1. CPU发展简史
https://www.icode9.com/content-4-856085.html
2. 基本概念
2.1 地址空间:
-
线性地址空间:最大2^32=4GB,处理器可以寻址的地址空间
-
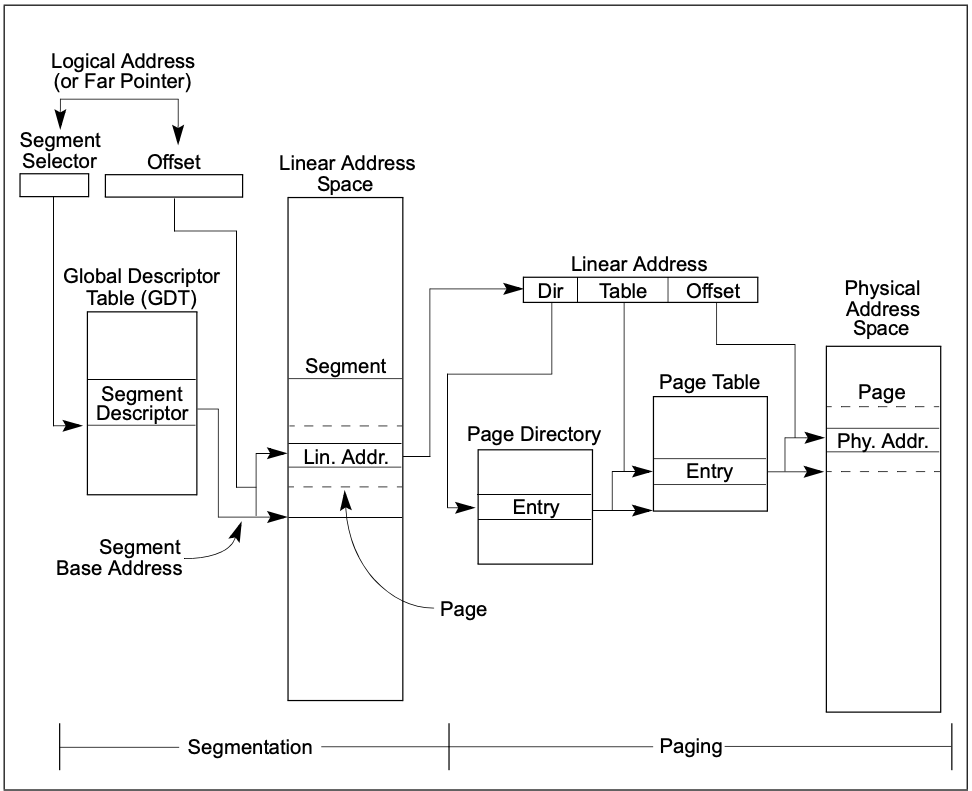
逻辑地址:所有的段包含在线性地址空间中,寻址特定字节,需要段选择子和偏移量,通过段选择子提供了指向GDT表项(提供了访问权限,线性地址的偏移量基址),通过对应段的基址+段内偏移量可以直接直接在线性地址寻址。逻辑地址有16位的段选择子和一个32位的偏移量组成,处理器会将逻辑地址转换成线性地址。
逻辑地址转换成线性地址:
- 是段段选择子的偏移量定位在GDT中的段描述符,并读取到处理器中
- 分析段描述符检查访问权限和段的范围(确保段是可访问的,偏移量在段限制范围内)
- 从段描述符查询段基址+偏移量形成线性地址
- 不分页:处理器直接映射线性地址到无力地址
- 分页:二级地址转换,将线性地址转换成物理地址
-
物理地址空间:最大2^36=64GB
- 基本的程序执行寄存器:8个通用寄存器,6个段寄存器,EFLAGS寄存器,EIP指令指针寄存器
- 栈:支持子程序调用和参数传递(参数较多时通过栈传递参数)
2.2 内存模型
处理器引入了内存管理特性,程序不会直接访问物理内存,会使用以下三种模型来访问内存:平面模型、段模型、实模式地址模型
-
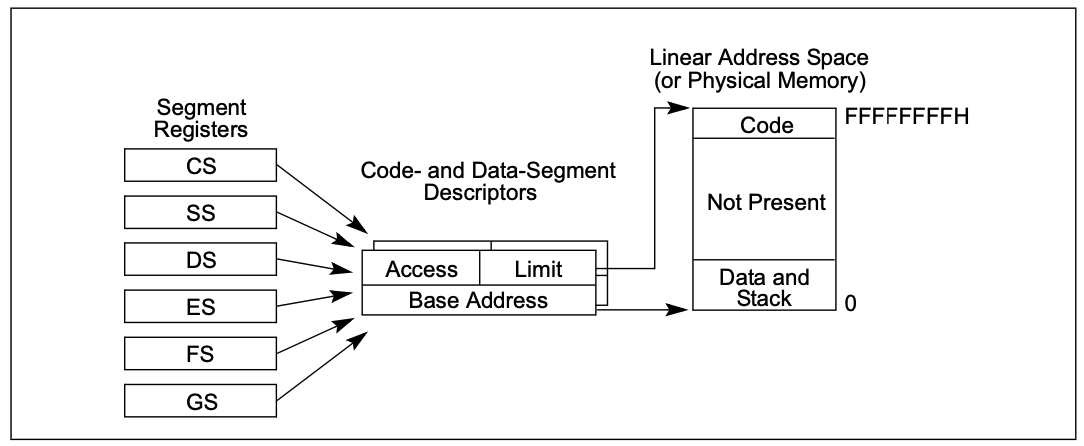
基础平面模型
在程序的视角内存是一个单一的连续的地址空间,即线性地址空间,代码、数据以及栈都包含在这个内存空间。对32位机来说,这个空间是0~2^32(4G)。
实际上程序在运行的时候至少存在两个段:代码段&数据段,但是代码段和数据段以及其他的段都映射到整个线性地址空间。会设置段的limit为4G, 即使真实的物理内存没按么大的地址空间
-
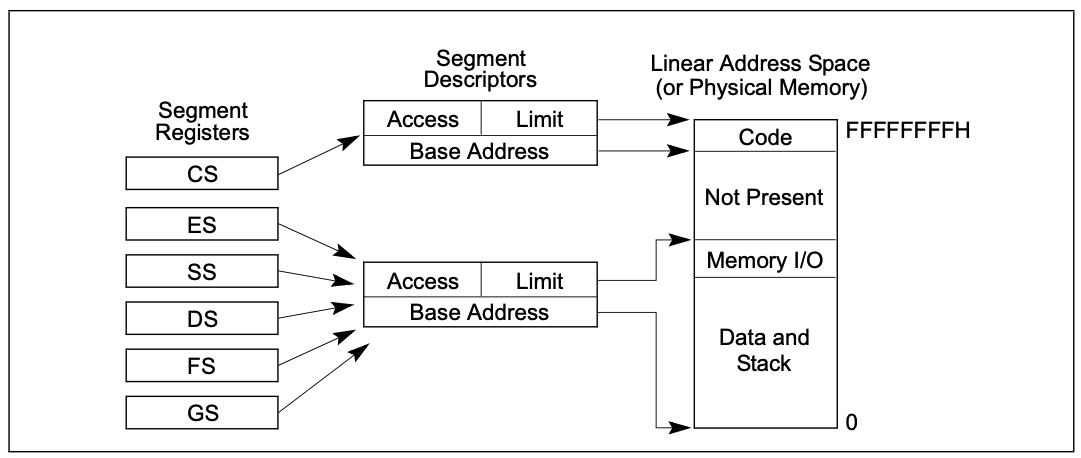
保护模式平面模型
跟基础平面模型比较类似,除了段地址的limits设置为物理地址实际存在的地址空间范围。访问不存在的内存空间,将会抛出GP异常。
-
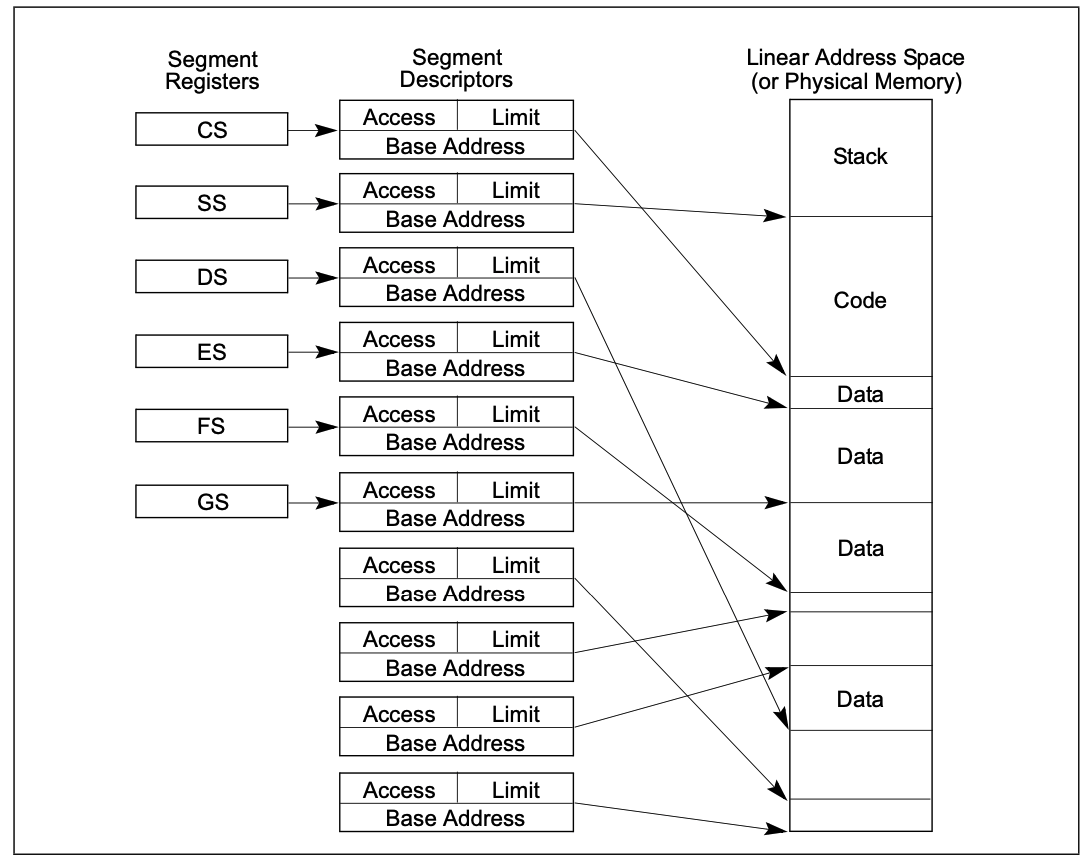
分段的模型
在程序的视角内存是一组独立的地址空间,就是分段,代码、数据、栈通常都是在不同的段中。在段中寻址,逻辑地址需要两部分:段选择子(定义了哪个段被访问)和偏移量(定义了在段中的偏移量)。在内部,所有的段都被映射到线性地址空间,但是这个转换过程对程序员是透明的。
每一个程序或者任务,有他自己的段表描述符和他自己的段。
-
实模式内存模型
实模式内存模型是8086处理器特有的,它的存在是为了兼容之前在8086下开发的程序。在8086时代,地址总线是16位,所以每个段的最大寻址是216=64KB,但最大的线性地址空间是220=1M
2.3 分页
32位的线性地址空间如何访问40位的物理地址空间?
32位访问线性地址,最大空间为2^32 = 4G,所以对每个进程而言,可以访问的内存空间只有4G
32位使用分层的分页模型才能转换线性地址空间。CR3寄存器保存了页目录的地址。分页可能是4M或者4K·
- 4M分页
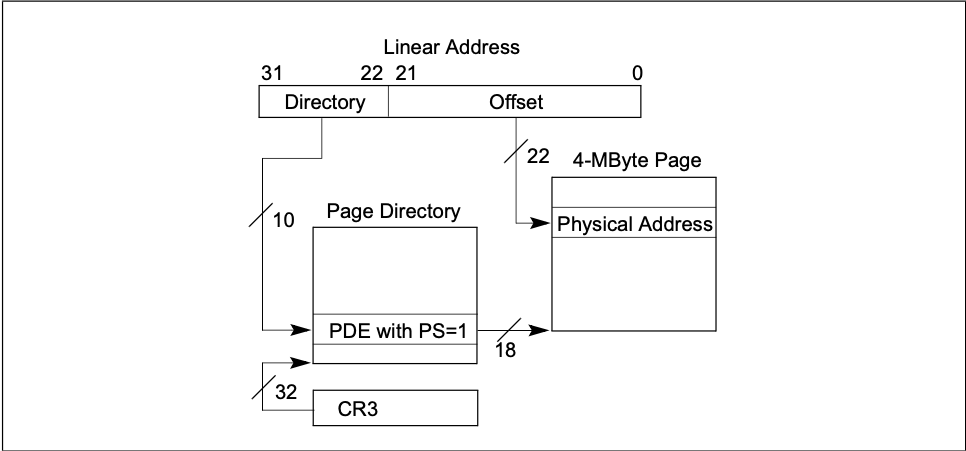
每页大小4M,所以偏移量的地址范围222,每个进程可以最大页目录210, 实际可访问内存4G, 但是可以用18位保存页表项,剩下14位的存储额外信息,则每个进程存储页表的空间大小:2^10*4byte = 4KB
- 4KB分页
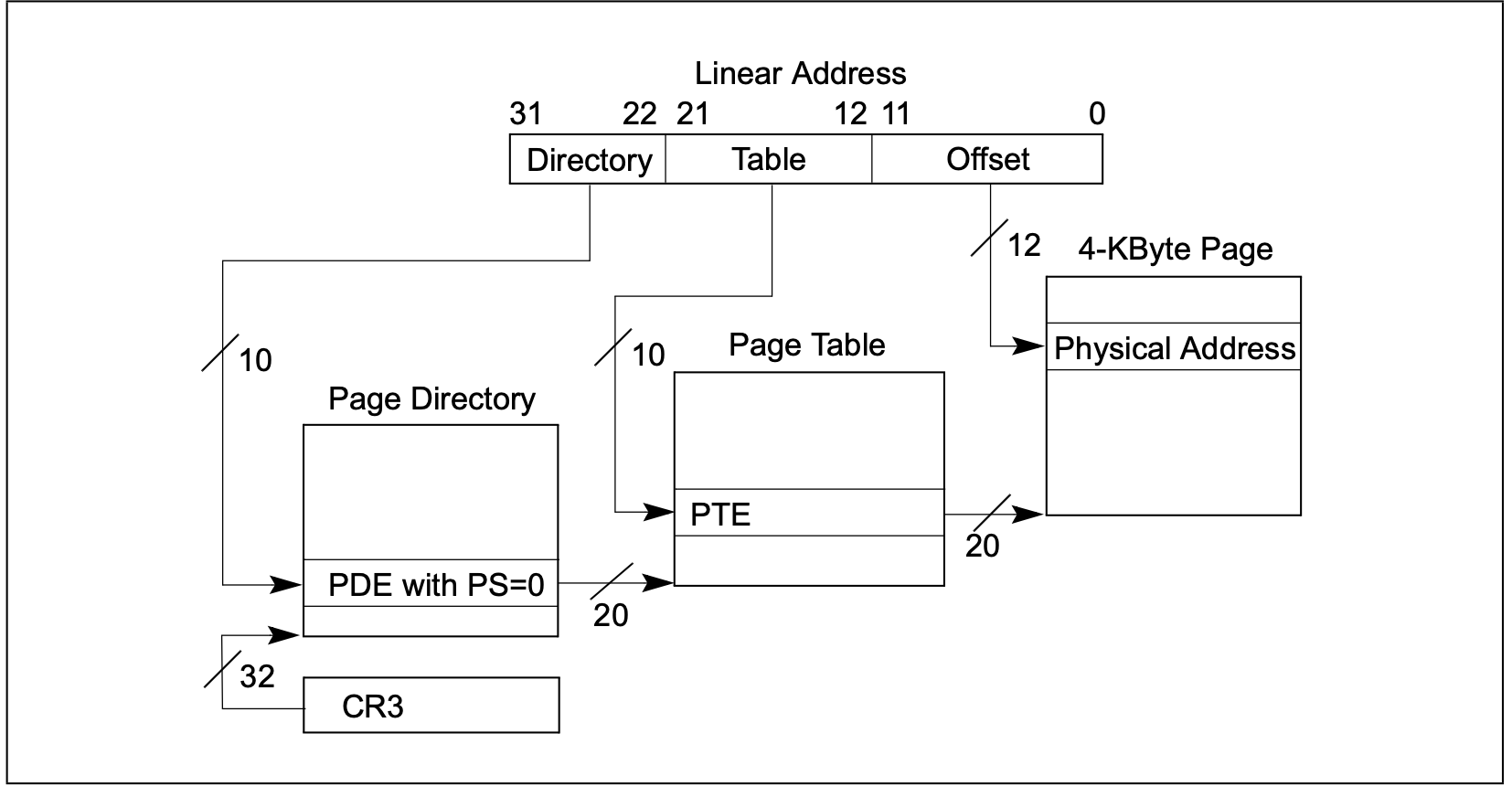
每页大小4KB,所以偏移量的地址范围212,每个进程可以最大页目录220, 实际可访问内存4G,存储页目录大小210=1KB,页表项220 * 4Kb=4G,but,可以通过懒加载,不用的空间不需要保存,不浪费空间。所以每个进程存储页表也差不多4KB。
试想:如果是只用一级分页,则需要4Gb,存储页表需要4Gb, 还玩不玩了。
3. 程序调用
3.1 Inter处理器支持的程序调用类型有两种方式:
-
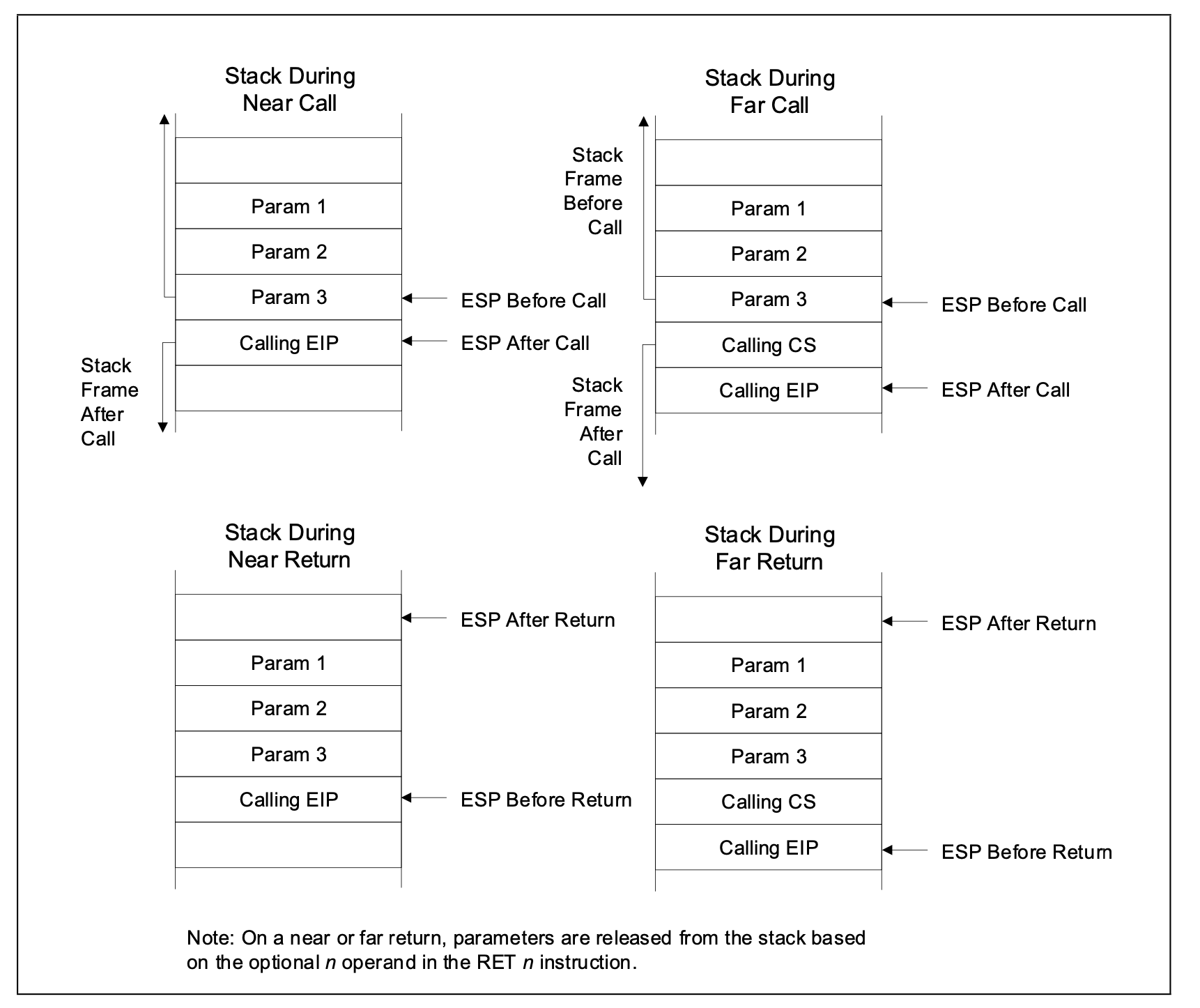
CALL 和 RET指令
NEAR FAR 描述 CALL 将IP寄存器压入栈中 CS和IP压入栈中 跳转到目标代码执行执行, 操作数保存的是目标代码的地址 RET 返回到当前代码段对应的地址 返回到不同的代码段的不同地址。 转移程序的控制权到栈顶的地址,这个地址是被CALL指令保存的 一个例子:
// c 语言的一个例子 #include "stdio.h" int sum(int a, int b) { return a+b; } int main() { int a = 1; int b = 2; sum(a, b); return 1; }汇编指令如下(移除部分不相关的指令,开辟栈空间的指令省略)
sum: #a, b movl %edi, -4(%rbp) movl %esi, -8(%rbp) movl -4(%rbp), %edx movl -8(%rbp), %eax addl %edx, %eax popq %rbp # 返回,并还原,会恢复SP ret main: # int需要开辟4字节空间,a,b 各四字节 movl $1, -4(%rbp) movl $2, -8(%rbp) # 少量的参数,直接保存在通用寄存器中,即参数 b和a movl -8(%rbp), %edx movl -4(%rbp), %eax # edi存放的是b,edi存放的是a movl %edx, %esi movl %eax, %edi # 此处会将IP寄存器压栈(指令指针寄存器,instrument pointer),跳转到sum的地址执行,即SP压入栈 call sum movl $1, %eax leave ret
-
ENTER和LEAVE指令,对应的就是CALL和RET指令
功能 描述 ENTER 开辟栈帧 ENTER numbytes, nestinglevel,
第一个操作数为开辟栈帧大小,
第二个操作数为从主线程复制多少指针到开辟的栈帧;
enter 0,0 等效率
push ebp
mov ebp, espLEAVE 恢复栈帧 跟ENTER指令配套使用,copy Enter压栈的指针到SP寄存器中,用于释放栈帧。 前面的例子中,没有Enter指令,只有Leave指令,因为笔者省略了开辟栈帧的代码
main: # 开辟栈帧 pushq %rbp movq %rsp, %rbp subq $16, %rsp # 业务代码 movl $1, -4(%rbp) movl $2, -8(%rbp) movl -8(%rbp), %edx movl -4(%rbp), %eax movl %edx, %esi movl %eax, %edi call sum movl $1, %eax # 恢复之前保存的栈 # 等效于mov %rbp, %rsp leave ret
上述的两种方式的程序调用,都使用了栈来保存调用过程的状态。处理器处理中断和异常非常类似这种使用CALL和RET指令的方式。
3.2 栈
栈是一个连续的地址空间,包含在一个段中,这个段是被段选择子中被定义的,段选择子保存着爱SS寄存器中。出栈和入栈使用指令push和pop。
当使用平面模型的时候,栈可以是全部的线性地址空间。栈的上限是4G(一个段的最大值)
Inter的栈是向下分配空间的,所以当入栈的时候需要将SP的值减小。一言以蔽之,栈向下扩展分配空间,向上回收内存空间。多任务系统中,每一个任务都有自己的栈。栈的数量受限于段的数量和物理内存空间。虽然是由多个栈,但是只有一个栈是活动的。当前的栈的段地址是保存在SS寄存器中的。SS寄存器会自动指向当前的栈,然后CALL,RET,PUSH,POP,ENTER,和LEAVE指令操作的都是当前的栈。
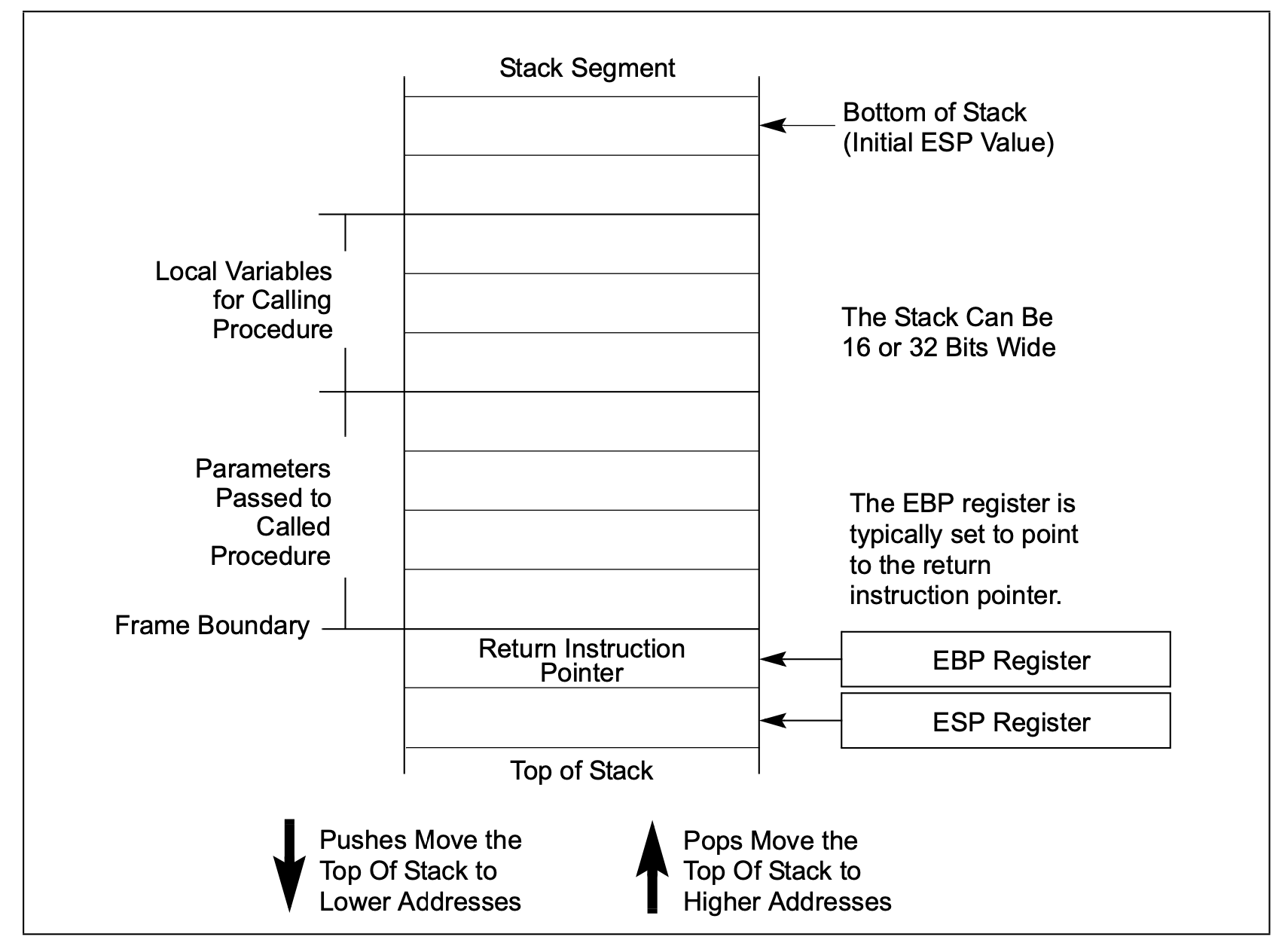
此处应该寄出我们的神图,栈向下扩展分配空间,堆向上扩展分配空间。
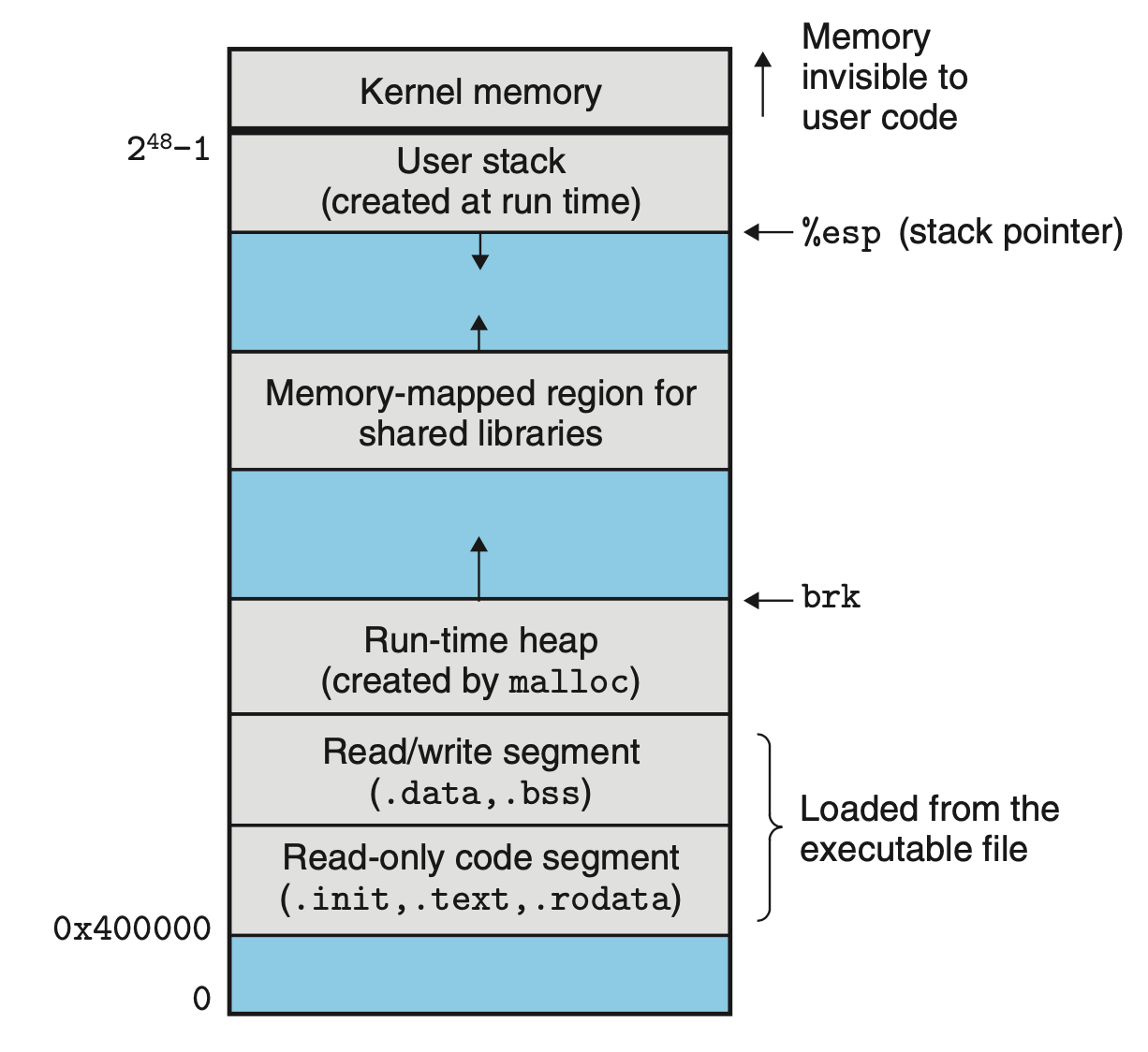
3.3 参数传递
参数传递方式有三种:通用寄存器传递,参数列表,通过栈传递
-
通过通用寄存器传递
可以通过6个通用寄存器传递,除了EBP和ESP需要用于开辟栈帧,剩余的6个都可以用于参数传递
-
通过栈传递
参数太多,通用寄存器无法传递,只能通过栈来传递
-
通过参数列表传递
另外的方式是将参数封装成一个单数列表的结构。(builder模式传递)
3.4 不同特权级间的过程调用
为了保护操作系统,Inter在硬件级别支持4种的特权级,r0~r3, r0级权限最高,r3权限最小。but linux内核只使用了两种特权级(ring0和ring3)。下图是inter给的示意图,只是一个标准,厂商的实现不一定按这个来。
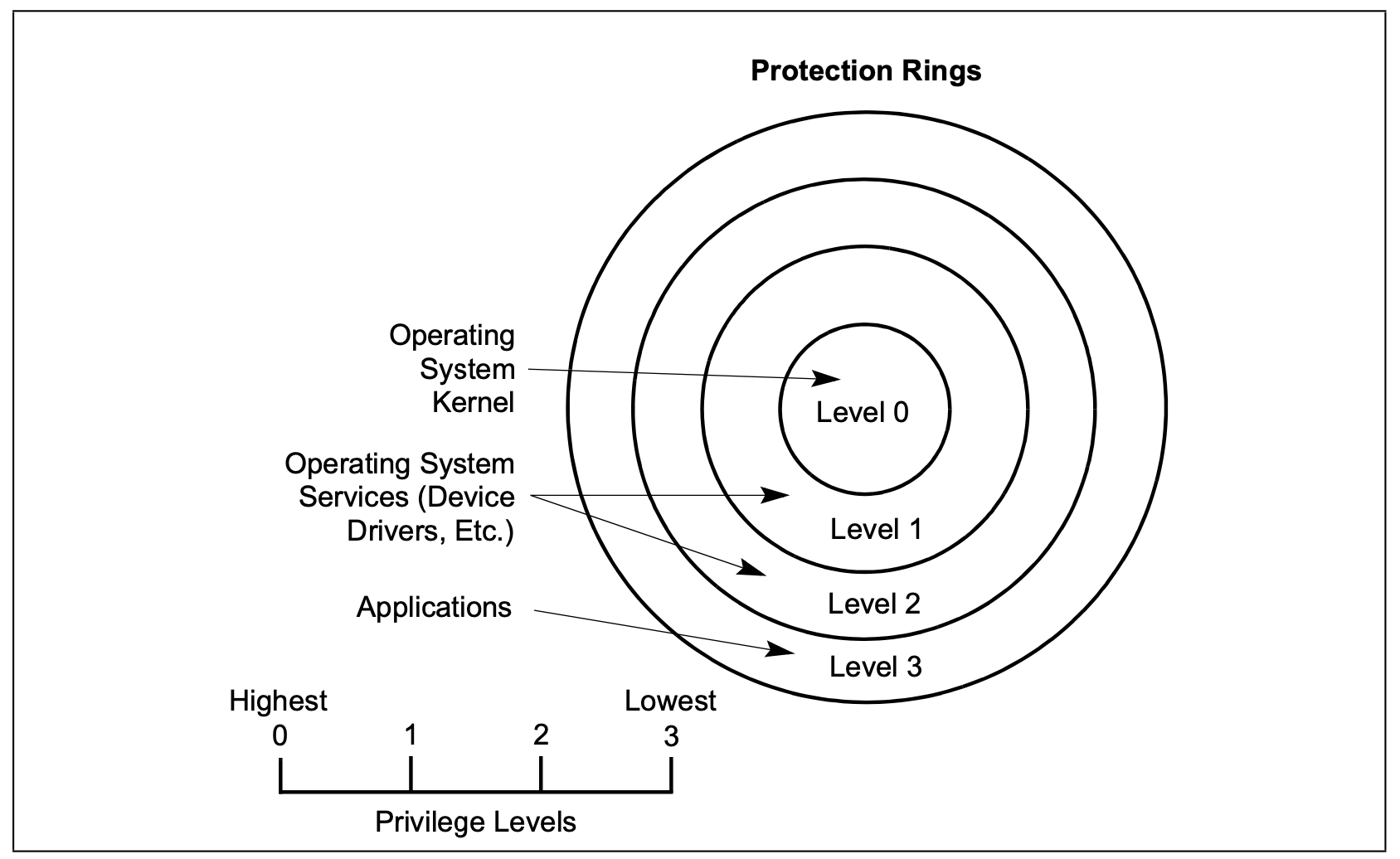
较低特权级的代码段要访问操作系统的较高特权级的模块,必须通过受保护的接口。这就是门(gate)。如果没有通过门或者没有访问权限,GP(general-protection exception (#GP) )会抛出。
通过门(gate)访问不同特权级的代码,跟FAR CALL 和 RET操作比较类似,有如下的不同:
- CALL指令中提供的段选择器引用了一种特殊的数据结构调用门描述符(call gate descriptpr), 除此之外,调用门描述符提供了下面的功能:
- 访问权限信息
- 调用过程的代码段的段选择器
- 代码段的偏移量
- 处理器切换一个新的栈执行被调用的过程。每一个特权级都有自己的栈。特权级3的栈存储在SS和ESP寄存器中,特权级别2、1和0堆栈的段选择器和堆栈指针存储在TSS(task state segment)段中(but linux不用)。
不同特权级的过程调用:
- 访问权限检查
- 临时保存SS,ESP,CS和EIP的内容
- 加载新栈的段选择器和栈指针(从TSS加载到SS和ESP寄存器中,来切换到新的栈帧)
- 将临时保存的SS,ESP的内容压入新的栈中
- 拷贝参数到新的栈中。调用们描述符确定有多少参数会拷贝到新的栈中
- 将临时保存的CS和EIP的内容压入新的栈中
- 加载新的代码段和程序计数器
- 在新的特权级下执行代码
特权级过程调用完成(执行了Return指令),处理器执行下面的活动
- 特权级检查
- 恢复CS和EIP
- 如果RET指令有参数,增加栈指针的值(释放栈空间)
- 恢复SS和ESP寄存器,即切换回原来的栈
- 如果RET指令有参数,增加栈指针的值(释放栈空间)
- 恢复调用过程的执行
4. 异常和中断
4.1 简介
中断和异常表明一个事件的发生,通常会导致正在执行的程序和任务转移到中断处理程序或者异常处理程序中执行。
- 中断:可以有硬件出发,也可以有软件出发(通过INT N 指令)。
- 异常:处理器检测到某个异常条件,异常就发生了
- 执行错误指令
- 硬件错误
中断和异常发生的时候会发生如下的执行序列
- 挂起当前运行的程序和任务
- 处理器执行中断处理程序或者异常处理程序
- 处理程序执行完成后,处理器恢复被中断的程序和任务。(不可恢复的中断和异常除外)
异常是异常控制流的一种形式,一部分有硬件实现,一部分由操作系统实现。异常是控制流中的突然变化,是用来响应处理器状态的变化。处理流程如图所示
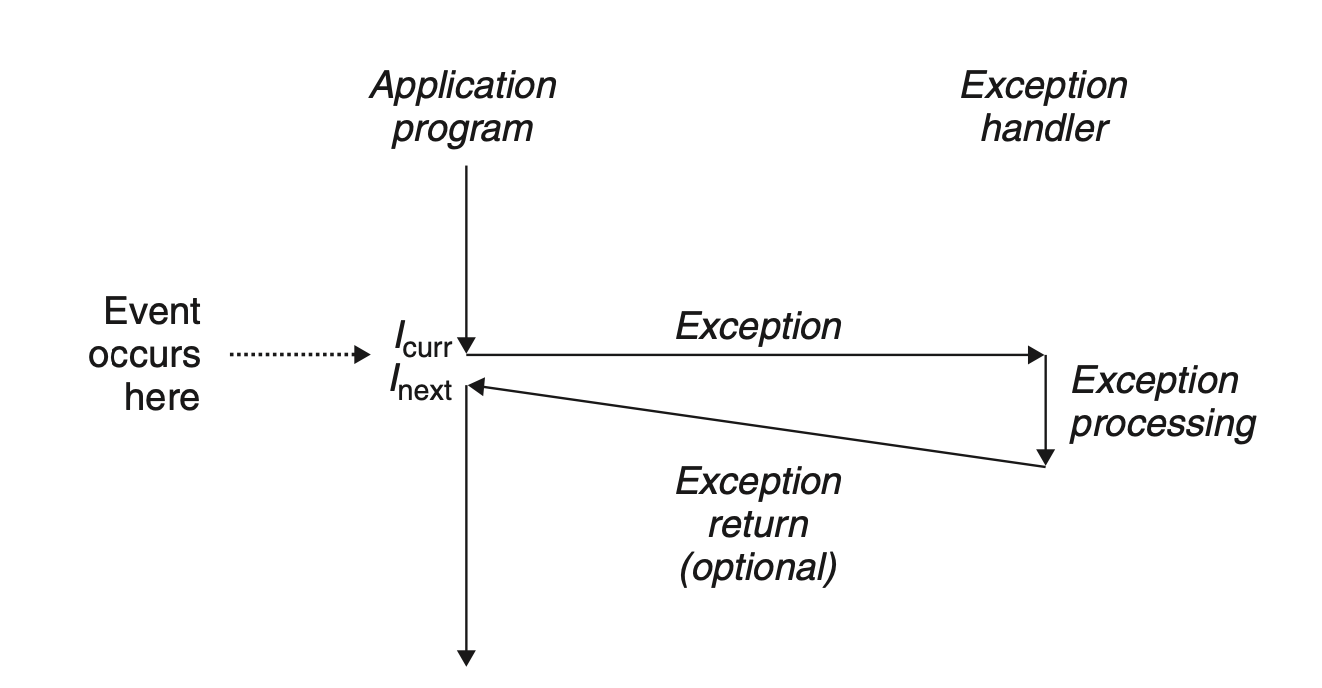
指令在执行完成后,CS:IP这对寄存器包含下一条将要执行指令的逻辑地址,在处理那条指令之前,控制单元会检查在运行前一条指令是否发生了中断或异常,如果发生了异常,会响应异常。通常将这些抽象为事件和事件响应程序。这些事件响应可能跟当前指令直接相关(如:内存缺页、算术越界、除以0),也有可能跟不跟当前指令直接相关(如:时钟中断)。
处理器响应中断和异常是使用的同一种方式。当中断或者异常信号发出,处理器会骨气当前正在执行的程序或者任务,同时切换到对应的handler中执行,响应这个信号。处理器访问handler过程通过IDT中的实体。当处理器完成处理中断或者异常后,程序的控制权返回到被中断的程序或者任务。
当处理器检测到异常发生时,都会执行间接的过程调用,通过IDTR寄存器查询对应的IDT表,最终找到对应的处理程序的地址。
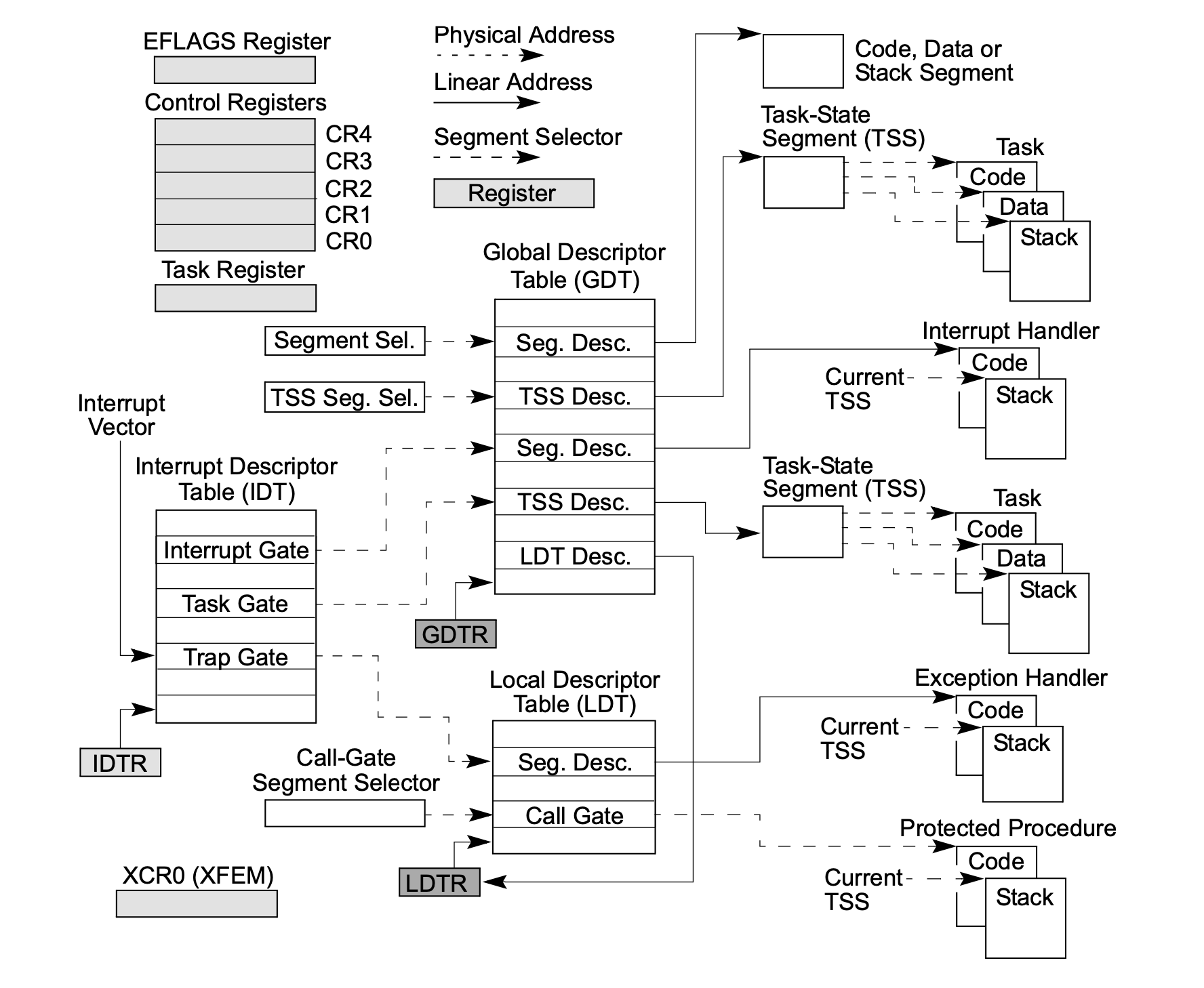
当异常处理程序执行完成之后,会根据异常的类型,执行下面的情况中的一个:
- 返回到发生异常的指令,重新执行
- 返回发生异常的下一条指令执行
- 处理程序终止被中断的程序
异常跟过程调用有很多类似的地方,也有一些重要的不同:
- 和过程调用一样,处理器在执行异常控制程序之前,会将返回值压入栈中,根据异常类型的不同,这个返回值可能是当前指令的地址,也有可能是当前执行指令的下一条指令压入栈中。
- 处理器也会将一些额外的信息压入栈中,以便中断处理程序处理完成之后可以恢复。例如:将EFLAGS寄存器的值压入栈中
- 控制从用户空间转移到内核空间的时候,所有的都会保存在内核栈中
- 异常处理程序运行在内核模式(ring0),所以它可以访问所有的系统资源
一旦硬件触发了异常, 剩下的事都是由软件程序(event handler)来完成的。在event handler执行完成之后,通常都是由ireturn指令返回到被中断的程序,此外还会恢复一些必要的信息,包含控制寄存器和数据寄存器,如果是用户空间程序发生的中断,也会恢复到用户态执行。
4.2 中断和异常的分类
-
异步执行(ASync)
- 中断(Interrupt)
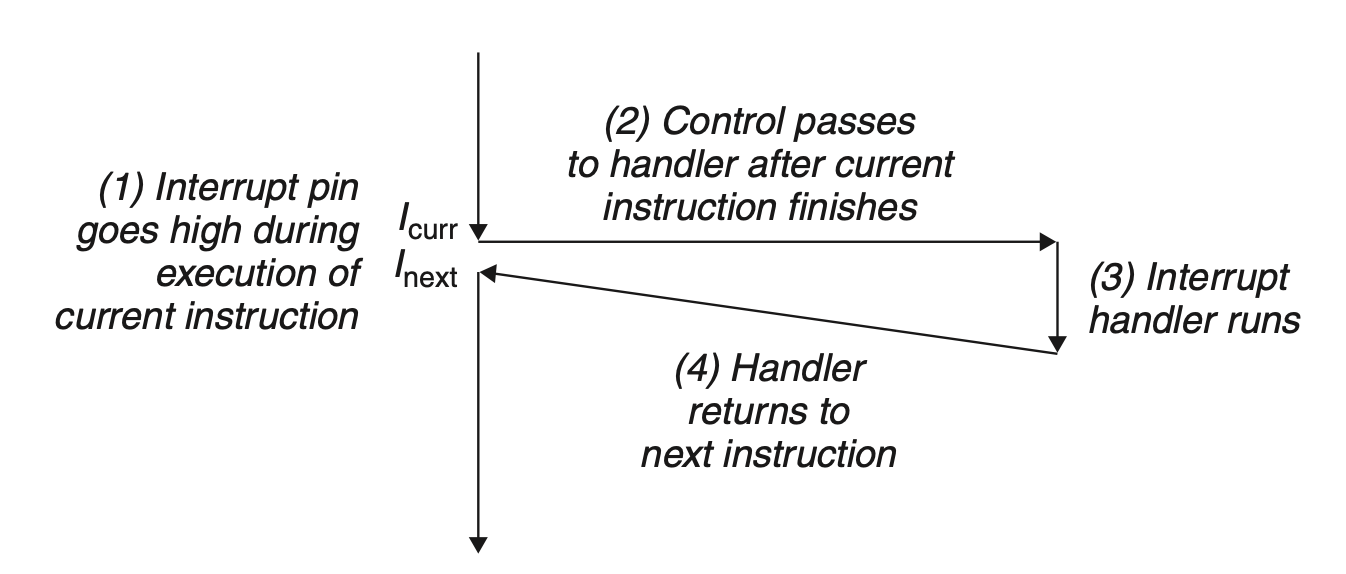
-
同步执行(Sync)
-
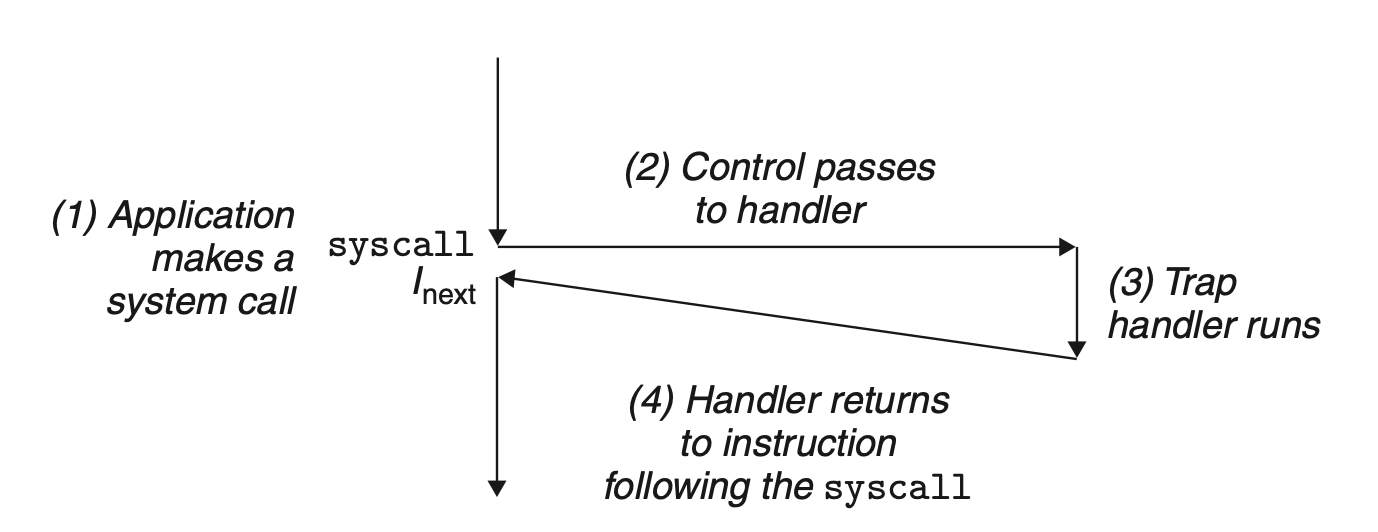
陷阱(Trap),最常用的就是内核提供给用户空间的接口,即系统调用(System Call)
陷阱处理程序(handler)的返回地址指向的是当前指令的下一条指令
-
-
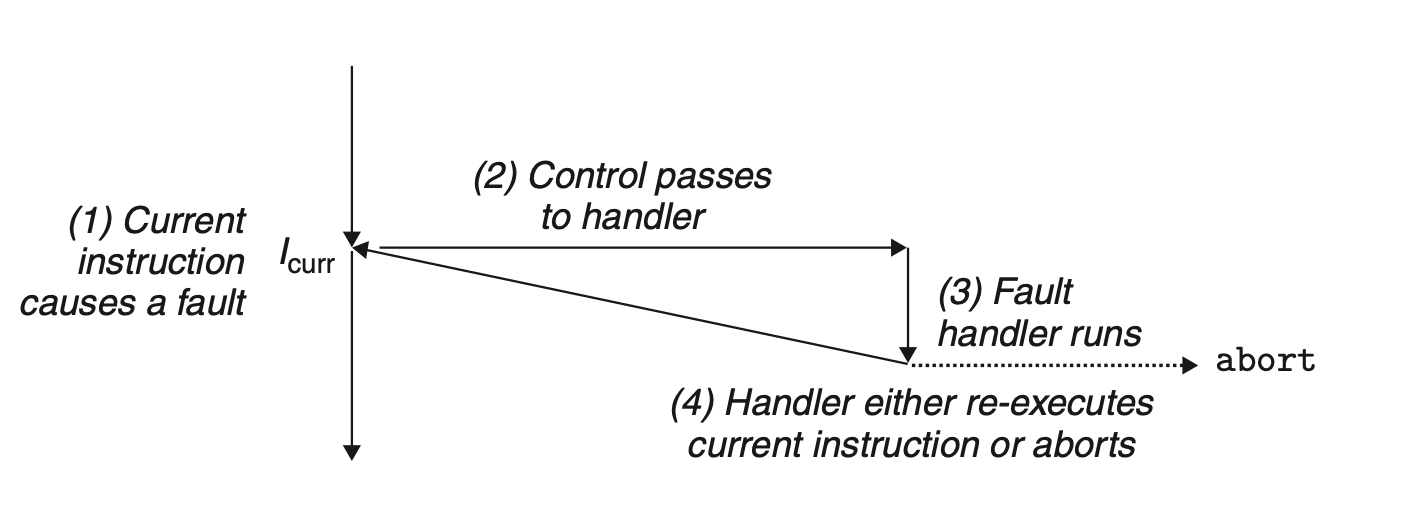
故障(Falt):如缺页中断
故障产生后,处理器存储(执行故障指令之前)的机器状态。处理程序(handler)的返回值地址指向的是当前发生故障的指令,而不是下一条指令。
.png)
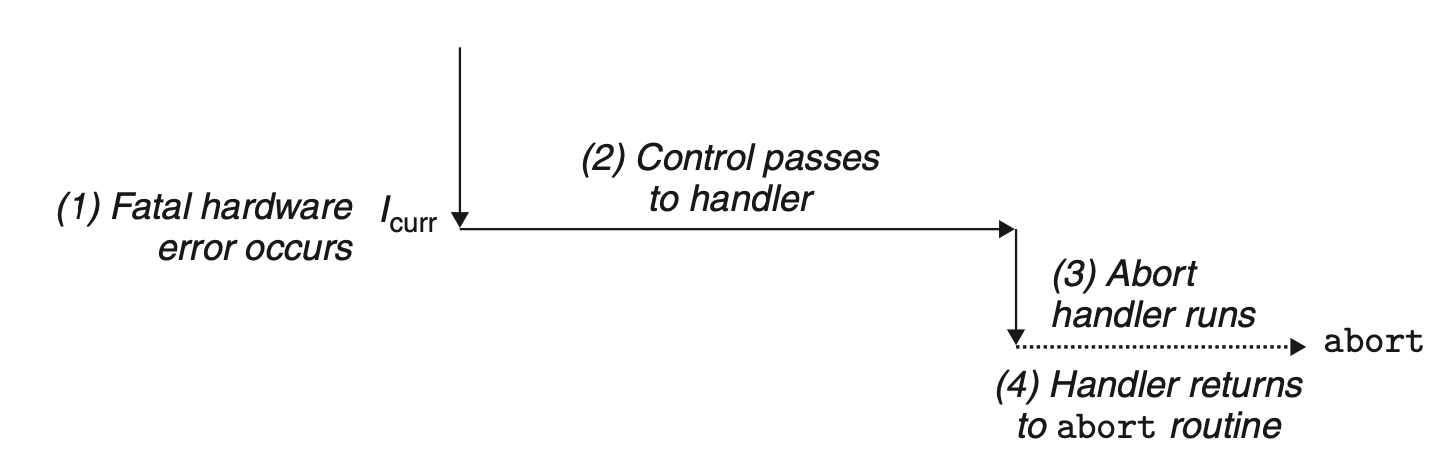
- 终止(Abort):不可恢复的异常,硬件错误、系统表的值不一致或者不合法
4.3 异常和中断向量
在Inter 64 和 IA-32的架构体系中,每一个中断和异常都需要一个处理函数来响应,给每一个类型的中断和异常定义了一个编号,这个编号就是中断向量(异常向量)。处理器通过中断向量到中断表述符表(IDT,Interrupt De scription table)中查询对应的处理函数(IDT记录了GDT表项的偏移量,GDT的表项记录了处理函数的入口),IDTR寄存器中记录了IDT的首地址。
-
中断向量的定义:
- 0~31为Inter保留的,不是所有的向量都定义了处理行数
- 32~255为用户自定义的中断,作为扩展

内核中的定义如下所示:
void __init trap_init(void)
{
set_trap_gate(0,÷_error);
set_intr_gate(1,&debug);
set_intr_gate(2,&nmi);
set_system_intr_gate(3, &int3); /* int3-5 can be called from all */
set_system_gate(4,&overflow);
set_system_gate(5,&bounds);
set_trap_gate(6,&invalid_op);
set_trap_gate(7,&device_not_available);
set_task_gate(8,GDT_ENTRY_DOUBLEFAULT_TSS);
set_trap_gate(9,&coprocessor_segment_overrun);
set_trap_gate(10,&invalid_TSS);
set_trap_gate(11,&segment_not_present);
set_trap_gate(12,&stack_segment);
set_trap_gate(13,&general_protection);
set_intr_gate(14,&page_fault);
set_trap_gate(15,&spurious_interrupt_bug);
set_trap_gate(16,&coprocessor_error);
set_trap_gate(17,&alignment_check);
#ifdef CONFIG_X86_MCE
set_trap_gate(18,&machine_check);
#endif
set_trap_gate(19,&simd_coprocessor_error);
}
有没有发现linux和caapp为何如此类似。究其根源,他们都来自Inter开发手册的定义
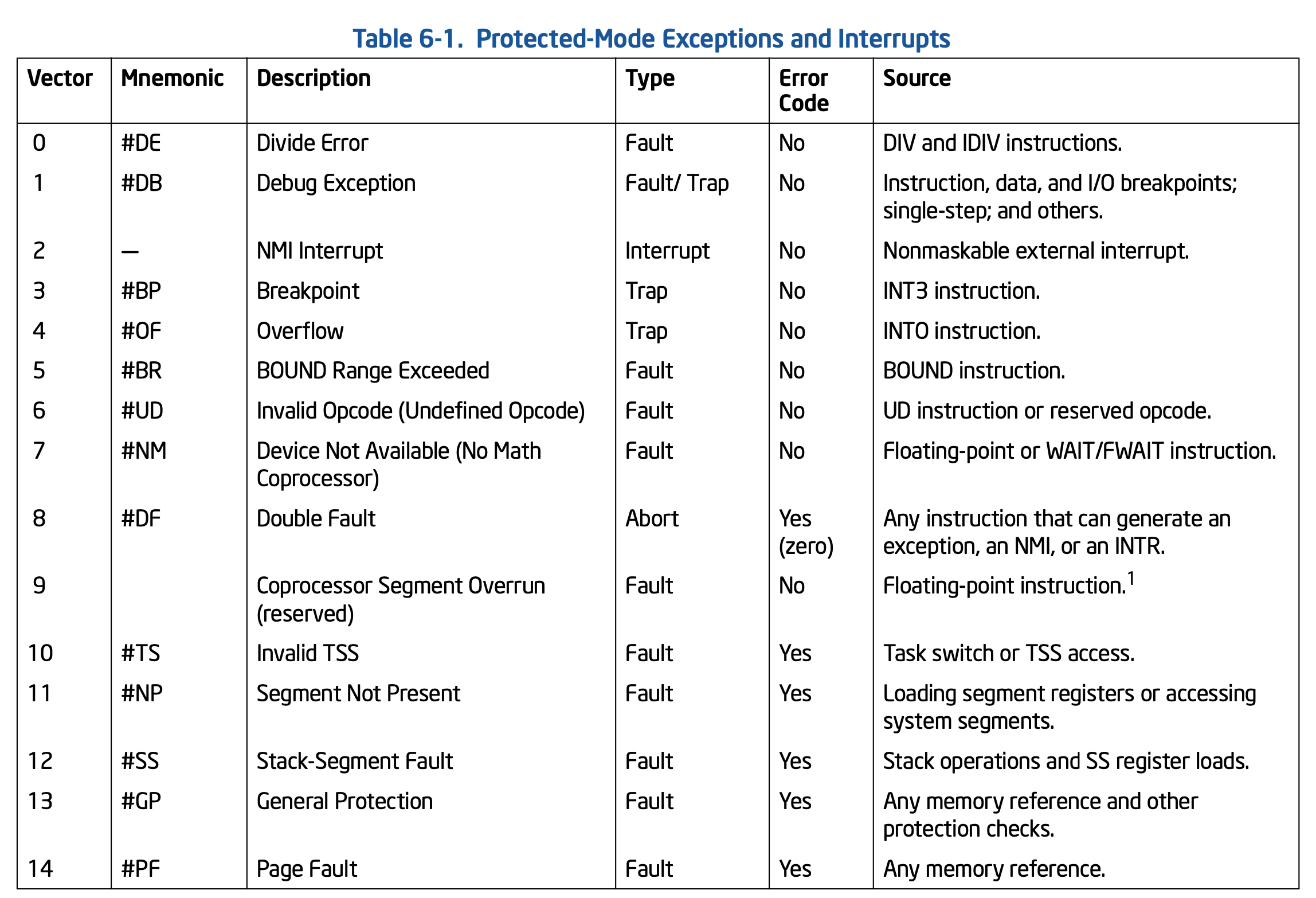
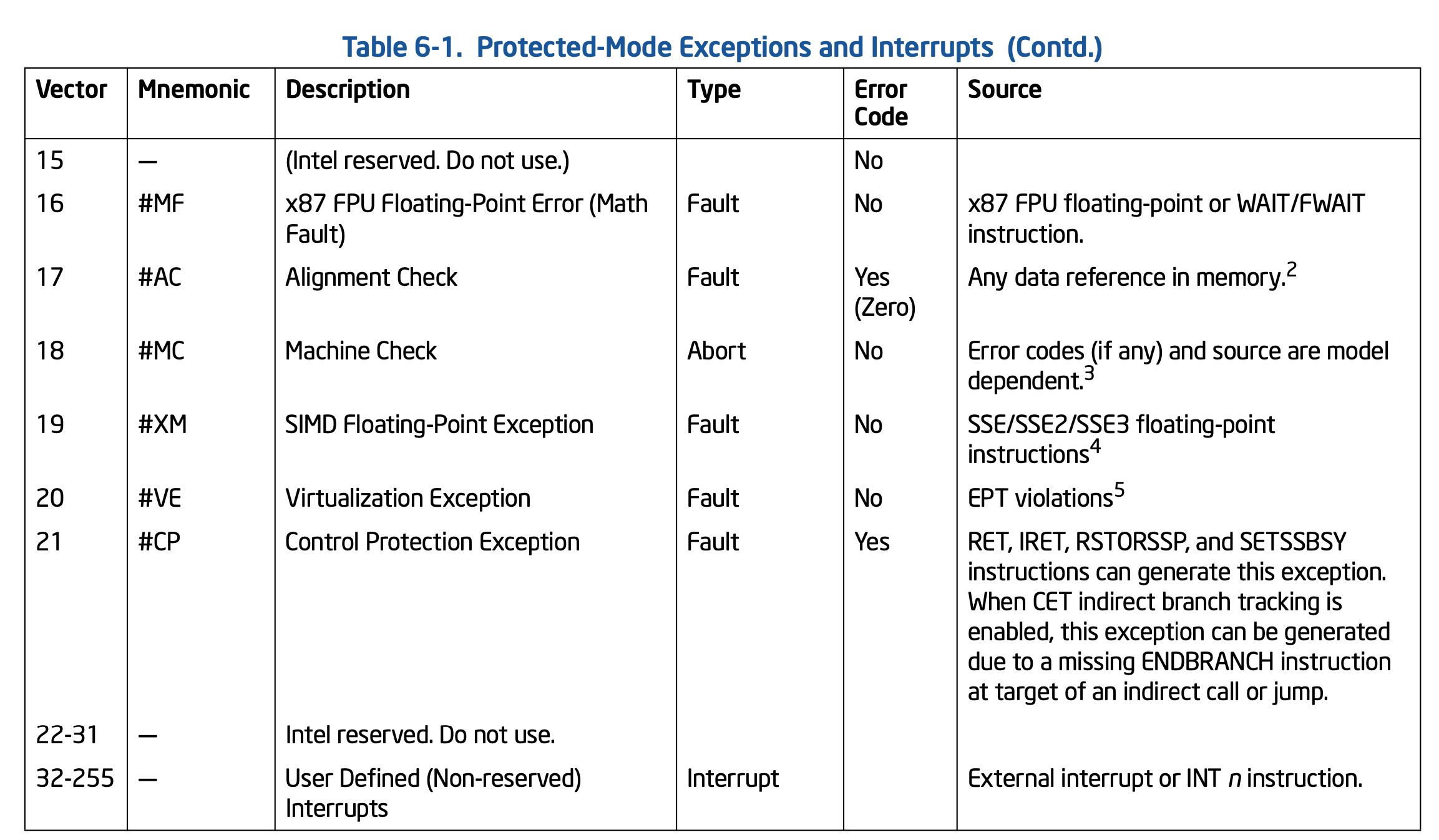
Linux/x86-64 内置的系统调用(INT 80):
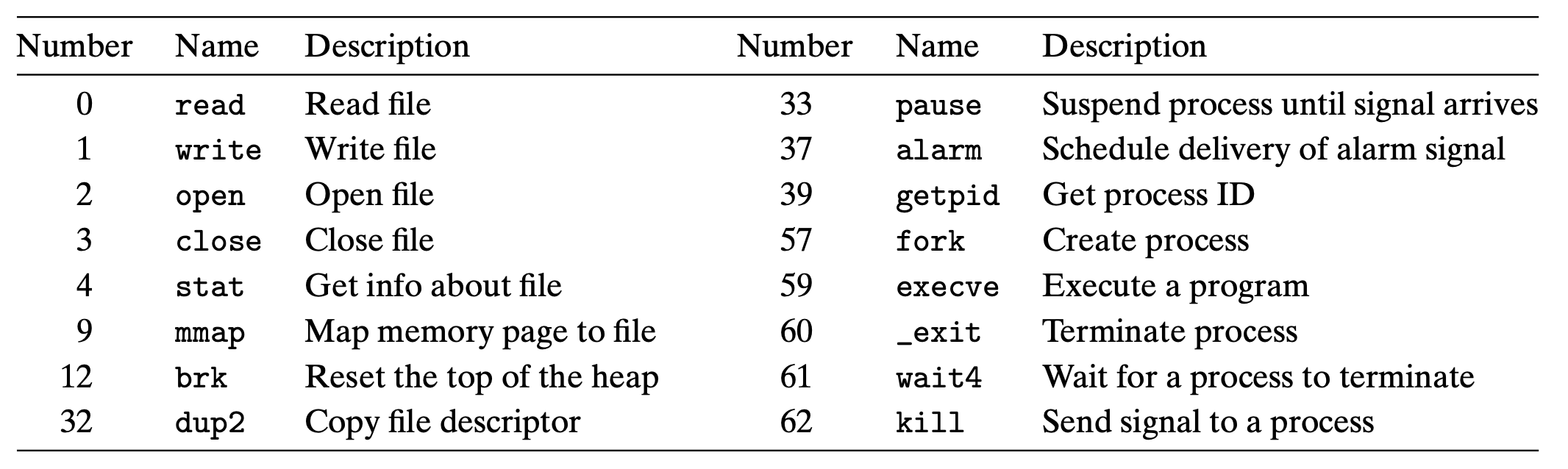
#define SYSCALL_VECTOR 0x80
// 从这里,很明显,所谓的软件中断,中断向量都是0x80
set_system_gate(SYSCALL_VECTOR,&system_call);
注意,定义的中断编号,肯定是在操作系统维护的,并不会再IDTR寄存器中维护。
- 中断源
- 硬件产生的中断
- 软件产生的中断(INT N指令)
- 异常源:
- 程序错误异常
- 软件产生的异常(INT N指令)
- 机器检测异常
4.4 中断和异常处理函数的调用
调用中断和异常处理函数跟不同特权级之间的跳转比较类似。向量在IDT中会指向以下两种类型的门:
- 中断门(interrupt gate)
- 陷阱门(trap gate)
中断门和陷阱门提供下面的信息:
- 访问权限
- 处理函数对应代码的段选择子和便宜量
中断处理函数执行的时候,会清除中断标记位,避免交互影响。陷阱门不会改变标记位。
4.5 启用&禁用中断
处理器可以阻止一些中断的产生,依赖于EFLAGS寄存器的状态(IF & RF)
-
标记可屏蔽中断
IF 标记可以禁用可屏蔽硬件中断的服务,当IF Flag被清除,处理器禁用内部的中断请求;当IF Flag被设置,可以正常的接收中断请求。但是IF标记不会影响NMI(不可屏蔽中断)和处理器产生的异常。
STI:设置中断标记位,开始响应中断。CLI清除中断标记位,不会再响应中断
-
标记debug断点
当RF标记,设置后,它会防止指令在断点处生成调试异常(#DB);清除时,指令将再断点处生成调试异常。RF标志的主要功能是防止处理器在断点上进入调试异常。
-
切换栈时标记中断和异常
为了切换到不同的栈段,通常会使用一组指令如:
MOV SS, AX MOV ESP, StackTop如果中断和异常发生在这两条指令之间(段选择子已经加载到SS寄存器,但是ESP还没有加载程序计数器),这会导致指向中断或者异常处理函数的栈空间的逻辑地址不一致。为了避免这种情形,处理器防止中断、debug异常和单步的陷阱异常,直到到达下一条指令边界。
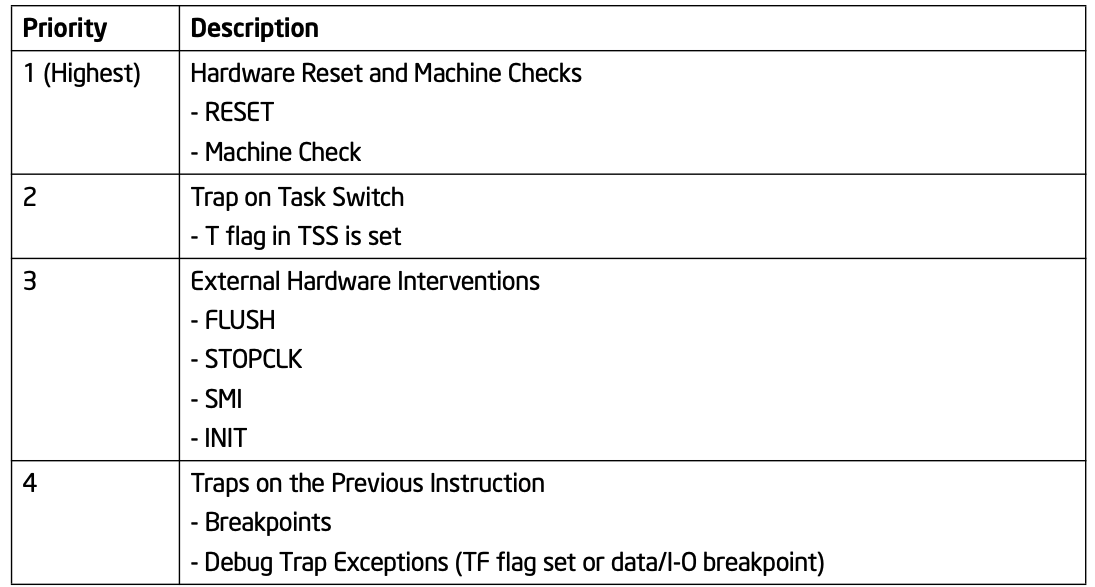
4.6 处理器响应中断和异常的优先级
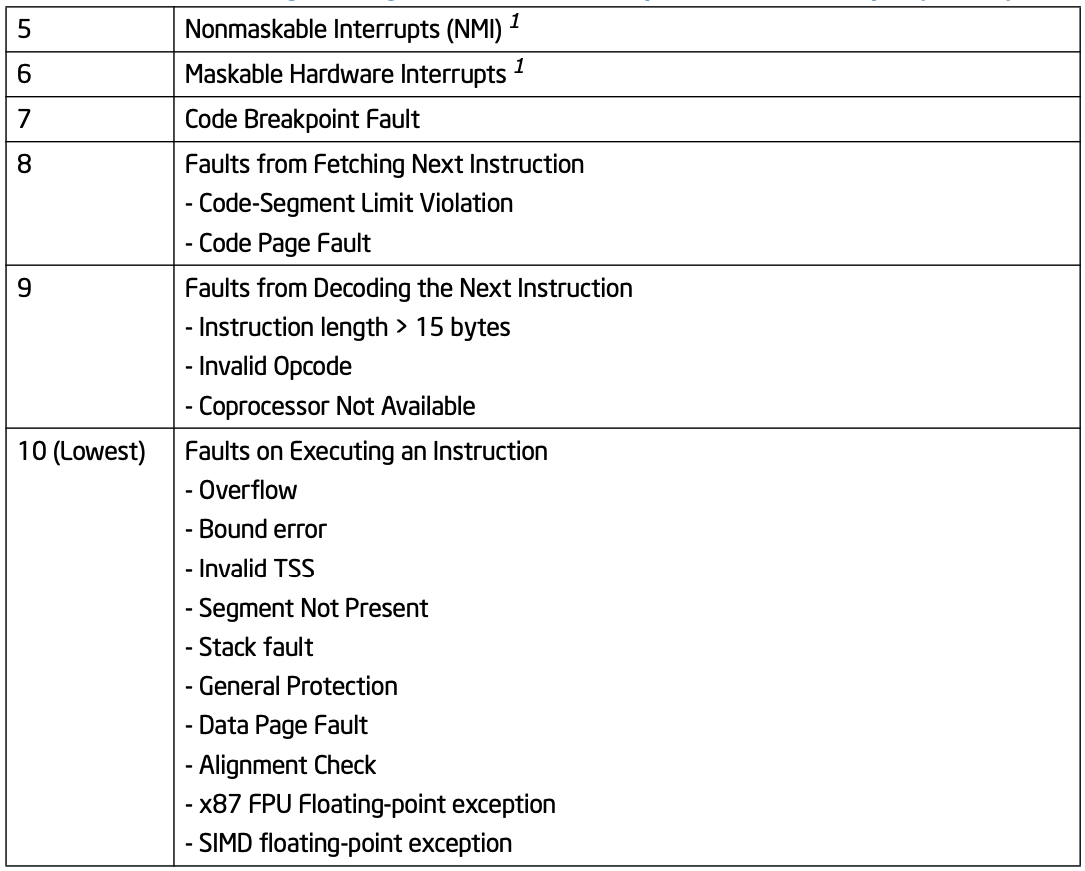
4.6 IDT(INTERRUPT DESCRIPTOR TABLE)
- 每种异常或者中断向量通过IDT的一个表项与一个门描述符管量。
- IDT是一个8字节的描述符。
- IDT的基地址必须跟8字节对齐,缓存行增加性能
- IDTR寄存器通过32位保存IDT的基地址,中断门描述符位包含两项,每项需要8字节对齐,所以需要16字节的门描述符,所以要保存256个中断,limit需要16位。
- 16位保存IDT的最大值。操作系统启动时,LIDT存储IDT基地址到IDTR(特权级只能是0), SIDT的特权级可以是任意的。
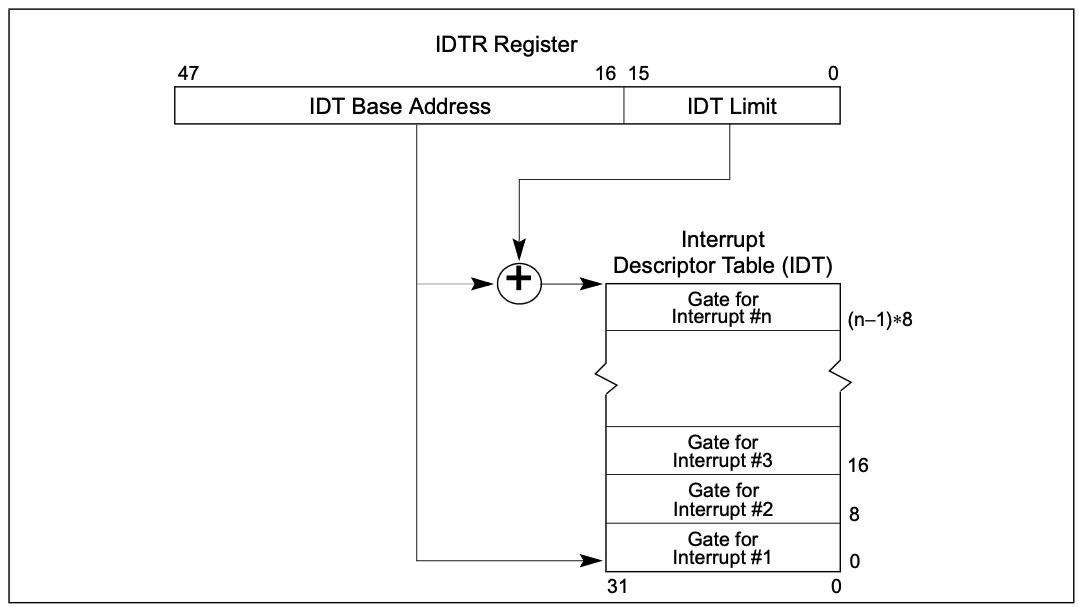
IDT包含三种门描述符:
- Task-gate描述符
- Interrupt-gate描述符
- Trap-gate描述符
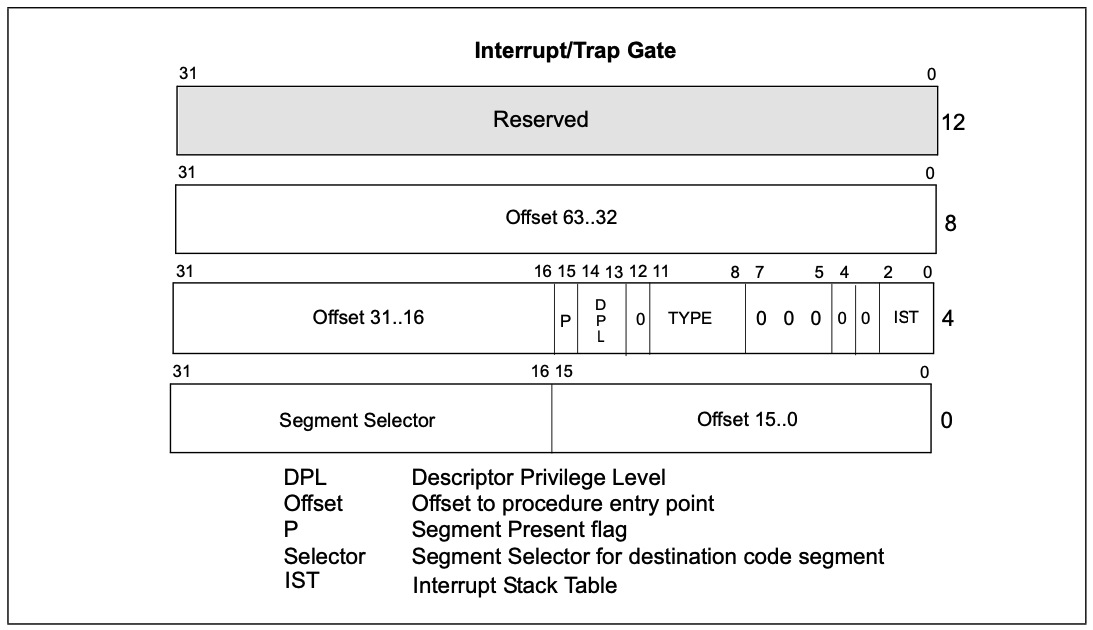
粗看下Linux的IDT实现:
// 16byte gate
struct gate_struct {
u16 offset_low;
u16 segment;
unsigned ist : 3, zero0 : 5, type : 5, dpl : 2, p : 1;
u16 offset_middle;
u32 offset_high;
u32 zero1;
} __attribute__((packed));
// 注意:GATE_INTERRUPT为14,跟图中描述正好匹配1110
static inline void set_intr_gate(int nr, void *func)
{
_set_gate(&idt_table[nr], GATE_INTERRUPT, (unsigned long) func, 0, 0);
}
// 中断们,特权级为0
static inline void set_intr_gate_ist(int nr, void *func, unsigned ist)
{
_set_gate(&idt_table[nr], GATE_INTERRUPT, (unsigned long) func, 0, ist);
}
// 系统调用门,特权级为3
static inline void set_system_gate(int nr, void *func)
{
_set_gate(&idt_table[nr], GATE_INTERRUPT, (unsigned long) func, 3, 0);
}
5. 信号
什么是信号:系统中某些类型的事件发生了,会通知系统的进程。Linux中支持的信号如图所示:
每一个异常类型是一个系统时间,硬件的异常是被内核的异常处理器处理的(IDT,GDT),正常情况下对用户空间的进程是不可见的。信号暴露了一些事件给用户空间。例如:除以0的操作,内核发送一个SIGFPE信号给到用户空间。
信号的传输通常分成两部分:
- 发送信号:两种方式:(1)内核检测到系统事件(除以0,进程终止)
- 接受信号:目标进程接受到信号,进程对信号做出相应:忽略,终止,捕获信号执行一个用户自定义的信号处理器(signal handler)
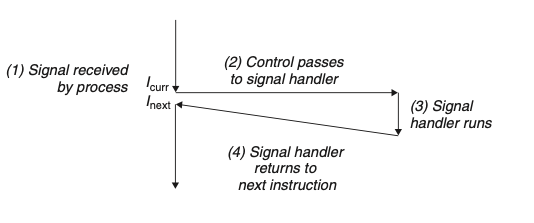
在任何时刻,针对某种类型的信号最多只有一个信号处于pending状态。如果有一个信号在已经在pending状态了,后面的相同信号会被忽略。
如何实现只有一个信号在pending状态呢?hashset or 位图?以kill命令查看源码实现
asmlinkage long
sys_kill(int pid, int sig)
{
// 信号的结构,此处在栈上开辟空间
struct siginfo info;
info.si_signo = sig;
info.si_errno = 0;
info.si_code = SI_USER;
info.si_pid = current->tgid;
info.si_uid = current->uid;
return kill_something_info(sig, &info, pid);
}
static int kill_something_info(int sig, struct siginfo *info, int pid)
{
if (!pid) {
// 为0的时候,会kill调当前进程
return kill_pg_info(sig, info, process_group(current));
} else if (pid == -1) {
int retval = 0, count = 0;
struct task_struct * p;
read_lock(&tasklist_lock);
// 如果是传入-1, 会kill所有的子进程
for_each_process(p) {
if (p->pid > 1 && p->tgid != current->tgid) {
int err = group_send_sig_info(sig, info, p);
++count;
if (err != -EPERM)
retval = err;
}
}
read_unlock(&tasklist_lock);
return count ? retval : -ESRCH;
} else if (pid < 0) {
return kill_pg_info(sig, info, -pid);
} else {
return kill_proc_info(sig, info, pid);
}
}
// 发送信号给对应的进程
int
kill_proc_info(int sig, struct siginfo *info, pid_t pid)
{
int error;
struct task_struct *p;
read_lock(&tasklist_lock);
// 查找进程的task
p = find_task_by_pid(pid);
error = -ESRCH;
if (p)
error = group_send_sig_info(sig, info, p);
read_unlock(&tasklist_lock);
return error;
}
int group_send_sig_info(int sig, struct siginfo *info, struct task_struct *p)
{
unsigned long flags;
int ret;
// 检查权限
ret = check_kill_permission(sig, info, p);
if (!ret && sig && p->sighand) {
spin_lock_irqsave(&p->sighand->siglock, flags);
ret = __group_send_sig_info(sig, info, p);
spin_unlock_irqrestore(&p->sighand->siglock, flags);
}
return ret;
}
static int
__group_send_sig_info(int sig, struct siginfo *info, struct task_struct *p)
{
int ret = 0;
handle_stop_signal(sig, p);
if (((unsigned long)info > 2) && (info->si_code == SI_TIMER))
/*
* Set up a return to indicate that we dropped the signal.
*/
ret = info->si_sys_private;
/* Short-circuit ignored signals. */
if (sig_ignored(p, sig))
return ret;
if (LEGACY_QUEUE(&p->signal->shared_pending, sig))
/* This is a non-RT signal and we already have one queued. */
return ret;
/*
* 这里是pending 信号的核心方法
*/
ret = send_signal(sig, info, p, &p->signal->shared_pending);
if (unlikely(ret))
return ret;
__group_complete_signal(sig, p);
return 0;
}
static int send_signal(int sig, struct siginfo *info, struct task_struct *t,
struct sigpending *signals)
{
// 省略若干代码
out_set:
sigaddset(&signals->signal, sig);
return ret;
}
//位图的实现,这里一段汇编代码
static __inline__ void sigaddset(sigset_t *set, int _sig)
{
// 将set 的第_sig-1 位设置为1
__asm__("btsl %1,%0" : "=m"(*set) : "Ir"(_sig - 1) : "cc");
}
什么时候可以处理接收的信号?
当进程从内核态切换到用户态时,进程会检测非阻塞&pending状态的信号(unblocked & pending)。如果是空的信号集合(正常情况都是),内核将控制权转移到下一条指令(cs:ip指向的地址)。如果信号的集合不是空的,内核选择一些在集合中的信号,交给进程处理,进程处理完信号处理器时,将执行下一条指令。信号都有一些默认的行为:进程可以选择处理或者忽略一些信号,but,某些信号时内核定义的不可忽略的信号。信号处理器有一些默认行为,可以被修改。
信号是可以被中断的
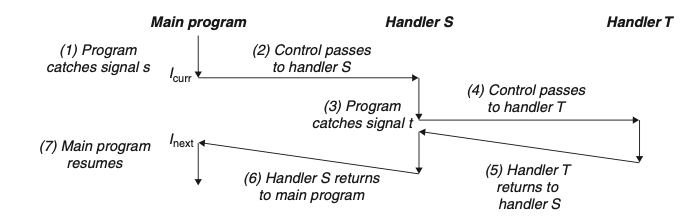
6. 非本地跳转
C提供了非本地跳转,setjmp 和longjmp。setjmp函数,保存当前调用的运行时环境,通过longjmp,return 0.调用环境包含程序计数器,栈指针,通用寄存器。longjmp用于恢复之前设置的环境变量。可能会产生内存泄漏,因为有很多释放资源的代码没有执行。