介绍
梯度下降算法是一种迭代算法,用于找到目标函数(成本函数)的 全局最小值。GD算法的分类是针对准确性和耗时因素的,下面将详细讨论。该算法广泛用于机器学习中以使功能最小化。
为什么要使用梯度下降算法?
我们使用梯度下降来最小化J(?)之类的函数。在梯度下降中,我们的第一步是通过某个值初始化参数,并不断更改这些值,直到达到全局最小值为止。在此算法中,我们在每次迭代中计算成本函数的导数,并使用以下公式同时更新参数的值:
其中“?” 是学习率。
在讨论梯度下降时,我们将在本文中将线性回归作为算法示例,尽管这些思想也适用于其他算法,例如
- 逻辑回归
- 神经网络
在线性回归中,我们有一个假设函数:(H(X)= theta_0 + theta_1X_1 + ldots + theta_nX_n )H(X)=θ0+θ1个X1个+ … +θñXñ
其中( theta_0, theta_1, ldots, theta_n )是参数,而(X_1, ldots,X_n )是输入要素。为了求解模型,我们尝试找到参数,以使假设以最佳方式拟合模型。要找到参数的值,我们建立成本函数J(( theta ))并使用梯度下降以最小化此功能。θ0,θ1个,… ,θñ 是参数和 X1个,… ,Xñ是输入功能。为了求解模型,我们尝试找到参数,以使假设以最佳方式拟合模型。要找到参数的值,我们建立成本函数J(θ),并使用梯度下降来最小化此功能。
 成本函数(普通最小二乘误差)
成本函数(普通最小二乘误差)![]() 成本函数的梯度
成本函数的梯度

参数和成本函数之间的关系图
梯度下降算法如何工作?
以下伪代码说明了工作原理:
- 用一些值初始化参数。(说( theta_1 = theta_2 = ldots = theta_n = 0 ))θ1个=θ2= … =θñ= 0)
- 不断迭代地更改这些值,以使其最小化目标函数J(( theta ))。θ)。
梯度下降算法的类型
根据我们如何使用数据来计算梯度下降中成本函数的导数,定义了梯度下降的各种变体。根据使用的数据量,算法的时间复杂度和准确性会有所不同。
- 批次梯度下降
- 随机梯度下降
- 小批量梯度下降
批次梯度下降如何工作?
这是梯度下降的第一种基本类型,其中我们使用完整的数据集来计算成本函数的梯度。
由于我们需要计算整个数据集的梯度以仅执行一次更新,因此批量梯度下降可能非常缓慢,并且对于内存中不适合的数据集来说很棘手。用任意值初始化参数后,我们使用以下关系式计算成本函数的梯度: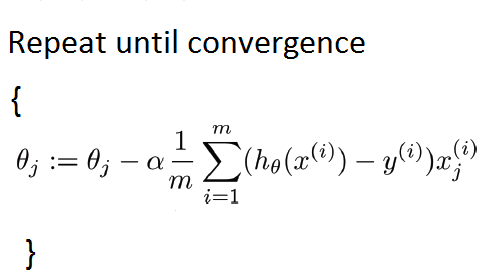 其中“ m”是训练示例的数量。
其中“ m”是训练示例的数量。
- 如果您有300,000,000条记录,则需要将所有记录从磁盘读入内存,因为您无法将它们全部存储在内存中。
- 在计算了一次迭代的sigma之后,我们移动了一步。
- 然后对每个步骤重复一次。
- 这意味着收敛需要很长时间。
- 尤其是因为磁盘I / O无论如何通常都是系统瓶颈,因此不可避免地需要进行大量 读取。
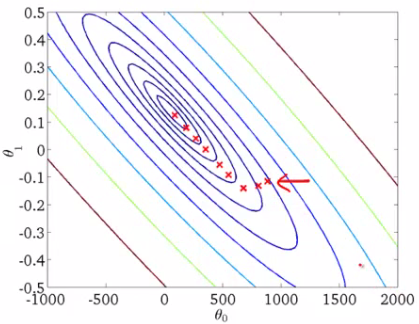
等高线图:每次迭代后批次梯度下降不适用于庞大的数据集。以下代码说明了如何在python中实现梯度下降。
import numpy as np
import random
def gradient_descent(alpha, x, y, ep=0.0001, max_iter=10000):
converged = False
iter = 0
m = x.shape[0] # number of samples
# initial theta
t0 = np.random.random(x.shape[1])
t1 = np.random.random(x.shape[1])
# total error, J(theta)
J = sum([(t0 + t1*x[i] - y[i])**2 for i in range(m)])
# Iterate Loop
while not converged:
# for each training sample, compute the gradient (d/d_theta j(theta))
grad0 = 1.0/m * sum([(t0 + t1*x[i] - y[i]) for i in range(m)])
grad1 = 1.0/m * sum([(t0 + t1*x[i] - y[i])*x[i] for i in range(m)])
# update the theta_temp
temp0 = t0 - alpha * grad0
temp1 = t1 - alpha * grad1
# update theta
t0 = temp0
t1 = temp1
# mean squared error
e = sum( [ (t0 + t1*x[i] - y[i])**2 for i in range(m)] )
if abs(J-e) <= ep:
print 'Converged, iterations: ', iter, '!!!'
converged = True
J = e # update error
iter += 1 # update iter
if iter == max_iter:
print 'Max interactions exceeded!'
converged = True
return t0,t1
随机梯度下降如何工作?
批梯度下降法证明是一种较慢的算法。因此,为了加快计算速度,我们更喜欢使用随机梯度下降法。
算法的第一步是将整个训练集随机化。然后,对于每个参数的更新,我们在每次迭代中仅使用一个训练示例来计算成本函数的梯度。由于它在每次迭代中都使用一个训练示例,因此对于较大的数据集,该算法会更快。在SGD中,可能无法达到准确性,但结果的计算速度更快。
用任意值初始化参数后,我们使用以下关系式计算成本函数的梯度:

其中,“ m”是训练示例的数量
以下是随机梯度下降的伪代码:
- 在内部循环中:
- 第一步:选择第一个训练示例并使用该示例更新参数,然后选择第二个示例,依此类推
- 采取第二步:选择第二个训练示例并使用该示例更新参数,以此类推。
- 现在在算法中采取第三步…n步。
- 直到达到全球最低要求。
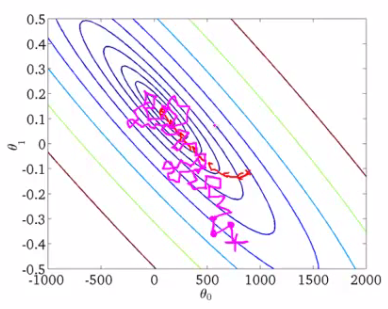
SGD从未像批次梯度下降那样真正收敛,但是最终在接近全局最小值的某个区域徘徊。
小型批量梯度下降如何工作?
迷你批处理算法是最有利且使用最广泛的算法,它使用一批“ m”个训练示例来生成精确,快速的结果。在小型批处理算法中,而不是使用完整的数据集,在每次迭代中,我们使用一组称为“ 批处理 ”的“ m”个训练示例来计算成本函数的梯度。常见的迷你批处理大小在50到256之间,但是会因不同的应用而有所不同。
这样,算法
- 减少参数更新的方差,这可以导致更稳定的收敛。
- 可以利用高度优化的矩阵,从而使梯度计算非常有效。
用任意值初始化参数后,我们使用以下关系式计算成本函数的梯度: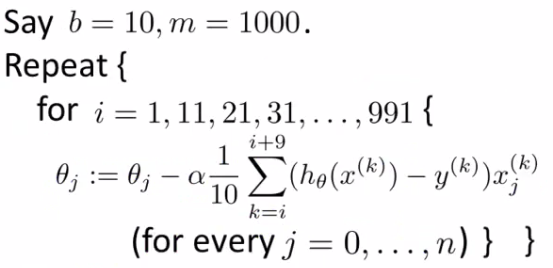
其中“ b”是批数,“ m”是数训练示例。
要记住的一些重要点是:
- 同时更新参数-
在实施算法时,应同时完成参数( theta_1 = theta_2 = ldots = theta_n = 0 )的更新。这意味着,在参数值期间,应先将其存储在某个临时变量中,然后再分配给参数。θ1个=θ2= … =θñ= 0应该同时完成。这意味着,在参数值期间,应先将其存储在某个临时变量中,然后再分配给参数。 -
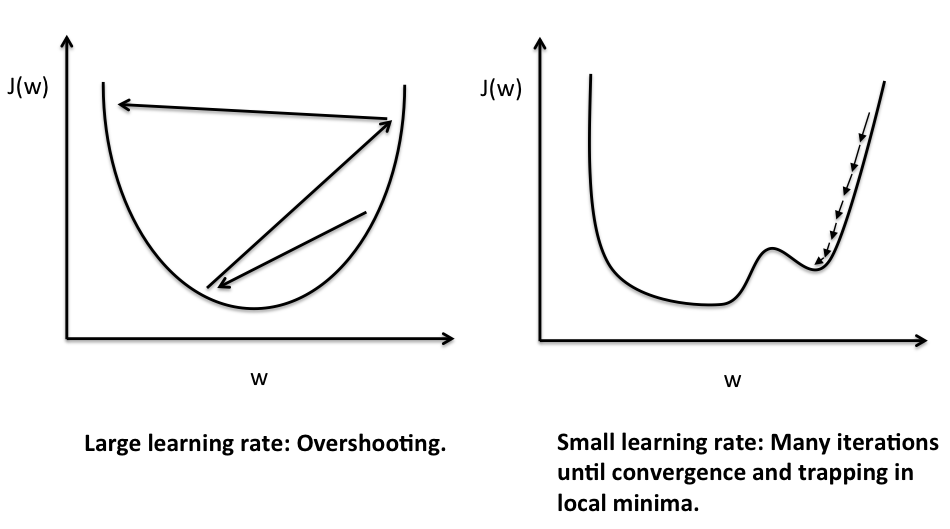
- 学习率'?'-
?是控制我们的算法执行多大步幅的关键参数。- 如果?太大的算法会采取更大的步骤并且算法可能无法收敛。
- 如果呢?如果规模较小,那么步伐和步伐将趋于一致。
 检查梯度下降的工作-
检查梯度下降的工作-
- 在该迭代次数之后绘制迭代次数与成本函数值之间的曲线。此图有助于确定梯度下降是否正常工作。
“ J应在每次迭代后减小,并应在某些迭代后变为常数(或收敛)。”
上面的陈述是因为在每次梯度下降迭代之后?取值使J移向深度,即J的值在每次迭代后减小。
- 梯度下降随学习率的变化-

摘要
在本文中,我们了解了梯度下降算法的基本知识及其类型。这些优化算法最近已在神经网络中广泛使用。因此,学习很重要。下图显示了所有3种梯度下降算法的快速比较:

- 学习率'?'-