支持虚拟化技术的硬件平台主要做两件事,一个是DMA Remapping,将DMA请求中的Guest的物理地址映射到Host的物理地址,另一个是中断Remapping,将能remappable的中断请求根据由VMM设置,位于内存的IRT(Interrupt Remapping Table)发送到指定的vcpu上。
实质就是在dma设备和memory之间加了一层,用于remapping和检查。
通过dma remmapping,iommu可以支持将设备直接赋给guest,将dma表内设备对应的地址写成guest对应的地址即可
iommu还支持interupt的remapping,从而可以将interrupt映射到特定的vm,支持vm对设备的直接操作
IOMMU
DMA重映射也称为IOMMU,因为它的功能类似于用于IO内存访问的内存管理单元(MMU)。不仅概念相似,而且与MMU的编程接口也非常相似,即分页结构和EPT。
从高级的角度来看,主要区别在于DMA重映射在熟悉的PML5、4,PDPT,PD和PT的顶部使用了两个表进行转换。简而言之,使用MMU进行的转换如下:
· Hardware register => PML4 => PDPT => ...
而IOMMU的是:
· Hardware register => Root table => Context table => PML4 => PDPT => ...
该规范将上下文表中引用的表称为第二级页表,下图说明了转换流程。
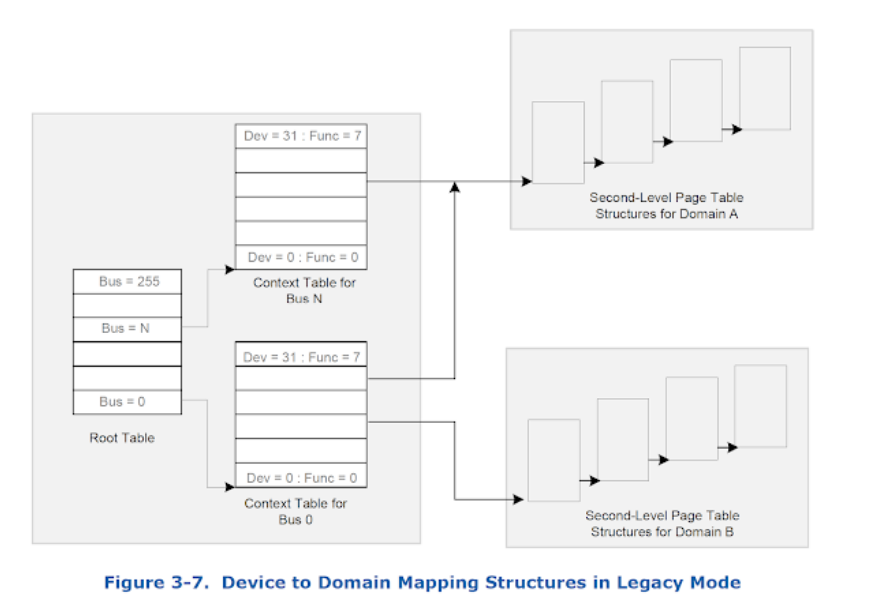
IOMMU功能简介
IOMMU主要功能包括DMA Remapping和Interrupt Remapping,这里主要讲解DMA Remapping,Interrupt Remapping会独立讲解。对于DMA Remapping,IOMMU与MMU类似。IOMMU可以将一个设备访问地址转换为存储器地址,下图针对有无IOMMU情况说明IOMMU作用。
在没有IOMMU的情况下,网卡接收数据时地址转换流程,RC会将网卡请求写入地址addr1直接发送到DDR控制器,然后访问DRAM上的addr1地址,这里的RC对网卡请求地址不做任何转换,网卡访问的地址必须是物理地址。
对于有IOMMU的情况,网卡请求写入地址addr1会被IOMMU转换为addr2,然后发送到DDR控制器,最终访问的是DRAM上addr2地址,网卡访问的地址addr1会被IOMMU转换成真正的物理地址addr2,这里可以将addr1理解为虚机地址。
root@zj-x86:~# awk '{print $1,$20,$22,$68,$20,$50,$51,$52,$(NF-4),$(NF-3),$(NF-2),$(NF-1),$(NF)}' /proc/interrupts | grep -i DMAR-MSI 104: 0 0 0 0 0 0 0 0 0 DMAR-MSI 6-edge dmar6 105: 0 0 0 0 0 0 0 0 0 DMAR-MSI 5-edge dmar5 106: 0 0 0 0 0 0 0 0 0 DMAR-MSI 4-edge dmar4 107: 0 0 0 0 0 0 0 0 0 DMAR-MSI 3-edge dmar3 108: 0 0 0 0 0 0 0 0 0 DMAR-MSI 2-edge dmar2 109: 0 0 0 0 0 0 0 0 0 DMAR-MSI 1-edge dmar1 110: 0 0 0 0 0 0 0 0 0 DMAR-MSI 0-edge dmar0 111: 0 0 0 0 0 0 0 0 0 DMAR-MSI 7-edge dmar7
家知道,I/O设备可以直接存取内存,称为DMA(Direct Memory Access);DMA要存取的内存地址称为DMA地址(也可称为BUS address)。在DMA技术刚出现的时候,DMA地址都是物理内存地址,简单直接,但缺点是不灵活,比如要求物理内存必须是连续的一整块而且不能是高位地址等等,也不能充分满足虚拟机的需要。后来dmar就出现了。 dmar意为DMA remapping,是Intel为支持虚拟机而设计的I/O虚拟化技术,I/O设备访问的DMA地址不再是物理内存地址,而要通过DMA remapping硬件进行转译,DMA remapping硬件会把DMA地址翻译成物理内存地址,并检查访问权限等等。负责DMA remapping操作的硬件称为IOMMU。做个类比:大家都知道MMU是支持内存地址虚拟化的硬件,MMU是为CPU服务的;而IOMMU是为I/O设备服务的,是将DMA地址进行虚拟化的硬件。  IOMMA不仅将DMA地址虚拟化,还起到隔离、保护等作用,如下图所示意,详细请参阅Intel Virtualization Technology for Directed I/O
IOMMA不仅将DMA地址虚拟化,还起到隔离、保护等作用,如下图所示意,详细请参阅Intel Virtualization Technology for Directed I/O 现在我们知道了dmar的概念,那么Linux中断信息中出现的dmar0又是什么呢? 还是用MMU作类比吧,便于理解:当CPU访问一个在地址翻译表中不存在的地址时,就会触发一个fault,Linux kernel的fault处理例程会判断这是合法地址还是非法地址,如果是合法地址,就分配相应的物理内存页面并建立从物理地址到虚拟地址的翻译表项,如果是非法地址,就给进程发个signal,产生core dump。IOMMU也类似,当I/O设备进行DMA访问也可能触发fault,有些fault是recoverable的,有些是non-recoverable的,这些fault都需要Linux kernel进行处理,所以IOMMU就利用中断(interrupt)的方式呼唤内核,这就是我们在/proc/interrupts中看到的dmar0那一行的意思。
现在我们知道了dmar的概念,那么Linux中断信息中出现的dmar0又是什么呢? 还是用MMU作类比吧,便于理解:当CPU访问一个在地址翻译表中不存在的地址时,就会触发一个fault,Linux kernel的fault处理例程会判断这是合法地址还是非法地址,如果是合法地址,就分配相应的物理内存页面并建立从物理地址到虚拟地址的翻译表项,如果是非法地址,就给进程发个signal,产生core dump。IOMMU也类似,当I/O设备进行DMA访问也可能触发fault,有些fault是recoverable的,有些是non-recoverable的,这些fault都需要Linux kernel进行处理,所以IOMMU就利用中断(interrupt)的方式呼唤内核,这就是我们在/proc/interrupts中看到的dmar0那一行的意思。
https://www.ershicimi.com/p/a650d2fdfa57da45fa2a69015bbd5b4e
VFIO
VFIO就是内核针对IOMMU提供的软件框架,支持DMA Remapping和Interrupt Remapping,这里只讲DMA Remapping。VFIO利用IOMMU这个特性,可以屏蔽物理地址对上层的可见性,可以用来开发用户态驱动,也可以实现设备透传。
2.1 概念介绍
先介绍VFIO中的几个重要概念,主要包括Group和Container。
Group:group 是IOMMU能够进行DMA隔离的最小硬件单元,一个group内可能只有一个device,也可能有多个device,这取决于物理平台上硬件的IOMMU拓扑结构。设备直通的时候一个group里面的设备必须都直通给一个虚拟机。不能够让一个group里的多个device分别从属于2个不同的VM,也不允许部分device在host上而另一部分被分配到guest里, 因为就这样一个guest中的device可以利用DMA攻击获取另外一个guest里的数据,就无法做到物理上的DMA隔离。
Container:对于虚机,Container 这里可以简单理解为一个VM Domain的物理内存空间。对于用户态驱动,Container可以是多个Group的集合。
上图中PCIe-PCI桥下的两个设备,在发送DMA请求时,PCIe-PCI桥会为下面两个设备生成Source Identifier,其中Bus域为红色总线号bus,device和func域为0。这样的话,PCIe-PCI桥下的两个设备会找到同一个Context Entry和同一份页表,所以这两个设备不能分别给两个虚机使用,这两个设备就属于一个Group。
2.2 使用示例
这里先以简单的用户态驱动为例,在设备透传小节中,在分析如何利用vfio实现透传。
int container, group, device, i;
struct vfio_group_status group_status =
{ .argsz = sizeof(group_status) };
struct vfio_iommu_type1_info iommu_info = { .argsz = sizeof(iommu_info) };
struct vfio_iommu_type1_dma_map dma_map = { .argsz = sizeof(dma_map) };
struct vfio_device_info device_info = { .argsz = sizeof(device_info) };
/* Create a new container */
container = open("/dev/vfio/vfio", O_RDWR);
if (ioctl(container, VFIO_GET_API_VERSION) != VFIO_API_VERSION)
/* Unknown API version */
if (!ioctl(container, VFIO_CHECK_EXTENSION, VFIO_TYPE1_IOMMU))
/* Doesn't support the IOMMU driver we want. */
/* Open the group */
group = open("/dev/vfio/26", O_RDWR);
/* Test the group is viable and available */
ioctl(group, VFIO_GROUP_GET_STATUS, &group_status);
if (!(group_status.flags & VFIO_GROUP_FLAGS_VIABLE))
/* Group is not viable (ie, not all devices bound for vfio) */
/* Add the group to the container */
ioctl(group, VFIO_GROUP_SET_CONTAINER, &container);
/* Enable the IOMMU model we want */ // type 1 open | attatch
ioctl(container, VFIO_SET_IOMMU, VFIO_TYPE1_IOMMU);
/* Get addition IOMMU info */
ioctl(container, VFIO_IOMMU_GET_INFO, &iommu_info);
/* Allocate some space and setup a DMA mapping */
dma_map.vaddr = mmap(0, 1024 * 1024, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
dma_map.size = 1024 * 1024;
dma_map.iova = 0; /* 1MB starting at 0x0 from device view */
dma_map.flags = VFIO_DMA_MAP_FLAG_READ | VFIO_DMA_MAP_FLAG_WRITE;
ioctl(container, VFIO_IOMMU_MAP_DMA, &dma_map);
/* Get a file descriptor for the device */
device = ioctl(group, VFIO_GROUP_GET_DEVICE_FD, "0000:06:0d.0");
/* Test and setup the device */
ioctl(device, VFIO_DEVICE_GET_INFO, &device_info);
对于dev下Group就是按照上一节介绍的Group划分规则产生的,上述代码描述了如何使用VFIO实现映射,对于Group和Container的相关操作这里不做过多解释,主要关注如何完成映射,下图解释具体工作流程。
首先,利用mmap映射出1MB字节的虚拟空间,因为物理地址对于用户态不可见,只能通过虚拟地址访问物理空间。然后执行ioctl的VFIO_IOMMU_MAP_DMA命令,传入参数主要包含vaddr及iova,其中iova代表的是设备发起DMA请求时要访问的地址,也就是IOMMU映射前的地址,vaddr就是mmap的地址。VFIO_IOMMU_MAP_DMA命令会为虚拟地址vaddr找到物理页并pin住(因为设备DMA是异步的,随时可能发生,物理页面不能交换出去),然后找到Group对应的Contex Entry,建立页表项,页表项能够将iova地址映射成上面pin住的物理页对应的物理地址上去,这样对用户态程序完全屏蔽了物理地址,实现了用户空间驱动。IOVA地址的00x100000对应DRAM地址0x100000000x10100000,size为1024 * 1024。一句话概述,VFIO_IOMMU_MAP_DMA这个命令就是将iova通过IOMMU映射到vaddr对应的物理地址上去。
话说,盘古开天的时候,设备访问内存(DMA)就只接受物理地址,所以CPU要把一个地址告诉设备,就只能给物理地址。但设备的地址长度还比CPU的总线长度短,所以只能分配低地址来给设备用。所以CPU这边的接口就只有dma=dma_alloc(dev, size),分配了物理地址,然后映射为内核的va,然后把pa作为dma地址,CPU提供给设备,设备访问这个dma地址,就得到内存里面的那个数据了。
后来设备做强了,虽然地址总线不长,但可以带一个页表,把它能访问的有限长度的dma地址转换为和物理空间一样长的物理地址。这样就有了dma=dma_map(dev, va)。这样,其实我们对同一个物理地址就有三个地址的概念了:CPU看到的地址va,设备看到的地址dma,和总线看到的pa。
设备带个页表,这不就是mmu吗?于是,通用的iommu的概念(硬件上)就被发明了。所以dma_map(dev, va),在有iommu的设备上,就变成了对iommu的通用页表操作。iova=iommu_alloc(), iommu_map(domain, iova, pa);
这里我们发现了两个新概念,一个是iova,这个很好理解,就是原来的dma地址了(io的va嘛),另一个是domain,这本质是一个页表,为什么要把这个页表独立封装出来,这个我们很快会看到的。
我这个需要提醒一句,iommu用的页表,和mmu用的页表,不是同一个页表,为了容易区分,我们把前者叫做iopt,后者叫pt。两者都可以翻译虚拟地址为物理地址,物理地址是一样的,都是pa,而对于va,前者我们叫iova,后者我们叫va。
又到了后来,人们需要支持虚拟化,提出了VFIO的概念,需要在用户进程中直接访问设备,那我们就要支持在用户态直接发起DMA操作了,用户态发起DMA,它自己在分配iova,直接设置下来,要求iommu就用这个iova,那我内核对这个设备做dma_map,也要分配iova。这两者冲突怎么解决呢?
dma_map还可以避开用户态请求过的va空间,用户态的请求没法避开内核的dma_map的呀。
VFIO这样解决:默认情况下,iommu上会绑定一个default_domain,它具有IOMMU_DOMAIN_DMA属性,原来怎么弄就怎么弄,这时你可以调用dma_map()。但如果你要用VFIO,你就要先detach原来的驱动,改用VFIO的驱动,VFIO就给你换一个domain,这个domain的属性是IOMMU_DOMAIN_UNMANAGED,之后你爱用哪个iova就用那个iova,你自己保证不会冲突就好,VFIO通过iommu_map(domain, iova, pa)来执行这种映射。
等你从VFIO上detach,把你的domain删除了,这个iommu就会恢复原来的default_domain,这样你就可以继续用你的dma API了。
这种情况下,你必须给你的设备选一种应用模式,非此即彼。
很多设备,比如GPU,没有用VFIO,也会自行创建unmanaged的domain,自己管理映射,这个就变成一个通用的接口了。
好了,这个是Linux内核的现状(截止到4.20)。如果基于这个现状,我们要同时让用户态和内核态都可以做mapping的话,唯一的手段是使用unmanaged模式,然后va都从用户态分配(比如通过mmap),然后统一用iommu_map完成这个映射。
但实际上,Linux的这个框架,已经落后于硬件的发展了。因为现在大部分IOMMU,都支持多进程访问。比如我有两个进程同时从用户态访问设备,他们自己管理iova,这样,他们给iommu提供的iova就可能是冲突的。所以,IOMMU硬件同时支持多张iopt,用进程的id作为下标(对于PCIE设备来说,就是pasid了)。
这样,我们可以让内核使用pasid=0的iopt,每个用户进程用pasid=xxx的iopt,这样就互相不会冲突了。
为了支持这样的应用模式,ARM的Jean Philipse做了一套补丁,为domain增加pasid支持。他的方法是domain上可以bind多个pasid,bind的时候给你分配一个io_mm,然后你用iommu_sva_map()带上这个io_mm来做mapping。
这种情况下,你不再需要和dma api隔离了,因为他会自动用pasid=0(实际硬件不一定是这样的接口,这只是比喻)的iopt来做dma api,用其他pasid来做用户态。这时你也不再需要unmanaged的domain了。你继续用dma的domain,然后bind一个pasid上去即可。
但Jean这个补丁上传的时候正好遇到Intel的Scalable Virtual IO的补丁在上传,Intel要用这个特性来实现更轻量级的VFIO。原来的VFIO,是整个设备共享给用户态的,有了pasid这个概念,我可以基于pasid分配资源,基于pasid共享给用户态。但Jean的补丁要求使用的时候就要bind一个pasid上来。但VFIO是要分配完设备,等有进程用这个设备的时候才能提供pasid。
为了解决这个问题,Jean又加了一个aux domain的概念,你可以给一个iommu创建一个primary domain,和多个aux domain。那些aux domain可以晚点再绑定pasid上来。