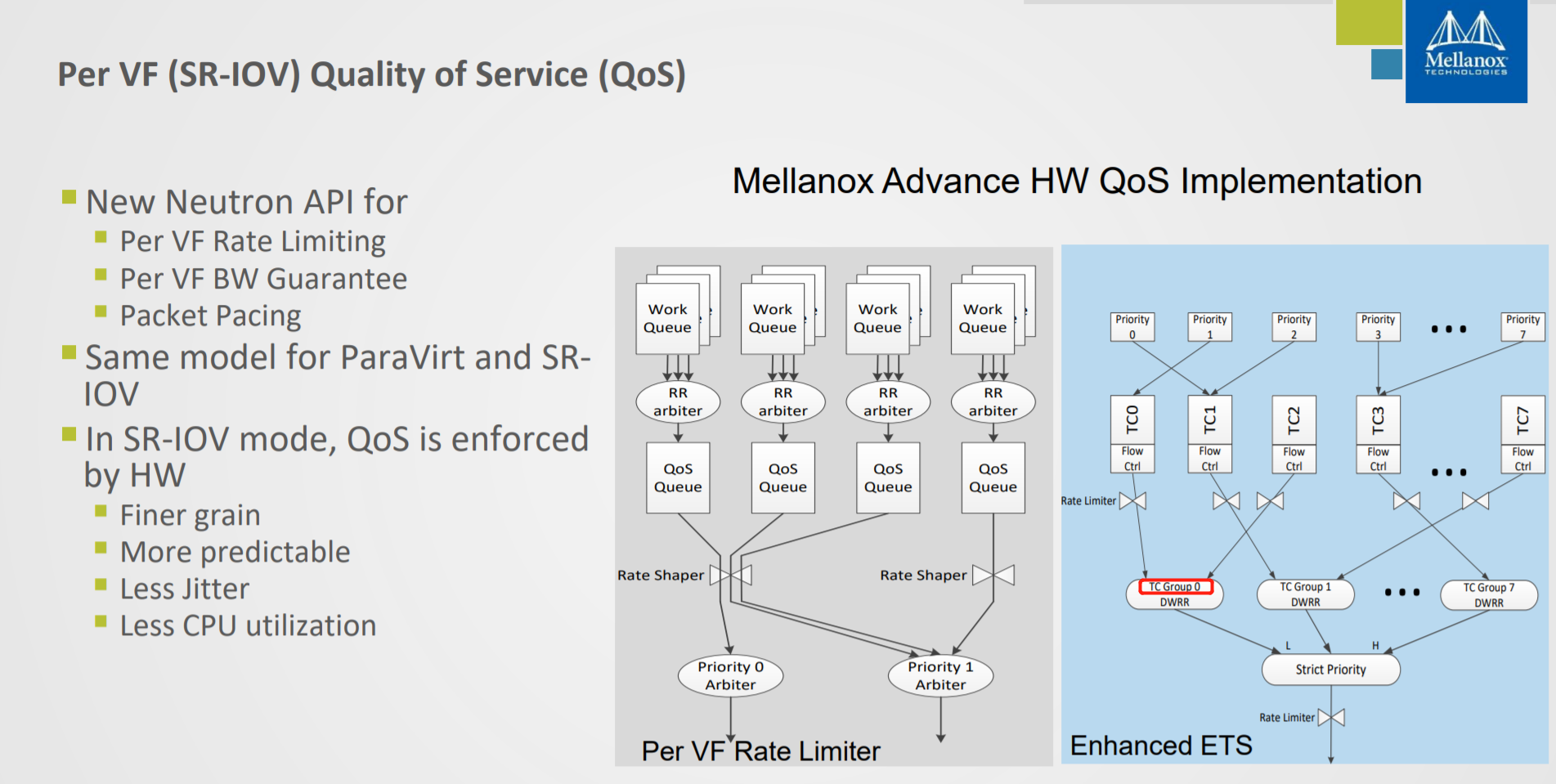
OpenVSwitch Hardware offload
https://www.sdnlab.com/23003.html
OpenVSwitch硬件卸载是近几年才提出的方案,到目前为止并不完全成熟。
Linux TC(Traffic Control)Flower
要介绍OVS硬件卸载,必须要从TC说起。TC在Linux Kernel 2.2版本开始提出,并在2.4版本(2001年)完成。最初的Linux TC是为了实现QoS[1],当然TC现在仍然有QoS的功能。它在netdev设备的入方向和出方向增加了挂载点,进而控制网络流量的速度,延时,优先级等。Linux TC在整个Linux Kernel Datapath中的位置如下图所示:
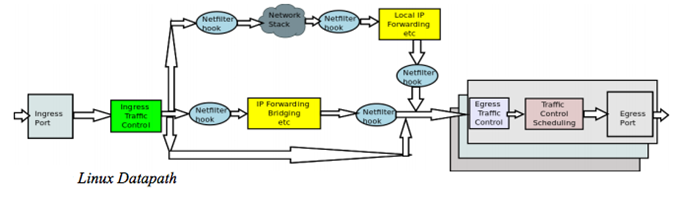
随后,TC增加了Classifier-Action子系统[2],可以根据网络数据包的报头识别报文,并执行相应的Action。与其他的Classifier-Action系统,例如OpenFlow,不一样的是,TC的CA子系统并不只是提供了一种Classifier(识别器),而是提供了一个插件系统,可以接入任意的Classifier,甚至可以是用户自己定义的Classifier。
在2015年,TC的Classifier-Action子系统增加了对OpenFlow的支持[3],所有的OpenFlow规则都可以映射成TC规则。随后不久,OpenFlow Classifier又被改名为Flower Classifier。这就是TC Flower的来源。
Linux TC Flower hardware offload
在2011年,Linux内核增加了基于硬件QoS的支持[4]。因为TC就是Linux内实现QoS的模块,也就是说Linux增加了TC的硬件卸载功能。在2016年,Linux内核又增加了对TC Classifier硬件卸载的支持,但是这个时候只支持了u32类型的Classifier(与TC Flower并列的,但是历史更悠久的一种Classifier)。在4.9~4.14内核,Linux终于增加了对TC Flower硬件卸载的支持。也就是说OpenFlow规则有可能通过TC Flower的硬件卸载能力,在硬件(主要是网卡)中完成转发。
TC Flower硬件卸载的工作原理比较简单。当一条TC Flower规则被添加时,Linux TC会检查这条规则的挂载网卡是否支持并打开了NETIF_F_HW_TC标志位,并且是否实现了ndo_steup_tc(TC硬件卸载的挂载点)。如果都满足的话,这条TC Flower规则会传给网卡的ndo_steup_tc函数,进而下载到网卡内部[5]。
网卡的NETIF_F_HW_TC标志位可以通过ethtool来控制打开关闭:
# ethtool -K eth0 hw-tc-offload on
# ethtool -K eth0 hw-tc-offload off
同时,每条规则也可以通过标志位来控制是否进行硬件卸载。相应的标志位包括以下:
- TCA_CLS_FLAGS_SKIP_HW:只在软件(系统内核TC模块)添加规则,不在硬件添加。如果规则不能添加则报错。
- TCA_CLS_FLAGS_SKIP_SW:只在硬件(规则挂载的网卡)添加规则,不在软件添加。如果规则不能添加则报错。
- 默认(不带标志位):尝试同时在硬件和软件下载规则,如果规则不能在软件添加则报错。
通过TC命令查看规则,如果规则已经卸载到硬件了,可以看到 in_hw标志位。
Flow install workflow is described in below points,
○ When control plane installs a flow in vRouter. vRouter checks if the offload hook is registered for the flow and invokes the registered offload hook implementer.
○ GOM would have registered the implementer for the hook and hence it gets invoked with vrouter flow structure.
○ GOM’s FlowHandler will check if the flow can be installed using Linux TC flower, it will compare the fields of match and actions in the flow with the supported match and actions of TC.
○ If the flow cannot be installed, then FlowHandler would return -EINVAL to vRouter and vRouter would then install this flow in its datapath.
○ If flow can be installed, then invokes the Qdisc_ops of repr_netdev to setup a flow. skip_sw=True will be set so that flow is only programmed in smartNIC and not in LinuxTC kernel datapath.
○ As explained above, smartNIC driver’s callback is registered for hardware offload with TCF block by invoking tcf_block_cb_register() KPI.
○ Linux TC will invoke the registered callback which will be implemented by driver. Vendor driver would then translate this flow and installs it in NIC.
○ There is a special case here, if smartNIC doesn’t support any of the match/action fields though Linux TC supports it, then in that case vendor driver will return -EINVAL to GOM’s FlowHandler, which will return the same to vRouter and explained above vRouter would then install this flow in its datapath.
OVS-TC
OpenVSwitch在2018年增加了对TC Flower的支持,结合前面的描述,OVS的datapath现在有卸载到网卡的可能了。
前面说过,TC Flower规则现在可以下发到网卡上,相应的网卡上也会有一个虚机交换机。Mellanox称这个虚拟交换机为eSwitch。OVS初始化的时候,会向eSwitch下发一条默认的规则,如果网络包匹配不了任何其他规则,则会被这条默认规则匹配。这条规则的action就是将网络数据包送到eSwitch的管理主机,也就是说送到了位于Linux kernel的datapath上。
如果这个网络数据包是首包的话,那根据前面的描述,在kernel的OVS datapath会继续上送到位于用户空间的ovs-vswitchd。因为ovs-vswitchd中有OpenFlow规则,ovs-vswitchd还是可以完成转发。不一样的地方是,ovs-vswitchd会判断当前数据流对应的规则能否offload(卸载)到网卡。如果可以的话,ovs-vswitchd会调用通过TC接口将flow规则下发至硬件。这样,同一个数据流的后继报文,可以直接在网卡的eSwitch中完成转发,根本不需要走到主机操作系统来。Datapath规则的aging(老化)也是由ovs-vswitchd轮询,最终通过TC接口完成删除。Datapath的变化如下所示。
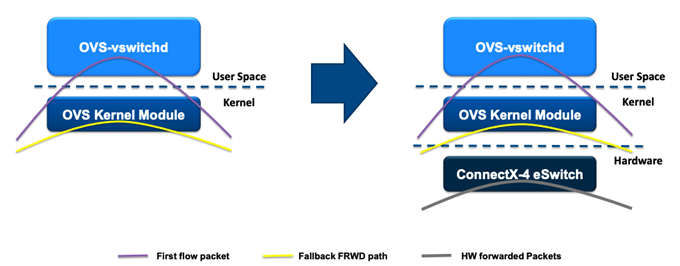
在OVS-TC中,严格来说,现在Datapath有三个,一个是之前的OVS kernel datapath,一个是位于Kernel的TC datapath,另一个是位于网卡的TC datapath。位于kernel的TC datapath一般情况下都是空的,它只是ovs-vswitchd下发硬件TC Flower规则的一个挂载点。
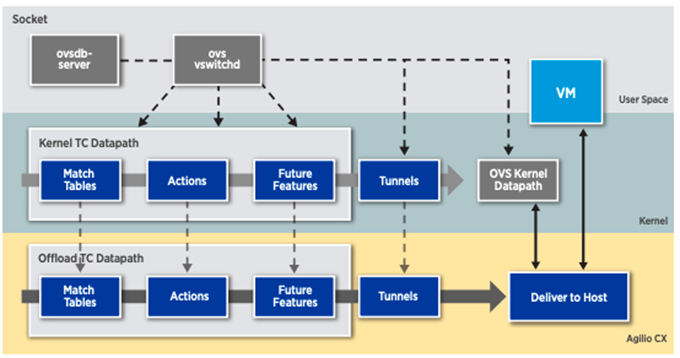


使用OVS-TC方案,可以提供比DPDK更高的网络性能。因为,首先网络转发的路径根本不用进操作系统,因此变的更短了。其次,网卡,作为专用网络设备,转发性能一般要强于基于通用硬件模拟的DPDK。另一方面,网卡的TC Flower offload功能,是随着网卡驱动支持的,在运维上成本远远小于DPDK。
但是OVS-TC方案也有自己的问题。首先,它需要特定网卡支持,不难想象的是,支持这个功能的网卡会更贵,这会导致成本上升,但是考虑到不使用DPDK之后释放出来的CPU和内存资源,这方面的成本能稍微抵消。其次,OVS-TC功能还不完善,例如connection track功能还没有很好的支持。第三,这个问题类似于DPDK,因为不经过Linux kernel,相应的一些工具也不可用了,这使得监控难度更大。
使用 Open vSwitch 硬件卸载
https://blog.csdn.net/sinat_20184565/article/details/95679881
为了使能Open vSwitch的硬件卸载功能,需要以下的步骤:
#. 使能 SR-IOV
#. 配置NIC为 switchdev 模式 (相关节点)
#. 使能 Open vSwitch 硬件卸载
配置内核态SR-IOV
https://support.huaweicloud.com/usermanual-kunpengcpfs/kunpengsriov_06_0006.html
- 给PF网口添加VF。
- 执行添加命令。
echo 8 > /sys/class/net/enp1s0f1/device/sriov_numvfs
- 查看添加是否成功。
cat /sys/class/net/enp1s0f1/device/sriov_numvfs

- 执行添加命令。
- 配置VF端口MAC地址。
- 执行配置命令。
ip link set enp1s0f1 vf 0 mac e4:11:22:33:44:50 ip link set enp1s0f1 vf 1 mac e4:11:22:33:44:51 ip link set enp1s0f1 vf 2 mac e4:11:22:33:44:52 ip link set enp1s0f1 vf 3 mac e4:11:22:33:44:53 ip link set enp1s0f1 vf 4 mac e4:11:22:33:44:54 ip link set enp1s0f1 vf 5 mac e4:11:22:33:44:55 ip link set enp1s0f1 vf 6 mac e4:11:22:33:44:56 ip link set enp1s0f1 vf 7 mac e4:11:22:33:44:57
- 查看配置情况。
ip link show dev enp1s0f1
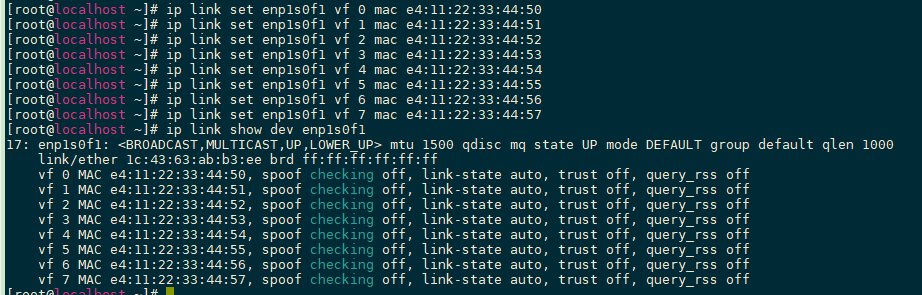
须知:MAC地址不能冲突,包括本机器、对端机器以及交换机上的MAC地址都需保持唯一性。
- 查看8个虚拟端口的PCI端口号。
ls -l /sys/class/net/
- 执行配置命令。
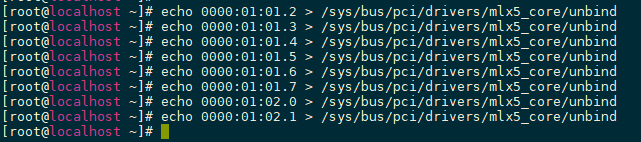
- 切换网口模式。
- 解绑VF。
echo 0000:01:01.2 > /sys/bus/pci/drivers/mlx5_core/unbind echo 0000:01:01.3 > /sys/bus/pci/drivers/mlx5_core/unbind echo 0000:01:01.4 > /sys/bus/pci/drivers/mlx5_core/unbind echo 0000:01:01.5 > /sys/bus/pci/drivers/mlx5_core/unbind echo 0000:01:01.6 > /sys/bus/pci/drivers/mlx5_core/unbind echo 0000:01:01.7 > /sys/bus/pci/drivers/mlx5_core/unbind echo 0000:01:02.0 > /sys/bus/pci/drivers/mlx5_core/unbind echo 0000:01:02.1 > /sys/bus/pci/drivers/mlx5_core/unbind
- 将PF设备上的“eSwitch”模式从“Legacy”修改为“SwitchDev”。
devlink dev eswitch set pci/0000:01:00.1 mode switchdev echo switchdev > /sys/class/net/enp1s0f1/compat/devlink/mode cat /sys/class/net/enp1s0f1/compat/devlink/mode

- 检查Representor设备名是否已变更。
ls -l /sys/class/net/
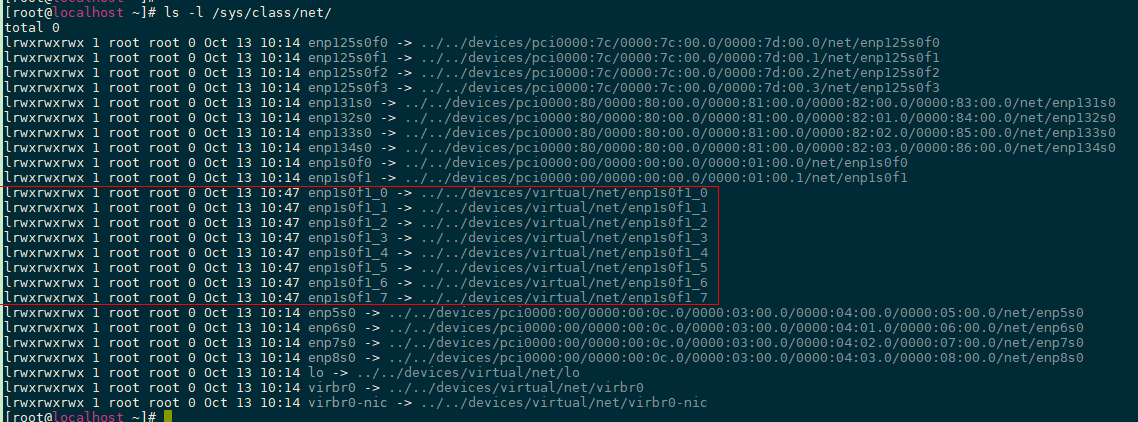
VF设备名由之前的enp1s0f$变更为enp1s0f1_$。
- 解绑VF。
- 绑定VF。
echo 0000:01:01.2 > /sys/bus/pci/drivers/mlx5_core/bind echo 0000:01:01.3 > /sys/bus/pci/drivers/mlx5_core/bind echo 0000:01:01.4 > /sys/bus/pci/drivers/mlx5_core/bind echo 0000:01:01.5 > /sys/bus/pci/drivers/mlx5_core/bind echo 0000:01:01.6 > /sys/bus/pci/drivers/mlx5_core/bind echo 0000:01:01.7 > /sys/bus/pci/drivers/mlx5_core/bind echo 0000:01:02.0 > /sys/bus/pci/drivers/mlx5_core/bind echo 0000:01:02.1 > /sys/bus/pci/drivers/mlx5_core/bind
demo

# uname -sr; tail -2/etc/lsb-release Linux 4.15.0-54-generic DISTRIB_CODENAME=bionic DISTRIB_DESCRIPTION="Ubuntu 18.04.2 LTS" VF and Mellanox eswitch/ASAP2 config ------------------------------------------------------------------------------------------ # mst start # mlxconfig -d /dev/mst/mt4121_pciconf0 query # mlxconfig -d /dev/mst/mt4121_pciconf0 set SRIOV_EN=1 # mlxconfig -d /dev/mst/mt4121_pciconf0 set NUM_OF_VFS=32 # sync; sync; sync; reboot # devlink dev show pci/0000:01:00.0 (*PF enp1s0f0 ) # echo 1 >/sys/class/net/enp1s0f0/device/sriov_numvfs # devlink dev show pci/0000:01:00.0 (*PF enp1s0f0 ) pci/0000:01:00.1 (*VF enp1s0f1 ) # echo 0000:01:00.1 >/sys/bus/pci/drivers/mlx5_core/unbind # devlink dev eswitch set pci/0000:01:00.0 mode switchdev # echo 0000:01:00.1 >/sys/bus/pci/drivers/mlx5_core/bind OpenvSwitch with eswitch/ASAP2 config ------------------------------------------------------------------------------------------ # apt install openvswitch-switch -y #/etc/init.d/openvswitch-switch start # ovs-vsctl set Open_vSwitch . other_config:hw-offload=true #/etc/init.d/openvswitch-switch restart # ovs-vsctl add-br ovs-sriov # ovs-vsctl add-port ovs-sriov enp1s0f0 # ovs-vsctl add-port ovs-sriov enp1s0f0_0 Host & VF interface config ------------------------------------------------------------------------------------------ # ifconfig enp1s0f0 up up (*PF) # ifconfig enp1s0f0_0 up up (*VF representor) # ip netns add TEST (*namespace TEST) # ip link set enp1s0f1 netns TEST # ip netns exec TEST ifconfig enp1s0f1 up up (*VF) # ip netns exec TEST dhcient enp1s0f1 (*VF assigned ip address 1.2.3.4) # ip netns exec TEST ping 8.8.8.8
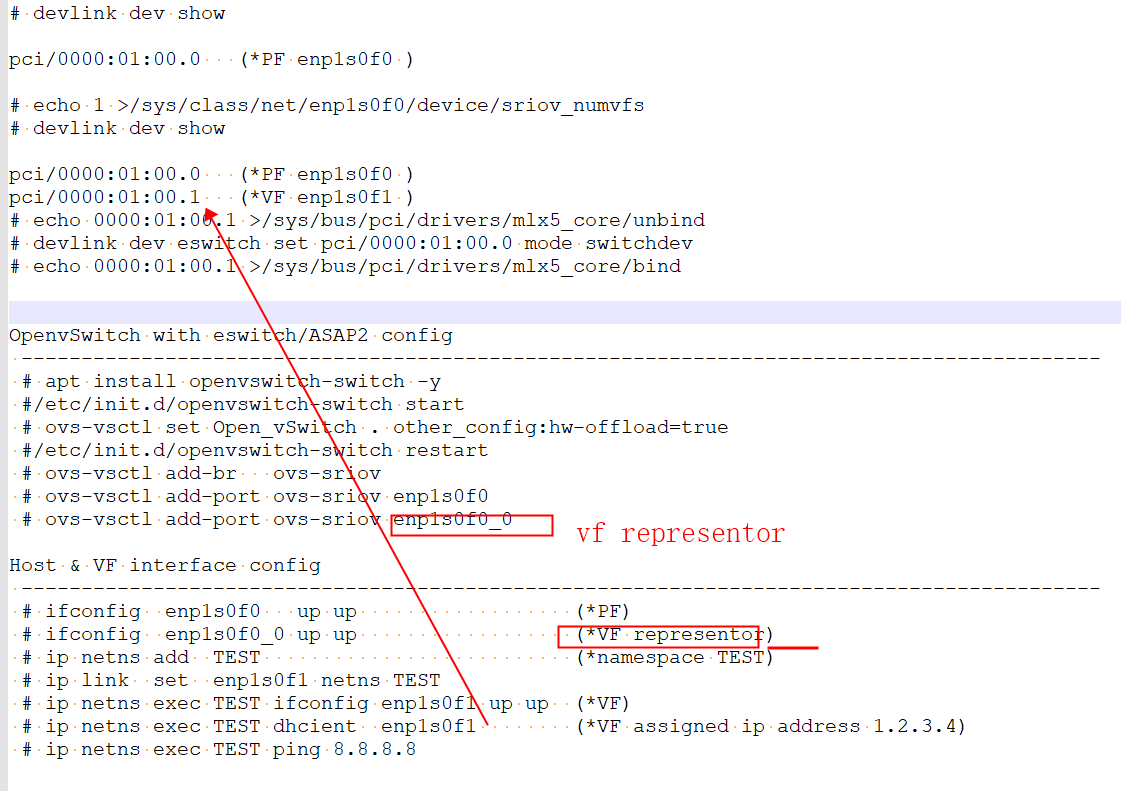
eswitch/ASAP2 network topology map ------------------------------------------------------------------------------------------ _gateway AA:AA:AA:AA:AA:AA | eswthch(PHY) ---------------------------------------> | | enp1s0f0: BB:BB:BB:BB:BB:BB (PF 100GbE) | eswtich/ASAP | | H/W offloaded enp1s0f0_0: CC:CC:CC:CC:CC:CC (VF representor) | w/OpenvSwitch | | enp1s0f1: XX:XX:XX:XX:XX:XX (VF/netns TEST) <--+
OpenvSwitch with eswitch/ASAP2 debug/monitor ------------------------------------------------------------------------------------------ # ovs-dpctl dump-flows type=offloaded in_port(2),eth(src=AA:AA:AA:AA:AA:AA,dst=XX:XX:XX:XX:XX:XX), ... actions:3 in_port(3),eth(src=XX:XX:XX:XX:XX:XX,dst=AA:AA:AA:AA:AA:AA), ... actions:2 # tshark -i enp1s0f0 icmp (PF) 1 0.000000000 1.2.3.4 → 8.8.8.8 ICMP 98 Echo (ping) request 2 0.001447344 8.8.8.8 → 1.2.3.4 ICMP 98 Echo (ping) reply (stop) # tshark -i enp1s0f0_0 icmp (VF representor) 1 0.000000000 1.2.3.4 → 8.8.8.8 ICMP 98 Echo (ping) request 2 0.019405322 8.8.8.8 → 1.2.3.4 ICMP 98 Echo (ping) reply (stop) # ovs-dpctl show system@ovs-system: port 1: ovs-sriov (internal) port 2: enp1s0f0 (*PF) port 3: enp1s0f0_0 (*pair to VF enp1s0f1)
# devlink dev eswitch show pci/0000:01:00.0 pci/0000:01:00.0: mode switchdev inline-mode none encap enable # update-pciids # lspci -tv -[0000:00]-+ +-01.0-[01]--+-00.0 Mellanox Technologies MT28800 Family [ConnectX-5 Ex] -00.1 Mellanox Technologies MT28800 Family [ConnectX-5 Ex Virtual Function] ------------------------------------------------- # ls/sys/devices/virtual/net/*/phys_port_name # ls/sys/devices/virtual/net/*/phys_switch_id # ls/sys/class/net/*/phys_port_name # ls/sys/class/net/*/phys_switch_id ------------------------------------------------- # ovs-vsctl -V ovs-vsctl (Open vSwitch) 2.9.2 DB Schema 7.15.1 # mlxlink -d/dev/mst/mt4121_pciconf0 -e Operational Info ---------------- State : Active Physical state : LinkUp Speed : 100GbE Width : 4x FEC : Standard RS-FEC - RS(528,514) Loopback Mode : No Loopback Auto Negotiation : ON Supported Info -------------- Enabled Link Speed : 0x48101041 (100G,50G,40G,25G,10G,1G) Supported Cable Speed : 0x48101165 (100G,56G,50G,40G,25G,20G,10G,1G) Troubleshooting Info -------------------- Status Opcode : 0 Group Opcode : N/A Recommendation : No issue was observed. EYE Opening Info ---------------- Physical Grade : 11340, 11581, 11340, 12244 Height Eye Opening [mV] : 260, 239, 198, 172 Phase Eye Opening [psec] : 10, 14, 17, 13 # mlxlink -d/dev/mst/mt4121_pciconf0 --show_ber_monitor : BER Monitor Info ---------------- BER Monitor State : Normal BER Monitor Type : Post FEC/No FEC BER monitoring # ethtool -i enp1s0f0 driver: mlx5_core version: 5.0-0 firmware-version: 16.25.1020 (MT_0000000009) expansion-rom-version: bus-info: 0000:01:00.0 Prerequisites For Eswitch #/ASAP2 * Linux Kernel >= 4.13-rc5 (Upstream Kernel) >= 3.10.0-860 (RedHat Based Distributions) * Mellanox NICs FW FW ConnectX-5: >= 16.21.0338 FW ConnectX-4 Lx: >= 14.21.0338 * iproute >= 4.11 * upstream openvswitch >= 2.8 * SR-IOV enabled
tc filter下发规则在内核的实现
规则下发首先需要获取设置规则的device以及对应的block,block主要用于共享,多个device可共享一个block,从而减少相应的规则数量。
我们通过block获取chain,默认是index 0的chain,如下图:
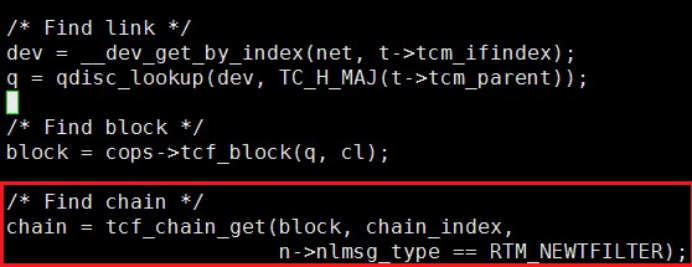
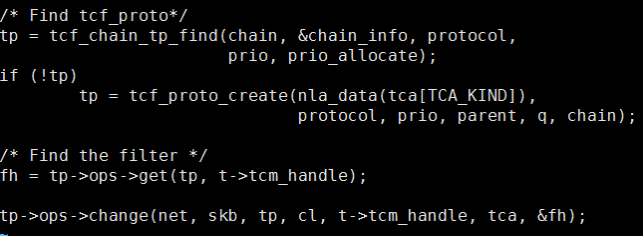
接下来通过chain以及protocol、prio(prio即pref)找到tcf_proto,即一个具体的的flower。我们发现不同protocol的prio也不同,所以ip、ip6、arp不能共用一个prio。根据filter handle获取真正的filter规则,然后调用tp->ops->change去做变更,在cls_flower 的fl_change中根据下发参数设置变更规则的match以及对应mask。
mellanox flow_indr_block_cb_register
drivers/net/ethernet/mellanox/mlx5/core/en_rep.c:837: err = __flow_indr_block_cb_register(netdev, rpriv, include/net/flow_offload.h:396:int __flow_indr_block_cb_register(struct net_device *dev, void *cb_priv, include/net/flow_offload.h:404:int flow_indr_block_cb_register(struct net_device *dev, void *cb_priv,
TC Flower硬件卸载的工作原理比较简单。当一条TC Flower规则被添加时,Linux TC会检查这条规则的挂载网卡是否支持并打开了NETIF_F_HW_TC标志位,并且是否实现了ndo_steup_tc(TC硬件卸载的挂载点)。如果都满足的话,这条TC Flower规则会传给网卡的ndo_steup_tc函数,进而下载到网卡内部[5]。
网卡的NETIF_F_HW_TC标志位可以通过ethtool来控制打开关闭:
# ethtool -K eth0 hw-tc-offload on
# ethtool -K eth0 hw-tc-offload off
同时,每条规则也可以通过标志位来控制是否进行硬件卸载。相应的标志位包括以下:
- TCA_CLS_FLAGS_SKIP_HW:只在软件(系统内核TC模块)添加规则,不在硬件添加。如果规则不能添加则报错。
- TCA_CLS_FLAGS_SKIP_SW:只在硬件(规则挂载的网卡)添加规则,不在软件添加。如果规则不能添加则报错。
- 默认(不带标志位):尝试同时在硬件和软件下载规则,如果规则不能在软件添加则报错。
通过TC命令查看规则,如果规则已经卸载到硬件了,可以看到 in_hw标志位。
ovs to kernel
ovs lib/tc.c
static int tc_get_tc_cls_policy(enum tc_offload_policy policy) { if (policy == TC_POLICY_SKIP_HW) { return TCA_CLS_FLAGS_SKIP_HW; } else if (policy == TC_POLICY_SKIP_SW) { return TCA_CLS_FLAGS_SKIP_SW; } return 0; }
const struct netdev_flow_api netdev_offload_tc = { .type = "linux_tc", .flow_flush = netdev_tc_flow_flush, .flow_dump_create = netdev_tc_flow_dump_create, .flow_dump_destroy = netdev_tc_flow_dump_destroy, .flow_dump_next = netdev_tc_flow_dump_next, .flow_put = netdev_tc_flow_put, .flow_get = netdev_tc_flow_get, .flow_del = netdev_tc_flow_del, .init_flow_api = netdev_tc_init_flow_api, };
netdev_tc_flow_put
tc_replace_flower(ifindex, prio, handle, &flower, block_id, hook);
netdev_tc_flow_put tc_replace_flower int tc_replace_flower(int ifindex, uint16_t prio, uint32_t handle, struct tc_flower *flower, uint32_t block_id, enum tc_qdisc_hook hook) { struct ofpbuf request; struct tcmsg *tcmsg; struct ofpbuf *reply; int error = 0; size_t basic_offset; uint16_t eth_type = (OVS_FORCE uint16_t) flower->key.eth_type; int index; index = block_id ? TCM_IFINDEX_MAGIC_BLOCK : ifindex; tcmsg = tc_make_request(index, RTM_NEWTFILTER, NLM_F_CREATE | NLM_F_ECHO, &request); tcmsg->tcm_parent = (hook == TC_EGRESS) ? TC_EGRESS_PARENT : (block_id ? : TC_INGRESS_PARENT); tcmsg->tcm_info = tc_make_handle(prio, eth_type); tcmsg->tcm_handle = handle; nl_msg_put_string(&request, TCA_KIND, "flower"); basic_offset = nl_msg_start_nested(&request, TCA_OPTIONS); { error = nl_msg_put_flower_options(&request, flower); if (error) { ofpbuf_uninit(&request); return error; } } nl_msg_end_nested(&request, basic_offset); error = tc_transact(&request, &reply); if (!error) { struct tcmsg *tc = ofpbuf_at_assert(reply, NLMSG_HDRLEN, sizeof *tc); flower->prio = tc_get_major(tc->tcm_info); flower->handle = tc->tcm_handle; ofpbuf_delete(reply); } return error; }

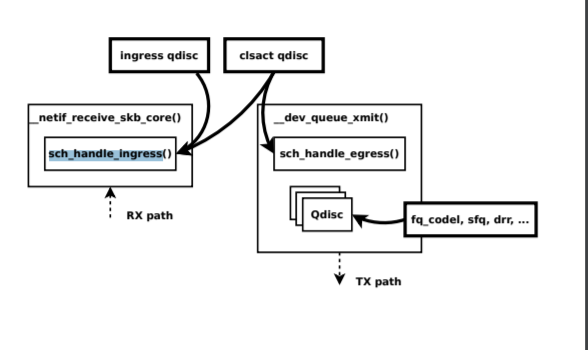
内核 tc filter
ingress hook:__netif_receive_skb_core() -> sch_handle_ingress()
egress hook:__dev_queue_xmit() -> sch_handle_egress()

Call Trace: [<ffffffff817c55bb>] tcindex_classify+0x88/0x9b [<ffffffff817a7f7d>] tc_classify_compat+0x3e/0x7b [<ffffffff817a7fdf>] tc_classify+0x25/0x9f [<ffffffff817b0e68>] htb_enqueue+0x55/0x27a [<ffffffff817b6c2e>] dsmark_enqueue+0x165/0x1a4 [<ffffffff81775642>] __dev_queue_xmit+0x35e/0x536 [<ffffffff8177582a>] dev_queue_xmit+0x10/0x12 [<ffffffff818f8ecd>] packet_sendmsg+0xb26/0xb9a [<ffffffff810b1507>] ? __lock_acquire+0x3ae/0xdf3 [<ffffffff8175cf08>] __sock_sendmsg_nosec+0x25/0x27 [<ffffffff8175d916>] sock_aio_write+0xd0/0xe7 [<ffffffff8117d6b8>] do_sync_write+0x59/0x78 [<ffffffff8117d84d>] vfs_write+0xb5/0x10a [<ffffffff8117d96a>] SyS_write+0x49/0x7f [<ffffffff8198e212>] system_call_fastpath+0x16/0x1b
sch_handle_ingress tcf_classify tp->classify(skb, tp, res) struct tcf_proto { /* Fast access part */ struct tcf_proto *next; void *root; int (*classify)(struct sk_buff*, struct tcf_proto*, struct tcf_result *); u32 protocol; /* All the rest */ u32 prio; u32 classid; struct Qdisc *q; void *data; struct tcf_proto_ops *ops; }; 773static struct tcf_proto_ops cls_fl_ops __read_mostly = { 774 .kind = "flower", 775 .classify = fl_classify, 776 .init = fl_init, 777 .destroy = fl_destroy, 778 .get = fl_get, 779 .change = fl_change, 780 .delete = fl_delete, 781 .walk = fl_walk, 782 .dump = fl_dump, 783 .owner = THIS_MODULE, 784};
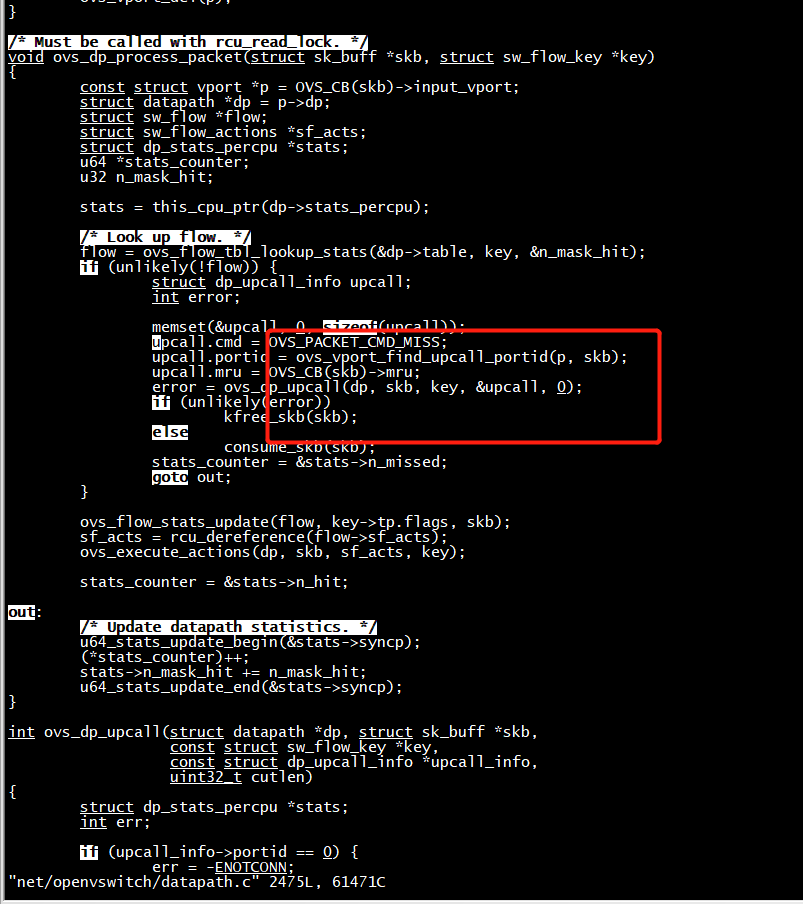
kernel OVS_PACKET_CMD_MISS
KERNEL
注册接收函数
netdev_create-->ovs_netdev_link-->netdev_rx_handler_register调用Linux kernel代码,将netdev_frame_hook函数注册到dev->rx_handler。
Linux kernel收包流程
net_rx_action-->process_backlog-->__netif_receive_skb-->__netif_receive_skb_core(skb->dev->rx_handler)调用实际函数netdev_frame_hook
netdev_frame_hook->port_receive->netdev_port_receive
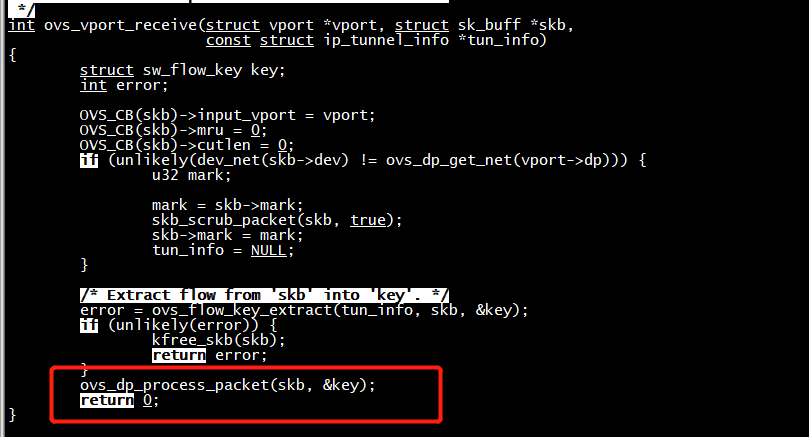
ovs_netdev_get_vport获取虚拟端口vport。ovs_vport_receive将报文传递到datapath。
ovs_vport_receive
ovs_flow_key_extract函数主要是从skb中提取key值。ovs_dp_process_packet主要是继续处理报文。
如果没有match到,就执行upcall通过netlink的方式给ovs-vswitchd发送OVS_PACKET_CMD_MISS命令。
UPCALL会包含整个packet,虽然不必要拷贝整个的packet给user space,可以做一些优化,但是由于只是拷贝first packet(比如TCP SYN),所以这种优化意义不大,而且有时候可能真的会用到整个packet。
ovs-vswitch一次只处理一个upcall,为了能够让每一个port产生的upcall都能够得到即使处理,datapath是采用的round robin这种方式来让每个port发送upcall。
UPCALL发送出去后,dadapath的处理就结束了。
void ovs_dp_process_packet(struct sk_buff *skb, struct sw_flow_key *key) { const struct vport *p = OVS_CB(skb)->input_vport; struct datapath *dp = p->dp; struct sw_flow *flow; struct sw_flow_actions *sf_acts; struct dp_stats_percpu *stats; u64 *stats_counter; u32 n_mask_hit; stats = this_cpu_ptr(dp->stats_percpu); /* Look up flow. */ flow = ovs_flow_tbl_lookup_stats(&dp->table, key, &n_mask_hit); if (unlikely(!flow)) { struct dp_upcall_info upcall; int error; memset(&upcall, 0, sizeof(upcall)); upcall.cmd = OVS_PACKET_CMD_MISS; upcall.portid = ovs_vport_find_upcall_portid(p, skb); upcall.mru = OVS_CB(skb)->mru; error = ovs_dp_upcall(dp, skb, key, &upcall, 0); if (unlikely(error)) kfree_skb(skb); else consume_skb(skb); stats_counter = &stats->n_missed; goto out; } ovs_flow_stats_update(flow, key->tp.flags, skb); sf_acts = rcu_dereference(flow->sf_acts); ovs_execute_actions(dp, skb, sf_acts, key); stats_counter = &stats->n_hit; out: /* Update datapath statistics. */ u64_stats_update_begin(&stats->syncp); (*stats_counter)++; stats->n_mask_hit += n_mask_hit; u64_stats_update_end(&stats->syncp); }
struct mlx5_core_dev *dev = pci_get_drvdata(pdev);
echo switchdev > /sys/kernel/debug/mlx5/${PCI_ADDR}/compat/mode,这是后面普遍的一种配置方法,它对应的代码路径如下:
esw_compat_fops-->write-->esw_compat_write-->write_u16-->mlx5_devlink_eswitch_mode_set-->esw_offloads_start-->mlx5_eswitch_enable_sriov
mlx5_remove_dev_by_protocol首先从MLX5_INTERFACE_PROTOCOL_IB协议中移除设备
mlx5_add_dev_by_protocol将设备添加到协议MLX5_INTERFACE_PROTOCOL_IB中
esw_offloads_init初始化offload相关的一些表和repsentor端口
esw_create_offloads_fdb_tables创建FDB表
esw_create_offloads_table创建转发表
esw_create_vport_rx_group创建接收组
esw_offloads_load_reps加载repsentor端口
esw_create_tsarvport的QoS管理
esw_enable_vport使能vport
int mlx5_devlink_eswitch_mode_set(struct devlink *devlink, u16 mode, struct netlink_ext_ack *extack) { struct mlx5_core_dev *dev = devlink_priv(devlink); u16 cur_mlx5_mode, mlx5_mode = 0; int err; err = mlx5_devlink_eswitch_check(devlink); if (err) return err; cur_mlx5_mode = dev->priv.eswitch->mode; if (esw_mode_from_devlink(mode, &mlx5_mode)) return -EINVAL; if (cur_mlx5_mode == mlx5_mode) return 0; if (mode == DEVLINK_ESWITCH_MODE_SWITCHDEV) return esw_offloads_start(dev->priv.eswitch, extack); else if (mode == DEVLINK_ESWITCH_MODE_LEGACY) return esw_offloads_stop(dev->priv.eswitch, extack); else return -EINVAL; }
static int esw_offloads_start(struct mlx5_eswitch *esw) { int err, err1, num_vfs = esw->dev->priv.sriov.num_vfs; if (esw->mode != SRIOV_LEGACY) { esw_warn(esw->dev, "Can't set offloads mode, SRIOV legacy not enabled "); return -EINVAL; } mlx5_eswitch_disable_sriov(esw); err = mlx5_eswitch_enable_sriov(esw, num_vfs, SRIOV_OFFLOADS); if (err) { esw_warn(esw->dev, "Failed setting eswitch to offloads, err %d ", err); err1 = mlx5_eswitch_enable_sriov(esw, num_vfs, SRIOV_LEGACY); if (err1) esw_warn(esw->dev, "Failed setting eswitch back to legacy, err %d ", err1); } return err; }
static int esw_offloads_start(struct mlx5_eswitch *esw) { int err, err1, num_vfs = esw->dev->priv.sriov.num_vfs; if (esw->mode != SRIOV_LEGACY) { esw_warn(esw->dev, "Can't set offloads mode, SRIOV legacy not enabled "); return -EINVAL; } mlx5_eswitch_disable_sriov(esw); err = mlx5_eswitch_enable_sriov(esw, num_vfs, SRIOV_OFFLOADS); //每个vf一represent if (err) { esw_warn(esw->dev, "Failed setting eswitch to offloads, err %d ", err); err1 = mlx5_eswitch_enable_sriov(esw, num_vfs, SRIOV_LEGACY); if (err1) esw_warn(esw->dev, "Failed setting eswitch back to legacy, err %d ", err1); } return err; }
int mlx5_eswitch_enable_sriov(struct mlx5_eswitch *esw, int nvfs, int mode) 1600{ 1618 1619 esw_info(esw->dev, "E-Switch enable SRIOV: nvfs(%d) mode (%d) ", nvfs, mode); 1620 esw->mode = mode; 1621 1622 if (mode == SRIOV_LEGACY) 1623 err = esw_create_legacy_fdb_table(esw, nvfs + 1); 1624 else 1625 err = esw_offloads_init(esw, nvfs + 1); 1626 if (err) 1627 goto abort; 1628 1629 err = esw_create_tsar(esw); 1630 if (err) 1631 esw_warn(esw->dev, "Failed to create eswitch TSAR"); 1632 1633 /* Don't enable vport events when in SRIOV_OFFLOADS mode, since: 1634 * 1. L2 table (MPFS) is programmed by PF/VF representors netdevs set_rx_mode 1635 * 2. FDB/Eswitch is programmed by user space tools 1636 */ 1637 enabled_events = (mode == SRIOV_LEGACY) ? SRIOV_VPORT_EVENTS : 0; 1638 for (i = 0; i <= nvfs; i++) 1639 esw_enable_vport(esw, i, enabled_events); 1640 1641 esw_info(esw->dev, "SRIOV enabled: active vports(%d) ", 1642 esw->enabled_vports); 1643 return 0; 1644 1645abort: 1646 esw->mode = SRIOV_NONE; 1647 return err; 1648}
vport + rep
struct mlx5_eswitch_rep rep 代表一个represnet port
mlx5_init_once mlx5_eswitch_init esw_offloads_init_reps int esw_offloads_init_reps(struct mlx5_eswitch *esw) { int total_vfs = MLX5_TOTAL_VPORTS(esw->dev); struct mlx5_core_dev *dev = esw->dev; struct mlx5_esw_offload *offloads; struct mlx5_eswitch_rep *rep; u8 hw_id[ETH_ALEN]; int vport; esw->offloads.vport_reps = kcalloc(total_vfs, sizeof(struct mlx5_eswitch_rep), GFP_KERNEL); if (!esw->offloads.vport_reps) return -ENOMEM; offloads = &esw->offloads; mlx5_query_nic_vport_mac_address(dev, 0, hw_id); for (vport = 0; vport < total_vfs; vport++) { rep = &offloads->vport_reps[vport]; rep->vport = vport; ether_addr_copy(rep->hw_id, hw_id); } offloads->vport_reps[0].vport = FDB_UPLINK_VPORT; return 0; } int mlx5_eswitch_init(struct mlx5_core_dev *dev) {
int total_vports = MLX5_TOTAL_VPORTS(dev);//每个vport对应个vport representor esw->vports = kcalloc(total_vports, sizeof(struct mlx5_vport), GFP_KERNEL); for (vport_num = 0; vport_num < total_vports; vport_num++) { struct mlx5_vport *vport = &esw->vports[vport_num]; vport->vport = vport_num; vport->info.link_state = MLX5_VPORT_ADMIN_STATE_AUTO; vport->dev = dev; INIT_WORK(&vport->vport_change_handler, esw_vport_change_handler); } } esw_offloads_init rep->load(esw, rep):(mlx5e_vport_rep_load) mlx5e_create_netdev(esw->dev, &mlx5e_rep_profile, rep) init(mlx5e_init_rep) mlx5e_build_rep_netdev
vport 设置switchdev_ops和ndo_setup_tc
vport 通过 mlx5e_build_rep_netdev 给vport设置 netdev->switchdev_ops = &mlx5e_rep_switchdev_ops;
.ndo_setup_tc = mlx5e_rep_ndo_setup_tc,
static void mlx5e_build_rep_netdev(struct net_device *netdev) { netdev->netdev_ops = &mlx5e_netdev_ops_rep; netdev->switchdev_ops = &mlx5e_rep_switchdev_ops; }
esw_offloads_init rep->load(esw, rep):(mlx5e_vport_rep_load) mlx5e_create_netdev(esw->dev, &mlx5e_rep_profile, rep) init(mlx5e_init_rep) mlx5e_build_rep_netdev
将represent vport register_netdev注册网络设备
mlx5e_vport_rep_load
register_netdev(netdev)
const struct net_device_ops mlx5e_netdev_ops = { .ndo_open = mlx5e_open, .ndo_stop = mlx5e_close, .ndo_start_xmit = mlx5e_xmit, .ndo_setup_tc = mlx5e_setup_tc, .ndo_select_queue = mlx5e_select_queue, .ndo_get_stats64 = mlx5e_get_stats, .ndo_set_rx_mode = mlx5e_set_rx_mode, .ndo_set_mac_address = mlx5e_set_mac, .ndo_vlan_rx_add_vid = mlx5e_vlan_rx_add_vid, .ndo_vlan_rx_kill_vid = mlx5e_vlan_rx_kill_vid, .ndo_set_features = mlx5e_set_features, .ndo_fix_features = mlx5e_fix_features, .ndo_change_mtu = mlx5e_change_nic_mtu, .ndo_do_ioctl = mlx5e_ioctl, .ndo_set_tx_maxrate = mlx5e_set_tx_maxrate, .ndo_udp_tunnel_add = mlx5e_add_vxlan_port, .ndo_udp_tunnel_del = mlx5e_del_vxlan_port, .ndo_features_check = mlx5e_features_check, .ndo_tx_timeout = mlx5e_tx_timeout, .ndo_bpf = mlx5e_xdp, .ndo_xdp_xmit = mlx5e_xdp_xmit, .ndo_xsk_wakeup = mlx5e_xsk_wakeup, #ifdef CONFIG_MLX5_EN_ARFS .ndo_rx_flow_steer = mlx5e_rx_flow_steer, #endif #ifdef CONFIG_MLX5_ESWITCH .ndo_bridge_setlink = mlx5e_bridge_setlink, .ndo_bridge_getlink = mlx5e_bridge_getlink, /* SRIOV E-Switch NDOs */ .ndo_set_vf_mac = mlx5e_set_vf_mac, .ndo_set_vf_vlan = mlx5e_set_vf_vlan, .ndo_set_vf_spoofchk = mlx5e_set_vf_spoofchk, .ndo_set_vf_trust = mlx5e_set_vf_trust, .ndo_set_vf_rate = mlx5e_set_vf_rate, .ndo_get_vf_config = mlx5e_get_vf_config, .ndo_set_vf_link_state = mlx5e_set_vf_link_state, .ndo_get_vf_stats = mlx5e_get_vf_stats, #endif }; static struct mlx5_interface mlx5e_interface = { .add = mlx5e_add, .remove = mlx5e_remove, .attach = mlx5e_attach, .detach = mlx5e_detach, .protocol = MLX5_INTERFACE_PROTOCOL_ETH, }; mlx5/core/en_main.c:5484: err = register_netdev(netdev); mlx5e_add register_netdev mlx5/core/en_rep.c:1914: err = register_netdev(netdev);
static const struct net_device_ops mlx5e_netdev_ops_rep = { .ndo_open = mlx5e_open, .ndo_stop = mlx5e_close, .ndo_start_xmit = mlx5e_xmit, .ndo_get_phys_port_name = mlx5e_rep_get_phys_port_name, .ndo_setup_tc = mlx5e_rep_ndo_setup_tc, .ndo_get_stats64 = mlx5e_get_stats, };
static void mlx5e_register_vport_rep(struct mlx5_core_dev *mdev) { struct mlx5_eswitch *esw = mdev->priv.eswitch; int total_vfs = MLX5_TOTAL_VPORTS(mdev); int vport; u8 mac[ETH_ALEN]; if (!MLX5_CAP_GEN(mdev, vport_group_manager)) return; mlx5_query_nic_vport_mac_address(mdev, 0, mac); for (vport = 1; vport < total_vfs; vport++) { struct mlx5_eswitch_rep rep; rep.load = mlx5e_vport_rep_load;//***** rep.unload = mlx5e_vport_rep_unload; rep.vport = vport; ether_addr_copy(rep.hw_id, mac); mlx5_eswitch_register_vport_rep(esw, vport, &rep); } } void mlx5_eswitch_register_vport_rep(struct mlx5_eswitch *esw, int vport_index, struct mlx5_eswitch_rep *__rep) { struct mlx5_esw_offload *offloads = &esw->offloads; struct mlx5_eswitch_rep *rep; rep = &offloads->vport_reps[vport_index]; memset(rep, 0, sizeof(*rep)); rep->load = __rep->load; rep->unload = __rep->unload; rep->vport = __rep->vport; rep->netdev = __rep->netdev; ether_addr_copy(rep->hw_id, __rep->hw_id); INIT_LIST_HEAD(&rep->vport_sqs_list); rep->valid = true; } static struct mlx5e_profile mlx5e_rep_profile = { .init = mlx5e_init_rep, .init_rx = mlx5e_init_rep_rx, .cleanup_rx = mlx5e_cleanup_rep_rx, .init_tx = mlx5e_init_rep_tx, .cleanup_tx = mlx5e_cleanup_nic_tx, .update_stats = mlx5e_rep_update_stats, .max_nch = mlx5e_get_rep_max_num_channels, .max_tc = 1, }; struct net_device *mlx5e_create_netdev(struct mlx5_core_dev *mdev, const struct mlx5e_profile *profile, void *ppriv) { int nch = profile->max_nch(mdev); struct net_device *netdev; struct mlx5e_priv *priv; netdev = alloc_etherdev_mqs(sizeof(struct mlx5e_priv), nch * profile->max_tc, nch); if (!netdev) { mlx5_core_err(mdev, "alloc_etherdev_mqs() failed "); return NULL; } profile->init(mdev, netdev, profile, ppriv); //调用 mlx5e_init_rep netif_carrier_off(netdev); priv = netdev_priv(netdev); priv->wq = create_singlethread_workqueue("mlx5e"); if (!priv->wq) goto err_cleanup_nic; return netdev; } mlx5e_init_rep mlx5e_build_rep_netdev static void mlx5e_init_rep(struct mlx5_core_dev *mdev, struct net_device *netdev, const struct mlx5e_profile *profile, void *ppriv) { mlx5e_build_rep_netdev_priv(mdev, netdev, profile, ppriv); mlx5e_build_rep_netdev(netdev); }
mlx5e_xmit
(gdb) b mlx5e_xmit Breakpoint 2 at 0xffffffffa0215f50: file drivers/net/ethernet/mellanox/mlx5/core/en_tx.c, line 371. (gdb) c Continuing. Thread 7 hit Breakpoint 2, mlx5e_xmit (skb=0xffff8801277e0200, dev=0xffff8801225c0000) at drivers/net/ethernet/mellanox/mlx5/core/en_tx.c:371 371 { (gdb) bt #0 mlx5e_xmit (skb=0xffff8801277e0200, dev=0xffff8801225c0000) at drivers/net/ethernet/mellanox/mlx5/core/en_tx.c:371 #1 0xffffffff81625652 in trace_net_dev_start_xmit (dev=<optimized out>, skb=<optimized out>) at ./include/trace/events/net.h:13 #2 xmit_one (more=<optimized out>, txq=<optimized out>, dev=<optimized out>, skb=<optimized out>) at net/core/dev.c:2982 #3 dev_hard_start_xmit (first=0xffff8801277e0200, dev=0xffff8801225c0000, txq=0xffff8801225c0000, ret=0xffffc900001b7a2c) at net/core/dev.c:2999 #4 0xffffffff816525a8 in qdisc_qlen (q=<optimized out>) at ./include/net/sch_generic.h:281 #5 sch_direct_xmit (skb=0xffff8801277e0200, q=0xffff880126f34800, dev=0xffff8801225c0000, txq=0xffff8801233f8000, root_lock=0xffff880126f3489c, validate=<optimized out>) at net/sched/sch_generic.c:187 #6 0xffffffff81625d9a in sch_handle_egress (dev=<optimized out>, ret=<optimized out>, skb=<optimized out>) at net/core/dev.c:3280 #7 __dev_queue_xmit (skb=0xffff8801277e0200, accel_priv=0xffff880126f34800) at net/core/dev.c:3429 #8 0xffffffff81625f70 in netif_receive_skb_internal (skb=0xffff8801277e0200) at net/core/dev.c:4465 #9 0xffffffff81672c17 in ip_finish_output2 (net=0xffff8801277e0200, sk=0xffff8801225c0000, skb=0xffffffff81625f70 <netif_receive_skb_internal+48>) at net/ipv4/ip_output.c:194 #10 0xffffffff81672ef7 in ip_finish_output_gso (mtu=<optimized out>, skb=<optimized out>, sk=<optimized out>, net=<optimized out>) at net/ipv4/ip_output.c:275 #11 ip_finish_output (net=0xffffffff81cd6e40 <init_net>, sk=0xffff8801265c0000, skb=<optimized out>) at net/ipv4/ip_output.c:312 #12 0xffffffff816739e2 in nf_hook_state_init (okfn=<optimized out>, net=<optimized out>, sk=<optimized out>, outdev=<optimized out>, indev=<optimized out>, pf=<optimized out>, hook=<optimized out>, p=<optimized out>) at ./include/linux/netfilter.h:121 #13 nf_hook (indev=<optimized out>, okfn=<optimized out>, outdev=<optimized out>, skb=<optimized out>, sk=<optimized out>, net=<optimized out>, hook=<optimized out>, pf=<optimized out>) at ./include/linux/netfilter.h:200 #14 NF_HOOK_COND (pf=<optimized out>, hook=<optimized out>, in=<optimized out>, okfn=<optimized out>, cond=<optimized out>, out=<optimized out>, skb=<optimized out>, sk=<optimized out>, net=<optimized out>) at ./include/linux/netfilter.h:235 #15 ip_output (net=0xffffffff81cd6e40 <init_net>, sk=0xffff8801265c0000, skb=0xffff8801277e0200) at net/ipv4/ip_output.c:405 #16 0xffffffff816730e5 in ip_build_and_send_pkt (skb=0xffffffff81cd6e40 <init_net>, sk=0x0 <irq_stack_union>, saddr=2686628480, daddr=1800748, opt=0xffff880126f3489c) at net/ipv4/ip_output.c:152 #17 0xffffffff81674389 in ip_push_pending_frames (sk=0xffffc900001b7c28, fl4=<optimized out>) at net/ipv4/ip_output.c:1512 #18 0xffffffff816743e3 in ip_make_skb (sk=0xffff8801277e0200, fl4=0xffff8801225c0000, getfrag=0xffffffffa022b280 <mlx5e_netdev_ops_basic>, from=0xffffc900001b7a2c, length=653478044, transhdrlen=1, ipc=0xffff8801118a0000, rtp=0x0 <irq_stack_union>, flags=1801776) at net/ipv4/ip_output.c:1546 #19 0xffffffff8169cda5 in sock_tx_timestamp (tx_flags=<optimized out>, tsflags=<optimized out>, sk=<optimized out>) at ./include/net/sock.h:2269 #20 raw_sendmsg (sk=0xffffffff81674389 <ip_push_pending_frames+41>, msg=<optimized out>, len=18446612137252749312) at net/ipv4/raw.c:647 #21 0xffffffff816acf5e in rps_record_sock_flow (hash=<optimized out>, table=<optimized out>) at ./include/linux/netdevice.h:665 #22 sock_rps_record_flow_hash (hash=<optimized out>) at ./include/net/sock.h:927 #23 sock_rps_record_flow (sk=<optimized out>) at ./include/net/sock.h:947 #24 inet_sendmsg (sock=<optimized out>, msg=0xffff8801225c0000, size=18446744072101212800) at net/ipv4/af_inet.c:755 #25 0xffffffff81605038 in sock_sendmsg_nosec (msg=<optimized out>, sock=<optimized out>) at net/socket.c:633 #26 sock_sendmsg (sock=0xffff88011622c000, msg=0xffffc900001b7e30) at net/socket.c:643 #27 0xffffffff8160559f in SYSC_sendto (fd=<optimized out>, buff=<optimized out>, len=<optimized out>, flags=0, addr=0x5ee3998500, addr_len=16) at net/socket.c:1736 #28 0xffffffff8160607e in SyS_sendto (fd=<optimized out>, buff=<optimized out>, len=<optimized out>, flags=<optimized out>, addr=<optimized out>, addr_len=<optimized out>) at net/socket.c:1704 #29 0xffffffff8175e6b7 in entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:236 #30 0x0000000000000401 in irq_stack_union () #31 0x00007ffcb6d011a4 in ?? () #32 0x00007ffcb6d00100 in ?? () #33 0x00007ffcb6d00c80 in ?? () #34 0x0000000000000401 in irq_stack_union () #35 0x0000000000000000 in ?? () (gdb) print *(struct net_device*) 0xffff8801225c0000 $1 = { name = "ens9", '�00' <repeats 11 times>, name_hlist = { next = 0x0 <irq_stack_union>, pprev = 0xffff88012950cfc0 }
OVS启动参数配置
- 开启OVS。
systemctl start openvswitch
- 使能卸载。
ovs-vsctl set Open_vSwitch . other_config:hw-offload=true ovs-vsctl set Open_vSwitch . other_config:tc-policy=verbose
- 重启OVS。
systemctl restart openvswitch

- 查看OVS数据。
ovs-vsctl list open_vswitch

ovs
struct netdev_flow_api netdev_offload_tc; const struct netdev_flow_api netdev_offload_tc = { .type = "linux_tc", .flow_flush = netdev_tc_flow_flush, .flow_dump_create = netdev_tc_flow_dump_create, .flow_dump_destroy = netdev_tc_flow_dump_destroy, .flow_dump_next = netdev_tc_flow_dump_next, .flow_put = netdev_tc_flow_put, .flow_get = netdev_tc_flow_get, .flow_del = netdev_tc_flow_del, .init_flow_api = netdev_tc_init_flow_api, };
static void netdev_initialize(void) OVS_EXCLUDED(netdev_mutex) { static struct ovsthread_once once = OVSTHREAD_ONCE_INITIALIZER; if (ovsthread_once_start(&once)) { fatal_signal_add_hook(restore_all_flags, NULL, NULL, true); netdev_vport_patch_register(); #ifdef __linux__ netdev_register_provider(&netdev_linux_class); netdev_register_provider(&netdev_internal_class); netdev_register_provider(&netdev_tap_class); netdev_vport_tunnel_register(); netdev_register_flow_api_provider(&netdev_offload_tc); #ifdef HAVE_AF_XDP netdev_register_provider(&netdev_afxdp_class); #endif #endif #if defined(__FreeBSD__) || defined(__NetBSD__) netdev_register_provider(&netdev_tap_class); netdev_register_provider(&netdev_bsd_class); #endif #ifdef _WIN32 netdev_register_provider(&netdev_windows_class); netdev_register_provider(&netdev_internal_class); netdev_vport_tunnel_register(); #endif ovsthread_once_done(&once); } }
配置OVS支持offload
配置OVS的流表offload功能的命令如下
ovs-vsctl set Open_vSwitch . Other_config:hw-offload=true
netdev_tc_init_flow_api
bridge_run(void) ┣━netdev_set_flow_api_enabled ┣━netdev_ports_flow_init ┣━netdev_init_flow_api ┣━netdev_assign_flow_api ┣━rfa->flow_api->init_flow_api(netdev) ┣━netdev_tc_init_flow_api
main-->bridge_run-->netdev_set_flow_api_enabled-->netdev_tc_init_flow_api主要是设置去创建或者删除一条TC规则,如果是添加则类似/sbin/tc qdisc add dev <devname> handle ffff: ingress,如果是删除则类似/sbin/tc qdisc del dev <devname> handle ffff: ingress。
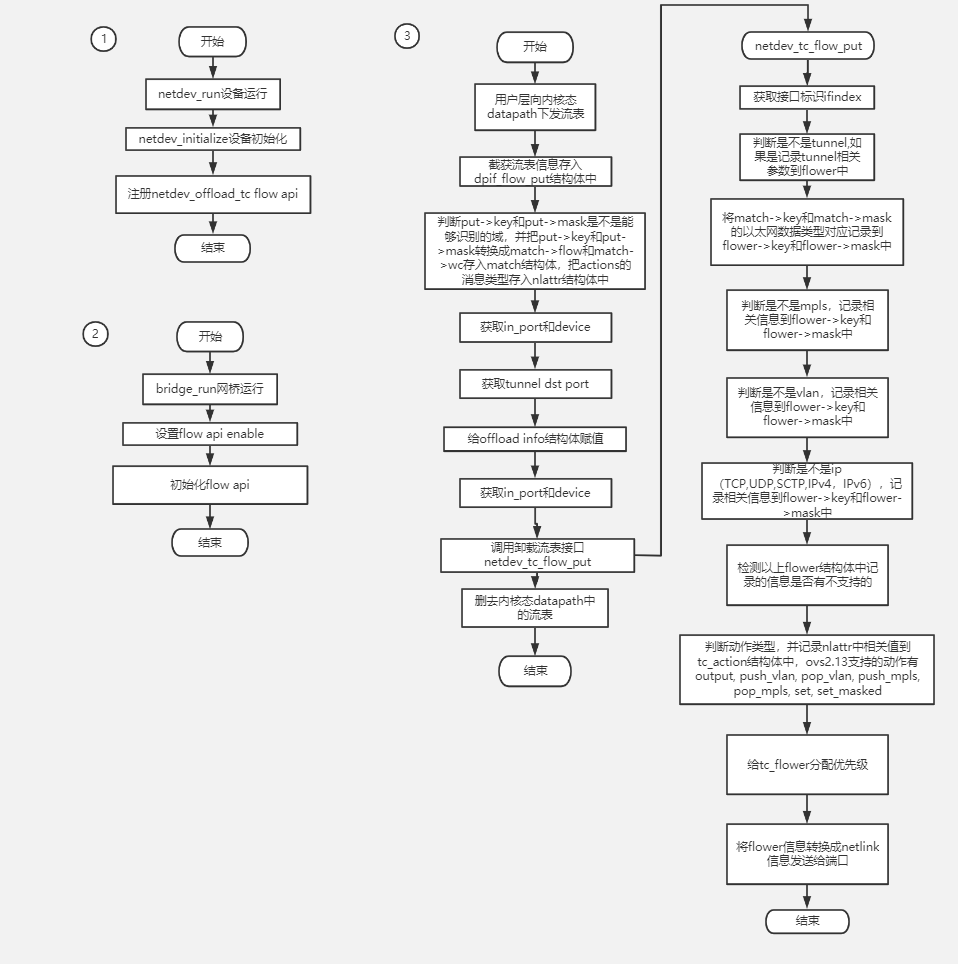
OVS offload流表下发
OVS相关部分
当报文不匹配的时候,会将报文上报,会调用udpif_upcall_handlerudpif_upcall_handler-->recv_upcalls-->handle_upcalls-->dpif_operate-->dpif_netlink_operate-->try_send_to_netdev-->parse_flow_put-->netdev_flow_put-->netdev_tc_flow_put
dp_netdev_flow_offload_put ┣━netdev_flow_put ┣━flow_api->flow_put ┣━netdev_tc_flow_put
┣━tc_replace_flower

dpif_netdev_operate ┣━dpif_netdev_flow_put ┣━flow_put_on_pmd swich分支case1: ┣━queue_netdev_flow_put switch分支 case2 :┣━dp_netdev_flow_add ┣━dpcls_insert ┣━queue_netdev_flow_put queue_netdev_flow_put ┣━dp_netdev_flow_offload_put ┣━netdev_flow_put ┣━flow_api->flow_put ┣━netdev_tc_flow_put
enum dpif_op_type { DPIF_OP_FLOW_PUT = 1, DPIF_OP_FLOW_DEL, DPIF_OP_EXECUTE, DPIF_OP_FLOW_GET, }; /* offload_type argument types to (*operate) interface */ enum dpif_offload_type { DPIF_OFFLOAD_AUTO, /* Offload if possible, fallback to software. */ DPIF_OFFLOAD_NEVER, /* Never offload to hardware. */ DPIF_OFFLOAD_ALWAYS, /* Always offload to hardware. */ }; handle_upcalls { put_op_init(&ops[n_ops++], ukey, DPIF_FP_CREATE); //设置op->dop.type = DPIF_OP_FLOW_PUT; dpif_operate(udpif->dpif, opsp, n_opsp, DPIF_OFFLOAD_AUTO); } dpif_operate(udpif->dpif, opsp, n_opsp, DPIF_OFFLOAD_AUTO); dpif->dpif_class->operate(dpif, ops, chunk, offload_type); dpif_netlink_operate try_send_to_netdev static void dpif_netlink_operate(struct dpif *dpif_, struct dpif_op **ops, size_t n_ops, enum dpif_offload_type offload_type) { struct dpif_op *op = ops[i++]; err = try_send_to_netdev(dpif, op); } static int try_send_to_netdev(struct dpif_netlink *dpif, struct dpif_op *op) { int err = EOPNOTSUPP; switch (op->type) { case DPIF_OP_FLOW_PUT: { struct dpif_flow_put *put = &op->flow_put; if (!put->ufid) { break; } err = parse_flow_put(dpif, put); log_flow_put_message(&dpif->dpif, &this_module, put, 0); break; } case DPIF_OP_FLOW_DEL: { struct dpif_flow_del *del = &op->flow_del; if (!del->ufid) { break; } err = netdev_ports_flow_del(dpif->dpif.dpif_class, del->ufid, del->stats); log_flow_del_message(&dpif->dpif, &this_module, del, 0); break; } case DPIF_OP_FLOW_GET: { struct dpif_flow_get *get = &op->flow_get; if (!op->flow_get.ufid) { break; } err = parse_flow_get(dpif, get); log_flow_get_message(&dpif->dpif, &this_module, get, 0); break; } case DPIF_OP_EXECUTE: default: break; } return err; }
kernel--添加内核tc filter 流控

用户侧发出RTM_NEWTFILTER套接口消息后,在内核侧对应的处理回调函数为tc_ctl_tfilter,该函数是在tc_filter_init中初始化的。
网卡驱动相关
前面ovs调用tc_replace_flower时候会触发kernel调用函数tc_ctl_tfilter,路径如下:
tc_ctl_tfilter-->fl_change-->fl_hw_replace_filter-->mlx5e_rep_ndo_setup_tc-->mlx5e_configure_flower-->mlx5e_tc_add_fdb_flow-->mlx5_eswitch_add_offloaded_rule
struct net_device_ops->ndo_rep_setup_tc
struct net_device_ops mlx5e_netdev_ops_rep = { .ndo_stop = mlx5e_rep_close, .ndo_start_xmit = mlx5e_xmit, .ndo_get_phys_port_name = mlx5e_rep_get_phys_port_name, - .ndo_setup_tc = mlx5e_rep_ndo_setup_tc, + .ndo_setup_tc = mlx5e_rep_setup_tc, .ndo_get_stats64 = mlx5e_rep_get_stats, .ndo_has_offload_stats = mlx5e_has_offload_stats, .ndo_get_offload_stats = mlx5e_get_offload_stats,
TC_SETUP_CLSFLOWER &ndo_setup_tc
190static int fl_hw_replace_filter(struct tcf_proto *tp, 191 struct flow_dissector *dissector, 192 struct fl_flow_key *mask, 193 struct fl_flow_key *key, 194 struct tcf_exts *actions, 195 unsigned long cookie, u32 flags) 196{ 197 struct net_device *dev = tp->q->dev_queue->dev; 198 struct tc_cls_flower_offload offload = {0}; 199 struct tc_to_netdev tc; 200 int err; 201 202 if (!tc_should_offload(dev, tp, flags)) 203 return tc_skip_sw(flags) ? -EINVAL : 0; 204 205 offload.command = TC_CLSFLOWER_REPLACE; 206 offload.cookie = cookie; 207 offload.dissector = dissector; 208 offload.mask = mask; 209 offload.key = key; 210 offload.exts = actions; 211 212 tc.type = TC_SETUP_CLSFLOWER; 213 tc.cls_flower = &offload; 214 215 err = dev->netdev_ops->ndo_setup_tc(dev, tp->q->handle, tp->protocol, &tc); 216 217 if (tc_skip_sw(flags)) 218 return err; 219 220 return 0; 221}
tc_replace_flower(struct tcf_id *id, struct tc_flower *flower)
{
struct ofpbuf request;
struct ofpbuf *reply;
int error = 0;
size_t basic_offset;
uint16_t eth_type = (OVS_FORCE uint16_t) flower->key.eth_type;
request_from_tcf_id(id, eth_type, RTM_NEWTFILTER,
NLM_F_CREATE | NLM_F_ECHO, &request);
nl_msg_put_string(&request, TCA_KIND, "flower");
basic_offset = nl_msg_start_nested(&request, TCA_OPTIONS);
{
error = nl_msg_put_flower_options(&request, flower);
if (error) {
ofpbuf_uninit(&request);
return error;
}
}
nl_msg_end_nested(&request, basic_offset);
error = tc_transact(&request, &reply);
if (!error) {
struct tcmsg *tc =
ofpbuf_at_assert(reply, NLMSG_HDRLEN, sizeof *tc);
id->prio = tc_get_major(tc->tcm_info);
id->handle = tc->tcm_handle;
ofpbuf_delete(reply);
}
return error;
}
tc_transact(struct ofpbuf *request, struct ofpbuf **replyp)
{
int error = nl_transact(NETLINK_ROUTE, request, replyp);
ofpbuf_uninit(request);
return error;
}
static int __init tc_filter_init(void)
{
rtnl_register(PF_UNSPEC, RTM_NEWTFILTER, tc_ctl_tfilter, NULL, NULL);
rtnl_register(PF_UNSPEC, RTM_DELTFILTER, tc_ctl_tfilter, NULL, NULL);
rtnl_register(PF_UNSPEC, RTM_GETTFILTER, tc_ctl_tfilter,
tc_dump_tfilter, NULL);
return 0;
}
l_change+0x27e/0x4830 net/sched/cls_flower.c:919
tc_ctl_tfilter+0xb54/0x1c01 net/sched/cls_api.c:738
tc_ctl_tfilter
--> change
static int tc_ctl_tfilter(struct sk_buff *skb, struct nlmsghdr *n)
{
err = tp->ops->change(net, skb, tp, cl, t->tcm_handle, tca, &fh,
n->nlmsg_flags & NLM_F_CREATE ? TCA_ACT_NOREPLACE : TCA_ACT_REPLACE);
}
static int fl_change(struct net *net, struct sk_buff *in_skb,
struct tcf_proto *tp, unsigned long base,
u32 handle, struct nlattr **tca,
void **arg, bool ovr, bool rtnl_held,
struct netlink_ext_ack *extack)
{
err = fl_hw_replace_filter(tp, fnew, extack);
}
static int fl_hw_replace_filter(struct tcf_proto *tp,
struct cls_fl_filter *f,
struct netlink_ext_ack *extack)
{
err = tc_setup_cb_call(block, TC_SETUP_CLSFLOWER, &cls_flower, skip_sw);
}
mlx5e_configure_flower parse_cls_flower解析ovs传递过来的流表中match的key信息 parse_tc_fdb_actions解析ovs传递过来的流表中action信息 mlx5e_tc_add_fdb_flow主要是讲match和action添加到fdb流表 后面先不看了,multipath的那些操作 mlx5e_tc_add_fdb_flow 如果action包含encap,那么调用mlx5e_attach_encap生成vxlan所需要的报文头信息 mlx5_eswitch_add_vlan_action添加vlan的action mlx5_eswitch_add_offloaded_rule添加offloaded规则 mlx5_eswitch_add_offloaded_rule-->mlx5_add_flow_rules-->_mlx5_add_flow_rules 主要是向firmware发送指令添加offload规则。
vport添加rule
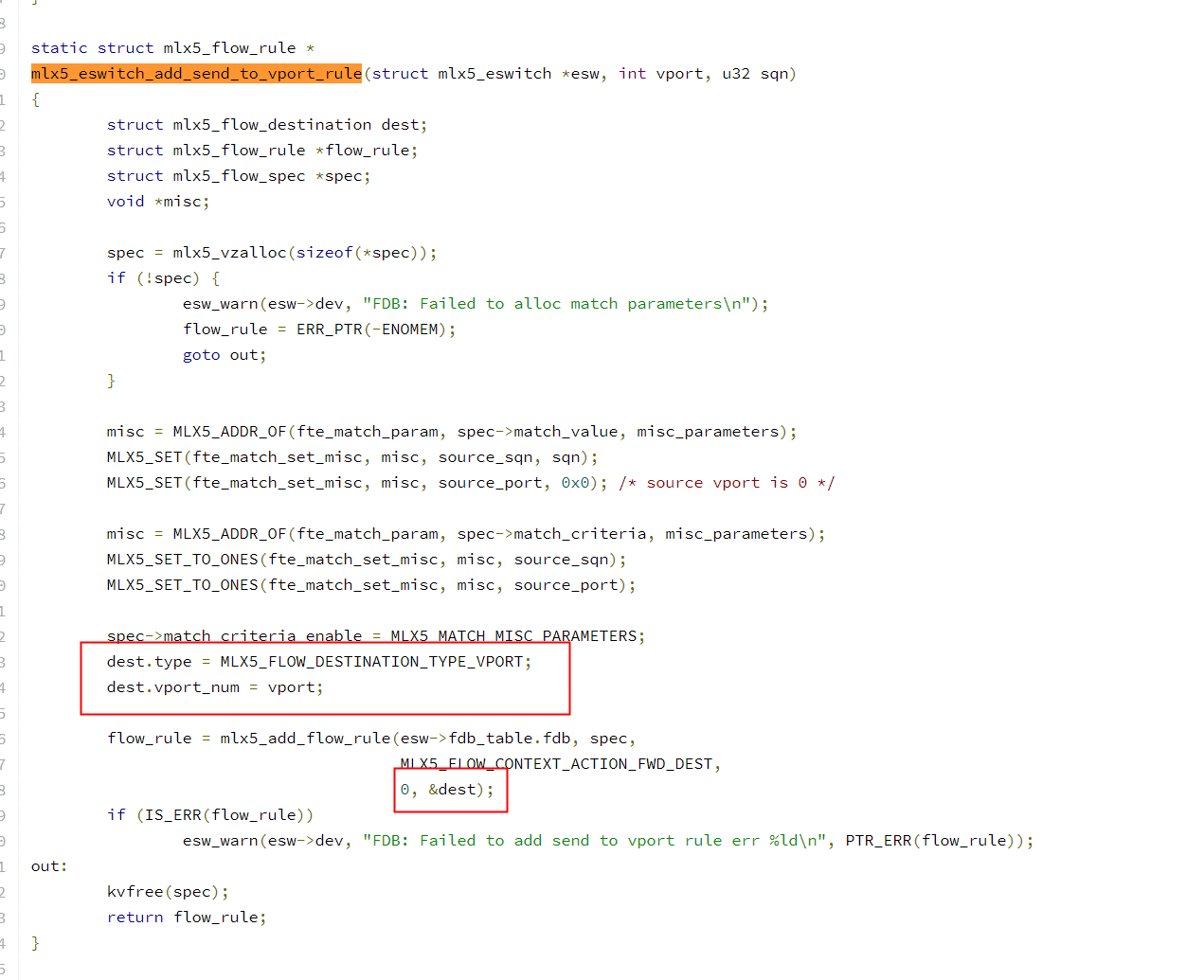
struct mlx5_flow_handle * mlx5_eswitch_add_fwd_rule(struct mlx5_eswitch *esw, struct mlx5_flow_spec *spec, struct mlx5_flow_attr *attr) { struct mlx5_flow_destination dest[MLX5_MAX_FLOW_FWD_VPORTS + 1] = {}; struct mlx5_flow_act flow_act = { .flags = FLOW_ACT_NO_APPEND, }; struct mlx5_esw_flow_attr *esw_attr = attr->esw_attr; struct mlx5_fs_chains *chains = esw_chains(esw); struct mlx5_vport_tbl_attr fwd_attr; struct mlx5_flow_table *fast_fdb; struct mlx5_flow_table *fwd_fdb; struct mlx5_flow_handle *rule; int i; fast_fdb = mlx5_chains_get_table(chains, attr->chain, attr->prio, 0); if (IS_ERR(fast_fdb)) { rule = ERR_CAST(fast_fdb); goto err_get_fast; } fwd_attr.chain = attr->chain; fwd_attr.prio = attr->prio; fwd_attr.vport = esw_attr->in_rep->vport; fwd_fdb = esw_vport_tbl_get(esw, &fwd_attr); if (IS_ERR(fwd_fdb)) { rule = ERR_CAST(fwd_fdb); goto err_get_fwd; } flow_act.action = MLX5_FLOW_CONTEXT_ACTION_FWD_DEST; for (i = 0; i < esw_attr->split_count; i++) { dest[i].type = MLX5_FLOW_DESTINATION_TYPE_VPORT; dest[i].vport.num = esw_attr->dests[i].rep->vport; dest[i].vport.vhca_id = MLX5_CAP_GEN(esw_attr->dests[i].mdev, vhca_id); if (MLX5_CAP_ESW(esw->dev, merged_eswitch)) dest[i].vport.flags |= MLX5_FLOW_DEST_VPORT_VHCA_ID; if (esw_attr->dests[i].flags & MLX5_ESW_DEST_ENCAP) { dest[i].vport.flags |= MLX5_FLOW_DEST_VPORT_REFORMAT_ID; dest[i].vport.pkt_reformat = esw_attr->dests[i].pkt_reformat; } } dest[i].type = MLX5_FLOW_DESTINATION_TYPE_FLOW_TABLE; dest[i].ft = fwd_fdb; i++; mlx5_eswitch_set_rule_source_port(esw, spec, esw_attr); flow_act.flags |= FLOW_ACT_IGNORE_FLOW_LEVEL; rule = mlx5_add_flow_rules(fast_fdb, spec, &flow_act, dest, i); return rule; } static void mlx5_eswitch_set_rule_source_port(struct mlx5_eswitch *esw, struct mlx5_flow_spec *spec, struct mlx5_esw_flow_attr *attr) { void *misc2; void *misc; /* Use metadata matching because vport is not represented by single * VHCA in dual-port RoCE mode, and matching on source vport may fail. */ if (mlx5_eswitch_vport_match_metadata_enabled(esw)) { misc2 = MLX5_ADDR_OF(fte_match_param, spec->match_value, misc_parameters_2); MLX5_SET(fte_match_set_misc2, misc2, metadata_reg_c_0, mlx5_eswitch_get_vport_metadata_for_match(attr->in_mdev->priv.eswitch, attr->in_rep->vport)); misc2 = MLX5_ADDR_OF(fte_match_param, spec->match_criteria, misc_parameters_2); MLX5_SET_TO_ONES(fte_match_set_misc2, misc2, metadata_reg_c_0); spec->match_criteria_enable |= MLX5_MATCH_MISC_PARAMETERS_2; misc = MLX5_ADDR_OF(fte_match_param, spec->match_criteria, misc_parameters); if (memchr_inv(misc, 0, MLX5_ST_SZ_BYTES(fte_match_set_misc))) spec->match_criteria_enable |= MLX5_MATCH_MISC_PARAMETERS; } else { misc = MLX5_ADDR_OF(fte_match_param, spec->match_value, misc_parameters); MLX5_SET(fte_match_set_misc, misc, source_port, attr->in_rep->vport); if (MLX5_CAP_ESW(esw->dev, merged_eswitch)) MLX5_SET(fte_match_set_misc, misc, source_eswitch_owner_vhca_id, MLX5_CAP_GEN(attr->in_mdev, vhca_id)); misc = MLX5_ADDR_OF(fte_match_param, spec->match_criteria, misc_parameters); MLX5_SET_TO_ONES(fte_match_set_misc, misc, source_port); if (MLX5_CAP_ESW(esw->dev, merged_eswitch)) MLX5_SET_TO_ONES(fte_match_set_misc, misc, source_eswitch_owner_vhca_id); spec->match_criteria_enable |= MLX5_MATCH_MISC_PARAMETERS; } if (MLX5_CAP_ESW_FLOWTABLE(esw->dev, flow_source) && attr->in_rep->vport == MLX5_VPORT_UPLINK) spec->flow_context.flow_source = MLX5_FLOW_CONTEXT_FLOW_SOURCE_UPLINK; }
parse_tc_fdb_actions
老版本 static int parse_tc_fdb_actions(struct mlx5e_priv *priv, struct tcf_exts *exts, struct mlx5e_tc_flow_parse_attr *parse_attr, struct mlx5e_tc_flow *flow, struct netlink_ext_ack *extack) 新版本 static int parse_tc_fdb_actions(struct mlx5e_priv *priv, struct flow_action *flow_action, struct mlx5e_tc_flow *flow, struct flow_action_entry struct netlink_ext_ack *extack) int tc_setup_flow_action(struct flow_action *flow_action, const struct tcf_exts *exts, bool rtnl_held)
mlx5e_add_nic_flow(struct mlx5e_priv *priv, struct flow_cls_offload *f, unsigned long flow_flags, struct net_device *filter_dev, struct mlx5e_tc_flow **__flow) { flow_flags |= BIT(MLX5E_TC_FLOW_FLAG_NIC); attr_size = sizeof(struct mlx5_nic_flow_attr); err = mlx5e_alloc_flow(priv, attr_size, f, flow_flags, &parse_attr, &flow); parse_attr->filter_dev = filter_dev; mlx5e_flow_attr_init(flow->attr, parse_attr, f); err = parse_cls_flower(flow->priv, flow, &parse_attr->spec, f, filter_dev); err = mlx5_tc_ct_match_add(get_ct_priv(priv), &parse_attr->spec, f, &flow->attr->ct_attr, extack); err = parse_tc_nic_actions(priv, &rule->action, parse_attr, flow, extack);
flow->rule = mlx5e_tc_add_nic_flow(priv, parse_attr, flow);
}
mlx5e_tc_add_nic_flow
--> mlx5_add_flow_rules
mlx5e_tc_tunnel vxlan_tunnel
struct mlx5e_tc_tunnel vxlan_tunnel = { .tunnel_type = MLX5E_TC_TUNNEL_TYPE_VXLAN, .match_level = MLX5_MATCH_L4, .can_offload = mlx5e_tc_tun_can_offload_vxlan, .calc_hlen = mlx5e_tc_tun_calc_hlen_vxlan, .init_encap_attr = mlx5e_tc_tun_init_encap_attr_vxlan, .generate_ip_tun_hdr = mlx5e_gen_ip_tunnel_header_vxlan, .parse_udp_ports = mlx5e_tc_tun_parse_udp_ports_vxlan, .parse_tunnel = mlx5e_tc_tun_parse_vxlan, };
static bool mlx5e_tc_tun_can_offload_vxlan(struct mlx5e_priv *priv) { return !!MLX5_CAP_ESW(priv->mdev, vxlan_encap_decap); }
bool mlx5e_tc_tun_device_to_offload(struct mlx5e_priv *priv, struct net_device *netdev) { struct mlx5e_tc_tunnel *tunnel = mlx5e_get_tc_tun(netdev); if (tunnel && tunnel->can_offload(priv)) return true; else return false; } static int mlx5e_rep_indr_setup_block(struct net_device *netdev, struct Qdisc *sch, struct mlx5e_rep_priv *rpriv, struct flow_block_offload *f, flow_setup_cb_t *setup_cb, void *data, void (*cleanup)(struct flow_block_cb *block_cb)) { struct mlx5e_priv *priv = netdev_priv(rpriv->netdev); struct mlx5e_rep_indr_block_priv *indr_priv; struct flow_block_cb *block_cb; if (!mlx5e_tc_tun_device_to_offload(priv, netdev) && !(is_vlan_dev(netdev) && vlan_dev_real_dev(netdev) == rpriv->netdev)) return -EOPNOTSUPP; if (f->binder_type != FLOW_BLOCK_BINDER_TYPE_CLSACT_INGRESS) return -EOPNOTSUPP; f->unlocked_driver_cb = true; f->driver_block_list = &mlx5e_block_cb_list; switch (f->command) { case FLOW_BLOCK_BIND: indr_priv = mlx5e_rep_indr_block_priv_lookup(rpriv, netdev); if (indr_priv) return -EEXIST; indr_priv = kmalloc(sizeof(*indr_priv), GFP_KERNEL); if (!indr_priv) return -ENOMEM; indr_priv->netdev = netdev; indr_priv->rpriv = rpriv; list_add(&indr_priv->list, &rpriv->uplink_priv.tc_indr_block_priv_list); block_cb = flow_indr_block_cb_alloc(setup_cb, indr_priv, indr_priv, mlx5e_rep_indr_block_unbind, f, netdev, sch, data, rpriv, cleanup); if (IS_ERR(block_cb)) { list_del(&indr_priv->list); kfree(indr_priv); return PTR_ERR(block_cb); } flow_block_cb_add(block_cb, f); list_add_tail(&block_cb->driver_list, &mlx5e_block_cb_list); return 0; case FLOW_BLOCK_UNBIND: indr_priv = mlx5e_rep_indr_block_priv_lookup(rpriv, netdev); if (!indr_priv) return -ENOENT; block_cb = flow_block_cb_lookup(f->block, setup_cb, indr_priv); if (!block_cb) return -ENOENT; flow_indr_block_cb_remove(block_cb, f); list_del(&block_cb->driver_list); return 0; default: return -EOPNOTSUPP; } return 0; } static int mlx5e_rep_indr_setup_cb(struct net_device *netdev, struct Qdisc *sch, void *cb_priv, enum tc_setup_type type, void *type_data, void *data, void (*cleanup)(struct flow_block_cb *block_cb)) { switch (type) { case TC_SETUP_BLOCK: return mlx5e_rep_indr_setup_block(netdev, sch, cb_priv, type_data, mlx5e_rep_indr_setup_tc_cb, data, cleanup); case TC_SETUP_FT: return mlx5e_rep_indr_setup_block(netdev, sch, cb_priv, type_data, mlx5e_rep_indr_setup_ft_cb, data, cleanup); default: return -EOPNOTSUPP; } } int mlx5e_rep_tc_netdevice_event_register(struct mlx5e_rep_priv *rpriv) { struct mlx5_rep_uplink_priv *uplink_priv = &rpriv->uplink_priv; /* init indirect block notifications */ INIT_LIST_HEAD(&uplink_priv->tc_indr_block_priv_list); return flow_indr_dev_register(mlx5e_rep_indr_setup_cb, rpriv); } int flow_indr_dev_register(flow_indr_block_bind_cb_t *cb, void *cb_priv) { struct flow_indr_dev *indr_dev; mutex_lock(&flow_indr_block_lock); list_for_each_entry(indr_dev, &flow_block_indr_dev_list, list) { if (indr_dev->cb == cb && indr_dev->cb_priv == cb_priv) { refcount_inc(&indr_dev->refcnt); mutex_unlock(&flow_indr_block_lock); return 0; } } indr_dev = flow_indr_dev_alloc(cb, cb_priv); if (!indr_dev) { mutex_unlock(&flow_indr_block_lock); return -ENOMEM; } list_add(&indr_dev->list, &flow_block_indr_dev_list); mutex_unlock(&flow_indr_block_lock); return 0; } static LIST_HEAD(flow_block_indr_dev_list); flow_block_indr_dev_list static LIST_HEAD(flow_block_indr_list);
Open vSwitch tunneling

netdev_switch_fib_ipv4_add
int netdev_switch_fib_ipv4_add(u32 dst, int dst_len, struct fib_info *fi, u8 tos, u8 type, u32 nlflags, u32 tb_id) { struct net_device *dev; const struct swdev_ops *ops; int err = 0; /* Don't offload route if using custom ip rules or if * IPv4 FIB offloading has been disabled completely. */ #ifdef CONFIG_IP_MULTIPLE_TABLES if (fi->fib_net->ipv4.fib_has_custom_rules) return 0; #endif if (fi->fib_net->ipv4.fib_offload_disabled) return 0; dev = netdev_switch_get_dev_by_nhs(fi); if (!dev) return 0; ops = dev->swdev_ops; if (ops->swdev_fib_ipv4_add) { err = ops->swdev_fib_ipv4_add(dev, htonl(dst), dst_len, fi, tos, type, nlflags, tb_id); if (!err) fi->fib_flags |= RTNH_F_OFFLOAD; } return err; }
switchdev_ops swdev_ops
https://github.com/arter97/android_kernel_realme_sdm710/blob/67cd641f7c4039d0d37d57eccf835ffccf2447f2/drivers/net/ethernet/mellanox/mlx5/core/en_rep.c static int mlxsw_sp_setup_tc_block(struct mlxsw_sp_port *mlxsw_sp_port, struct flow_block_offload *f) { switch (f->binder_type) { case FLOW_BLOCK_BINDER_TYPE_CLSACT_INGRESS: return mlxsw_sp_setup_tc_block_clsact(mlxsw_sp_port, f, true); case FLOW_BLOCK_BINDER_TYPE_CLSACT_EGRESS: return mlxsw_sp_setup_tc_block_clsact(mlxsw_sp_port, f, false); case FLOW_BLOCK_BINDER_TYPE_RED_EARLY_DROP: return mlxsw_sp_setup_tc_block_qevent_early_drop(mlxsw_sp_port, f); default: return -EOPNOTSUPP; } } static int mlxsw_sp_setup_tc(struct net_device *dev, enum tc_setup_type type, void *type_data) { struct mlxsw_sp_port *mlxsw_sp_port = netdev_priv(dev); switch (type) { case TC_SETUP_BLOCK: return mlxsw_sp_setup_tc_block(mlxsw_sp_port, type_data); case TC_SETUP_QDISC_RED: return mlxsw_sp_setup_tc_red(mlxsw_sp_port, type_data); case TC_SETUP_QDISC_PRIO: return mlxsw_sp_setup_tc_prio(mlxsw_sp_port, type_data); case TC_SETUP_QDISC_ETS: return mlxsw_sp_setup_tc_ets(mlxsw_sp_port, type_data); case TC_SETUP_QDISC_TBF: return mlxsw_sp_setup_tc_tbf(mlxsw_sp_port, type_data); case TC_SETUP_QDISC_FIFO: return mlxsw_sp_setup_tc_fifo(mlxsw_sp_port, type_data); default: return -EOPNOTSUPP; } } static const struct net_device_ops mlxsw_sp_port_netdev_ops = { .ndo_open = mlxsw_sp_port_open, .ndo_stop = mlxsw_sp_port_stop, .ndo_start_xmit = mlxsw_sp_port_xmit, .ndo_setup_tc = mlxsw_sp_setup_tc, .ndo_set_rx_mode = mlxsw_sp_set_rx_mode, .ndo_set_mac_address = mlxsw_sp_port_set_mac_address, .ndo_change_mtu = mlxsw_sp_port_change_mtu, .ndo_get_stats64 = mlxsw_sp_port_get_stats64, .ndo_has_offload_stats = mlxsw_sp_port_has_offload_stats, .ndo_get_offload_stats = mlxsw_sp_port_get_offload_stats, .ndo_vlan_rx_add_vid = mlxsw_sp_port_add_vid, .ndo_vlan_rx_kill_vid = mlxsw_sp_port_kill_vid, .ndo_set_features = mlxsw_sp_set_features, .ndo_get_devlink_port = mlxsw_sp_port_get_devlink_port, .ndo_do_ioctl = mlxsw_sp_port_ioctl, }; static void mlx5e_build_rep_netdev(struct net_device *netdev) { netdev->netdev_ops = &mlx5e_netdev_ops_rep; netdev->watchdog_timeo = 15 * HZ; netdev->ethtool_ops = &mlx5e_rep_ethtool_ops; #ifdef CONFIG_NET_SWITCHDEV netdev->switchdev_ops = &mlx5e_rep_switchdev_ops; #endif netdev->features |= NETIF_F_VLAN_CHALLENGED | NETIF_F_HW_TC; netdev->hw_features |= NETIF_F_HW_TC; eth_hw_addr_random(netdev); } struct net_device { 1564 const struct net_device_ops *netdev_ops; 1565 const struct ethtool_ops *ethtool_ops; 1566#ifdef CONFIG_NET_SWITCHDEV //新版本没有switchdev_ops 1567 const struct swdev_ops *swdev_ops; 1568#endif 1569 1 1754}; struct swdev_ops { int (*swdev_parent_id_get)(struct net_device *dev, struct netdev_phys_item_id *psid); int (*swdev_port_stp_update)(struct net_device *dev, u8 state); int (*swdev_fib_ipv4_add)(struct net_device *dev, __be32 dst, int dst_len, struct fib_info *fi, u8 tos, u8 type, u32 nlflags, u32 tb_id); int (*swdev_fib_ipv4_del)(struct net_device *dev, __be32 dst, int dst_len, struct fib_info *fi, u8 tos, u8 type, u32 tb_id); }; struct switchdev_ops { int (*switchdev_port_attr_get)(struct net_device *dev, struct switchdev_attr *attr); int (*switchdev_port_attr_set)(struct net_device *dev, const struct switchdev_attr *attr, struct switchdev_trans *trans); int (*switchdev_port_obj_add)(struct net_device *dev, const struct switchdev_obj *obj, struct switchdev_trans *trans); int (*switchdev_port_obj_del)(struct net_device *dev, const struct switchdev_obj *obj); int (*switchdev_port_obj_dump)(struct net_device *dev, struct switchdev_obj *obj, switchdev_obj_dump_cb_t *cb); };
netdev->switchdev_ops = &mlx5e_rep_switchdev_ops
static const struct switchdev_ops mlx5e_rep_switchdev_ops = { .switchdev_port_attr_get = mlx5e_attr_get, };
int mlx5_eswitch_init(struct mlx5_core_dev *dev) { int total_vports = MLX5_TOTAL_VPORTS(dev); struct mlx5_eswitch *esw; esw = kzalloc(sizeof(*esw), GFP_KERNEL); if (!esw) return -ENOMEM; esw->dev = dev; esw->work_queue = create_singlethread_workqueue("mlx5_esw_wq"); if (!esw->work_queue) { err = -ENOMEM; goto abort; } esw->vports = kcalloc(total_vports, sizeof(struct mlx5_vport), GFP_KERNEL); if (!esw->vports) { err = -ENOMEM; goto abort; } err = esw_offloads_init_reps(esw); dev->priv.eswitch = esw;
新版fl_hw_replace_filter
tc_ctl_tfilter-->fl_change-->fl_hw_replace_filter-->tc_setup_flow_action static int fl_hw_replace_filter(struct tcf_proto *tp, struct cls_fl_filter *f, struct netlink_ext_ack *extack) { struct tc_cls_flower_offload cls_flower = {}; struct tcf_block *block = tp->chain->block; bool skip_sw = tc_skip_sw(f->flags); int err; tc_setup_flow_action err = tc_setup_cb_call(block, TC_SETUP_CLSFLOWER, &cls_flower, skip_sw); kfree(cls_flower.rule); if (err < 0) { fl_hw_destroy_filter(tp, f, NULL); return err; } else if (err > 0) { f->in_hw_count = err; tcf_block_offload_inc(block, &f->flags); } if (skip_sw && !(f->flags & TCA_CLS_FLAGS_IN_HW)) return -EINVAL; return 0; } int tc_setup_cb_call(struct tcf_block *block, enum tc_setup_type type, void *type_data, bool err_stop, bool rtnl_held) { ok_count = __tc_setup_cb_call(block, type, type_data, err_stop); } __tc_setup_cb_call(struct tcf_block *block, enum tc_setup_type type, void *type_data, bool err_stop) { struct flow_block_cb *block_cb; int ok_count = 0; int err; list_for_each_entry(block_cb, &block->flow_block.cb_list, list) { err = block_cb->cb(type, type_data, block_cb->cb_priv); if (err) { if (err_stop) return err; } else { ok_count++; } } return ok_count; } mlx5e_setup_tc-->flow_block_cb_setup_simple #ifdef CONFIG_MLX5_ESWITCH static int mlx5e_setup_tc_cls_flower(struct mlx5e_priv *priv, struct flow_cls_offload *cls_flower, unsigned long flags) { switch (cls_flower->command) { case FLOW_CLS_REPLACE: return mlx5e_configure_flower(priv->netdev, priv, cls_flower, flags); case FLOW_CLS_DESTROY: return mlx5e_delete_flower(priv->netdev, priv, cls_flower, flags); case FLOW_CLS_STATS: return mlx5e_stats_flower(priv->netdev, priv, cls_flower, flags); default: return -EOPNOTSUPP; } } static int mlx5e_setup_tc_block_cb(enum tc_setup_type type, void *type_data, void *cb_priv) { unsigned long flags = MLX5_TC_FLAG(INGRESS) | MLX5_TC_FLAG(NIC_OFFLOAD); struct mlx5e_priv *priv = cb_priv; switch (type) { case TC_SETUP_CLSFLOWER: return mlx5e_setup_tc_cls_flower(priv, type_data, flags); default: return -EOPNOTSUPP; } } #endif static int mlx5e_setup_tc(struct net_device *dev, enum tc_setup_type type, void *type_data) { struct mlx5e_priv *priv = netdev_priv(dev); switch (type) { #ifdef CONFIG_MLX5_ESWITCH case TC_SETUP_BLOCK: { struct flow_block_offload *f = type_data; f->unlocked_driver_cb = true; return flow_block_cb_setup_simple(type_data, &mlx5e_block_cb_list, mlx5e_setup_tc_block_cb, priv, priv, true); } #endif case TC_SETUP_QDISC_MQPRIO: return mlx5e_setup_tc_mqprio(priv, type_data); default: return -EOPNOTSUPP; } }
dump flows
一般是两种命令可以展示datapath的流表,他们的区别主要是能不能dump别的datapath,主要实现都是一致的,所以我们只看一个相关的代码,因为个人认为ovs-appctl命令更好一些,所以就看这个的代码。
ovs-dpctl dump-flows [type=offloaded/ovs]
ovs-appctl dpctl/dump-flows [type=offloaded/ovs]
命令相关的代码就不看了,因为ovs-appctl调用的命令都需要在ovs-vswitchd中通过函数unixctl_command_register进行注册。我们这里直接查看注册的dpctl相关的命令。
代码路径如下,文件起始于ovs-vswitchd.c
main-->bridge_run-->bridge_reconfigure-->bridge_add_ports-->bridge_add_ports__-->iface_create-->iface_do_create-->netdev_open-->construct-->dpif_create_and_open-->dpif_open-->do_open-->dp_initialize-->dpctl_unixctl_register-->dpctl_unixctl_handler-->dpctl_dump_flows
dpctl_dump_flows
- 首先做参数检测,保证参数合理性
dpif_flow_dump_create-->dpif_netlink_flow_dump_create主要有两个事情,一个就是nl_dump_start,原来的dump ovs的流表,另一个就是dump offloaded流表,用的函数start_netdev_dump- 遍历所有满足类型条件的流表,并且根据filter进行过滤。
dpctl_dump_flows { if (flow_passes_type_filter(&f, &dump_types)) { format_dpif_flow(&ds, &f, portno_names, dpctl_p); dpctl_print(dpctl_p, "%s ", ds_cstr(&ds)); } } static bool flow_passes_type_filter(const struct dpif_flow *f, struct dump_types *dump_types) { if (dump_types->ovs && !strcmp(f->attrs.dp_layer, "ovs")) { return true; } if (dump_types->tc && !strcmp(f->attrs.dp_layer, "tc")) { return true; } if (dump_types->dpdk && !strcmp(f->attrs.dp_layer, "dpdk")) { return true; } if (dump_types->offloaded && f->attrs.offloaded && strcmp(f->attrs.dp_layer, "ovs")) { return true; }dpctl_dump_flows { if (flow_passes_type_filter(&f, &dump_types)) { format_dpif_flow(&ds, &f, portno_names, dpctl_p); dpctl_print(dpctl_p, "%s ", ds_cstr(&ds)); } } static bool flow_passes_type_filter(const struct dpif_flow *f, struct dump_types *dump_types) { if (dump_types->ovs && !strcmp(f->attrs.dp_layer, "ovs")) { return true; } if (dump_types->tc && !strcmp(f->attrs.dp_layer, "tc")) { return true; } if (dump_types->dpdk && !strcmp(f->attrs.dp_layer, "dpdk")) { return true; } if (dump_types->offloaded && f->attrs.offloaded && strcmp(f->attrs.dp_layer, "ovs")) { return true; } if (dump_types->partially_offloaded && f->attrs.offloaded && !strcmp(f->attrs.dp_layer, "ovs")) { return true; } if (dump_types->non_offloaded && !(f->attrs.offloaded)) { return true; } return false; } if (dump_types->partially_offloaded && f->attrs.offloaded && !strcmp(f->attrs.dp_layer, "ovs")) { return true; } if (dump_types->non_offloaded && !(f->attrs.offloaded)) { return true; } return false; }
参考https://zhaozhanxu.com/2018/05/16/SDN/OVS/2018-05-16-offload/
华为 https://support.huaweicloud.com/usermanual-kunpengcpfs/kunpengsriov_06_0006.html
例子 http://yunazuno.hatenablog.com/entry/2018/07/08/215118
UCloud基于OpenvSwitch卸载的高性能25G智能网卡实践
http://blog.ucloud.cn/archives/3904
VXLAN offload using tc flower on ConnectX-5
https://marcelwiget.blog/2021/02/15/vxlan-offload-using-tc-flower-on-connectx-5/amp/
OVS Offload Using ASAP² Direct
https://docs.mellanox.com/m/view-rendered-page.action?abstractPageId=32413345