Build Your Own Container Using Less than 100 Lines of Go
https://www.infoq.com/articles/build-a-container-golang/
Linux containers in 500 lines of code
https://blog.lizzie.io/linux-containers-in-500-loc.html
https://github.com/jiajunhuang/cup/blob/master/main.go

package main import ( "fmt" "io/ioutil" "os" "os/exec" "path" "strconv" "syscall" ) // 挂载了memory subsystem的hierarchy的根目录位置 const cgroupMemoryHierarchyMount = "/sys/fs/cgroup/memory" func main() { if os.Args[0] == "/proc/self/exe" { // 容器进程 fmt.Printf("current pid %d ", syscall.Getpid()) cmd := exec.Command("sh", "-c", `stress --vm-bytes 200m --vm-keep -m 1`) cmd.SysProcAttr = &syscall.SysProcAttr{} cmd.Stdin = os.Stdin cmd.Stdout = os.Stdout cmd.Stderr = os.Stderr if err := cmd.Run(); err != nil { fmt.Println(err) os.Exit(1) } } cmd := exec.Command("/proc/self/exe") cmd.SysProcAttr = &syscall.SysProcAttr{ Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS, } cmd.Stdin = os.Stdin cmd.Stdout = os.Stdout cmd.Stderr = os.Stderr if err := cmd.Run(); err != nil { fmt.Println("Error", err) os.Exit(1) } else { // 得到fork出来进程映射在外部命名空间的pid fmt.Printf("%v ", cmd.Process.Pid) // 在系统默认创建挂载了 memory subsystem 的hierarchy上创建cgroup os.Mkdir(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit"), 0755) // 将容器进程加入到这个cgroup中 ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit", "tasks"), []byte(strconv.Itoa(cmd.Process.Pid)), 0644) // 限制cgroup进程使用 ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit", "memory.limit_in_bytes"), []byte("100m"), 0644) cmd.Process.Wait() } }
Docker cached mirror function makes much more efficient than VMDKs or Vagrantfiles, it enables us to be transferred with respect to the common base image difference, rather than a complete transfer image. This means that our entire environment can be transferred from one location to another. This is why when you execute "docker run a certain program," it can start with near real-time speed, or even start a complete operating system image. We will further discuss the details of this way of working mechanism later.
This is the function of the container, it will be able to rely on various packaged together, so that we can in a repeatable way to deploy security code. But this is only a high-level goals, rather than its definition. Well, let's talk about some practical things right.
Create a container
So, what is the container it (this is serious!)? If you create a container as simple as possible to implement a system call create_container just fine. It is of course not so simple, but in fact not far off.
In order to discuss container at a low level, we must first discuss the three elements, these three elements are namespace, cgroups and hierarchical file system. Although there are other factors, but can be achieved by the three main functions.
Namespaces
Namespace provides a machine operating in a plurality of containers necessary for isolation, while each container feels just as well as a separate environment. As of this writing, there are a total of six namespace. Each namespace can independently request, provides a view equivalent to a subset of the resources of this machine is a process (and its child processes).
These namespaces include:
- PID: PID namespace provides a view of a sub-set of processes in the system for a process and its children. You can think of it as a map. When the PID namespace of a process requests a list of processes to the kernel, kernel will check the mapping table. If the process already exists in the table, then the kernel will return to its mapping ID, not the real ID. If the process does not exist in the mapping table, then the kernel would assume that the process is completely absent. pid first process created in the PID namespace is 1 (therefore mapping is its host ID 1), which namespace in the container will be manifested as an isolated process tree.
- MNT: In a sense, mount namespace is the most important namespace, which provides a unique mount table for the process contained therein. This also means that does not affect other namespaces (including the host namespace) when these processes to the directory or unmounted. More importantly, we will see, by binding to pivot_root this system call, it allows a process to have a unique file system. Therefore, the file system simply exchange container, the process will think it is running on a Ubuntu, BusyBox, or in Alpine.
- NET: network namespace to use its process gives independent network stacks. Generally speaking, only the main network namespace (that is, when the namespace will start automatically when you start a process where the machine) will be allocated in real physical card. But we can create a virtual network devices that interconnect card, one end of which belong to a network namespace, while the other end belongs to another network namespace, in this way creates a space between two network name virtual connection. This is similar to the way some have multiple IP stack to communicate on the same host. By a certain routing logic, each container can be maintained own independent network stack, and can communicate with the outside world.
- UTS: UTS (UNIX Time-sharing System) namespace provides a unique view of the system host name and domain name for the process of it. When entering a UTS namespace, to modify the host name and the domain name will not affect other processes.
- IPC: IPC (Interprocess Communication) namespace can be isolated communication mechanism between the various processes, such as message queuing and the like. Refer to the namespace relevant documents, for more details.
- USER: user namespace just recently got support from a security perspective, it is probably the most powerful kind of a namespace. user namespace is able to map a process seen uid to host a different uid (and gid) collection. This feature is very useful, by using the user name space, we will be able to root user container ID (such as 0) is mapped to the host in an arbitrary (and does not confer privileges) uid. This means that we can make a container believes it has access to the root, while at the same time without the need (we can even access its container specific resources for their permission to confer any root namespace confers similar to the root permissions). Container can easily run with uid 0 process (which usually means that the user has root privileges), and the kernel will be mapped to the uid to a non-privileged real uid inside. Most container system will not any uid mapping vessel is calling namespace uid 0, in other words, no one has uid root privileges does not exist in the container.
Most container technology will be placed in the user process above all namespace, then initialize these namespaces to provide a standard environment. For example, it is possible to create a namespace container network card isolation, it can be connected to host real network.
CGroups
Honestly, CGroups enough content specifically described by an article (I will respect this right to write an article to retain!). I would be very succinctly described this part of the article, once you understand the concepts, you can find answers to most of the questions directly in the document.
Essentially, the role of CGroups is to bring together a series of process or task id, to set restrictions. The role of namespaces is the process of isolation, and CGroups purpose is to implement in a fair process (also may be unfair, it depends on what you think, you may want) to share resources.
kernel will CGroups exposed as a special file system, you can mount. Just the process id file is added to a task, it can be added to CGroup in a process or thread. After that, you just edit the files in that directory, it is possible to read and modify a variety of configurations.
Hierarchical File System
Namespace CGroups responsible container of isolation and resource sharing, they realized the main functions and security containers. The hierarchical file system allows us to efficiently move the complete machine images, which ensure the continued operation of the vessel.
In essence, the role of hierarchical file system is to create a container for each invocation of a copy of the root file system optimized. There are many different ways to achieve this goal. Btrfs copy (copy-on-write) technique using a write file system layer, and Aufs using the "union mounts" This mount mechanism. Since this step can be achieved in various ways, so we selected a very simple way: we will truly create a copy. Although this approach is slow, but it gets the job done.
Create a container
The first step: to build a skeleton program
We begin to build the skeleton of the program. Assuming you have already installed golang programming language SDK latest version, please open your editor and copy the following code.
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
switch os.Args[1] {
case "run":
parent()
case "child":
child()
default:
panic("wat should I do")
}
}
func parent() {
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println("ERROR", err)
os.Exit(1)
}
}
func child() {
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println("ERROR", err)
os.Exit(1)
}
}
func must(err error) {
if err != nil {
panic(err)
}
}
So what is the role of this procedure is it? Entry procedure is main.go, it needs to read the first parameter. If the parameter is 'run', then run parent () method, if it is 'child' run child () method. The method of performing parent '/proc/self/exe', which is a special file that contains an executable file of the current memory image. In other words, we will recall the program itself, the 'child' as the first argument.
What is the significance of this crazy way? At present, it does not have much effect. It just allows us to execute another program, a program in which the execution is requested by the user ( '[2:] os.Args' by the content definition). However, based on this simple structure, we will be able to create a container.
Step two: add a namespace
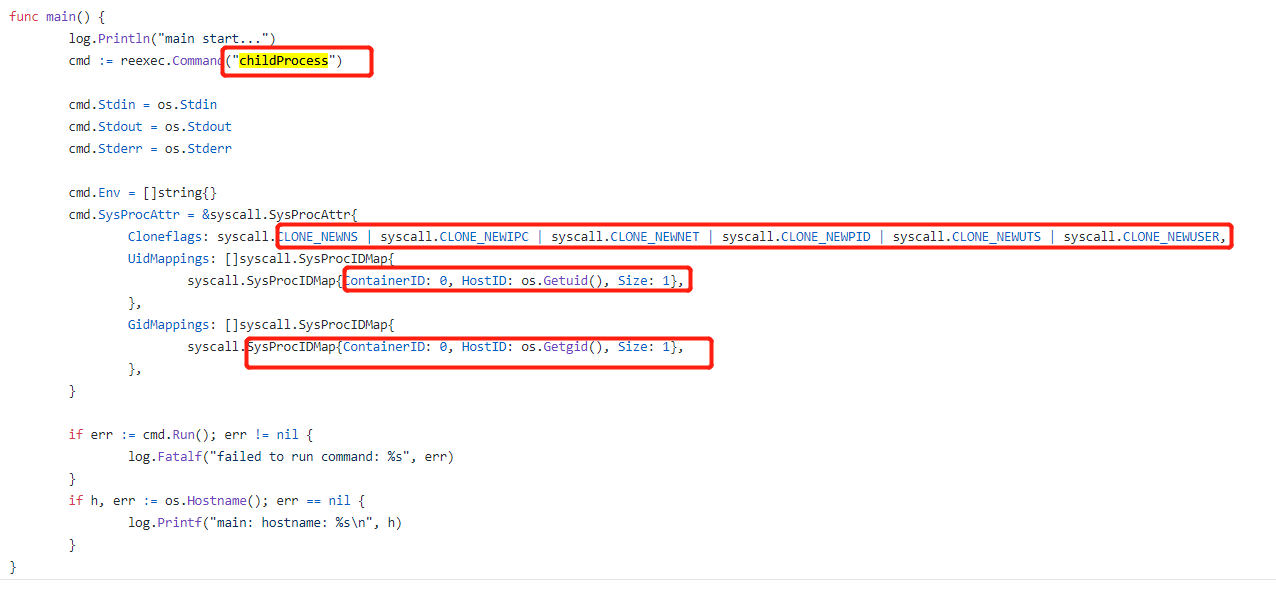
To join a namespace in the program, we simply add one line of code. In the parent () method of the second line add the following code, its role is to make this program go to add some additional flag when running child process.
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
}
Now if you run this program immediately, you will find that the program has been running for UTS, PID namespace as well as the MNT!
The third step: root file system
Now, your process is already running in some isolated namespace in the (Feel free to try to add another namespace in Cloneflags code above), but the host file system still looked the same. This is because the process is running in a mount namespace, but the original is still mount inherited from the namespace responsible for creating the work.
So we need to make some changes here. We need to switch to the root file system in the following four lines of code, the code is placed in place '() child' at the beginning of the function.
must(syscall.Mount("rootfs", "rootfs", "", syscall.MS_BIND, ""))
must(os.MkdirAll("rootfs/oldrootfs", 0700))
must(syscall.PivotRoot("rootfs", "rootfs/oldrootfs"))
must(os.Chdir("/"))
The last two lines of code is the most important part, they will notify the operating system '/' corresponding to the current directory to 'rootfs/oldrootfs', and set a new rootfs directory as '/'. After the end of the 'pivotroot' call, the vessel '/' directory pointing rootfs directory (bound calls are mounted in order to meet certain conditions 'pivotroot' command, the operating system requires file system 'pivotroot' exchanged can not be in the same tree, but by the rootfs mounts to bind itself will be able to accomplish this goal, this approach is really stupid.).
Step four: initialization container environment
Currently, the process is already running in your namespace in a series of isolated, and you have a choice of the root file system. We can skip setting CGroups part, because it is very simple. We also omitted part of the root file system management, it allows you to efficiently download and cache the root file system image that we just passed 'pivotroot' way to create.
We also omit the configuration of the container, you are now all is running a new container in the namespace in isolation. We set the switch to the rootfs mount namespace, but other namespaces is still only the default content. In the actual container, we need to configure the entire environment of the container, and then to be able to run user processes. For example, we need to set up the network, switch to the correct uid before running processes, and set some other necessary restrictions (such as the ability to use dropping and setting rlimits) and so on. These efforts may make our program more than 100 lines of code.
Step Five: Summary
Well, we've got a super simple container, it only took (far) go less than 100 lines of code. Of course, we intend to simplify this process. If you intend to use in a production environment this procedure, you must be crazy, you bear the consequences of it. But I think that, through these simple and not so formal code, can help you understand specifically what happened. So let's take a complete look at this program it.
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
switch os.Args[1] {
case "run":
parent()
case "child":
child()
default:
panic("wat should I do")
}
}
func parent() {
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println("ERROR", err)
os.Exit(1)
}
}
func child() {
must(syscall.Mount("rootfs", "rootfs", "", syscall.MS_BIND, ""))
must(os.MkdirAll("rootfs/oldrootfs", 0700))
must(syscall.PivotRoot("rootfs", "rootfs/oldrootfs"))
must(os.Chdir("/"))
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println("ERROR", err)
os.Exit(1)
}
}
func must(err error) {
if err != nil {
panic(err)
}
}
So, what is the significance of the container?
The following personal point of view may cause some controversy: For me, the container is a wonderful way to deploy software, it can be a very low cost way to run code and to achieve high isolation, but its significance is not only reflected here. A container is a technical, rather than a user experience.
As a buyer on the amazon.com site, I do not tend to call the marina to arrange the distribution process of goods. Similarly, as a user, I just want to deploy vessels to the production environment, without having to know the specific details. A container is a wonderful technology to build the system, but we should not start from the developer to create an excellent experience point of view, the container can be efficiently deploy capacity machine image attracted.
Many Platform as a Service (PaaS) systems, such as Cloud Foundry provided by the user experience based on the code, rather than container-based. For most developers, their goal is to run code directly upload it. Cloud Foundry and most other PaaS platforms will get the internal code users to upload, and create a mirror image of the container, a process that can easily expand and manage. Cloud Foundry buildpack achieve this by, but you can ignore this step and just create a mirror image upload Docker from Dockerfile.
In the PaaS platform will still be able to show all the benefits of containers, including a consistent environment, efficient resource management, etc., but by controlling the user experience, PaaS platform can provide a simplified user experience for developers, but also provides some additional features, such as automatic patch when its root file system security risks. In addition, the platform also provides services such as databases and message queues, you can use these services in your app without having to consider from the perspective of container each function.
Well, we have conducted a full study of the nature of the container. Now, how do we use them?