接前几章,已经实现了前端3D地球的展示,本章开始完成一个疫情数据的爬虫
爬取数据使用python爬虫实现
1 运行环境
1 python 3.7
2 scrapy 2.0.1
3 selenium
4 chromedirver 选择适合自己浏览器的 http://npm.taobao.org/mirrors/chromedriver/
5 phantomjs
6 mysql / mongodb pymsql / pymongodb
2 开始
疫情数据最及时的是从国家卫健委的网站获取,本例只是作为demo联系,这里使用qq的疫情地图页面进行数据爬取,参考链接
https://news.qq.com/zt2020/page/feiyan.htm#/global?ct=United%20States&nojump=1
安装第一节的环境和包
2.1 创建爬虫项目
使用scrapy命令创建爬虫项目,会创建一个爬虫的项目文件夹,会有一个爬虫项目的模板,执行命令
F:
cd F:mygithubVDDataServer
scrapy startproject COVID19
2.2 创建spider
创建一个爬虫spider文件
cd COVID19
scrapy genspider Covid19Spider news.qq.com
一个爬虫的项目就完成了,项目结构如下
3 分析爬取页面
打开https://news.qq.com/zt2020/page/feiyan.htm#/global?ct=United%20States&nojump=1疫情地图页面,可以看到有国内和海外的疫情数据,这里我们只爬取疫情的列表数据
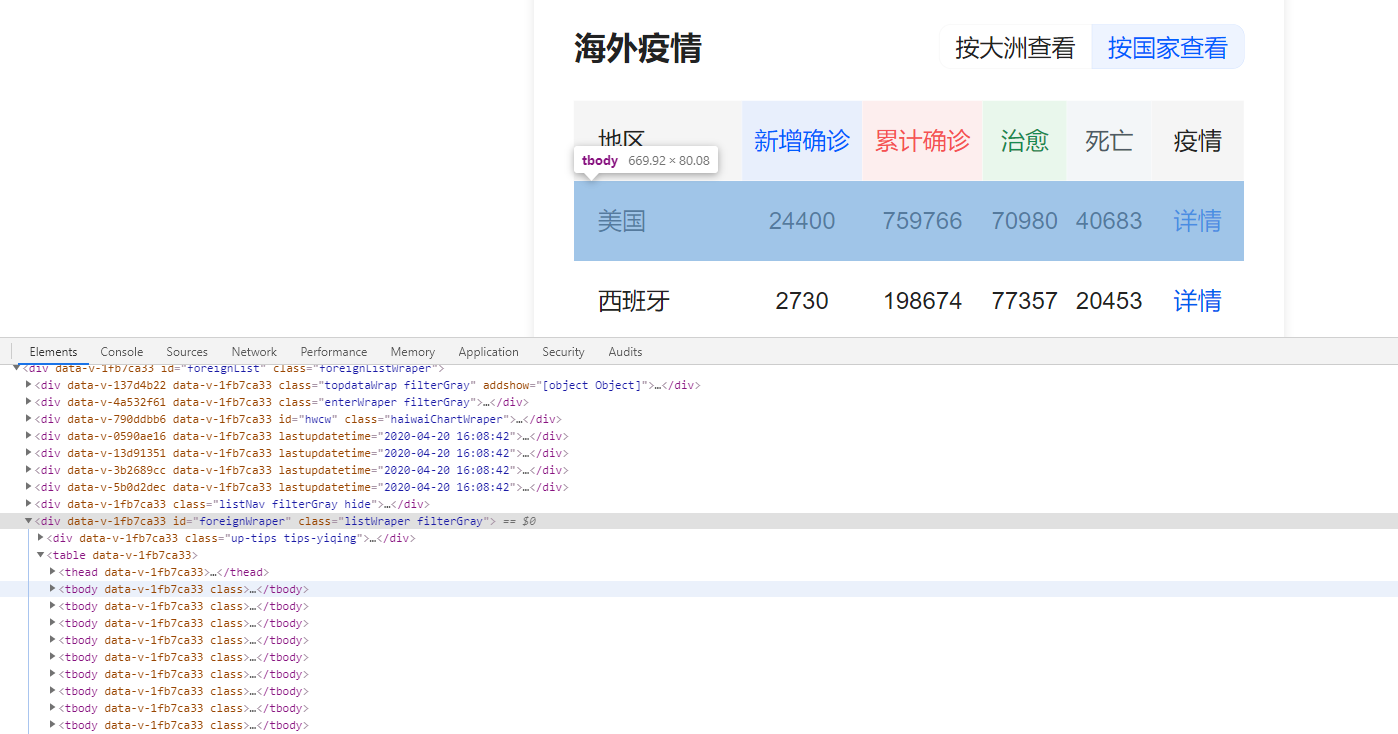
海外疫情,数据列表在id为foreignWraper的元素下
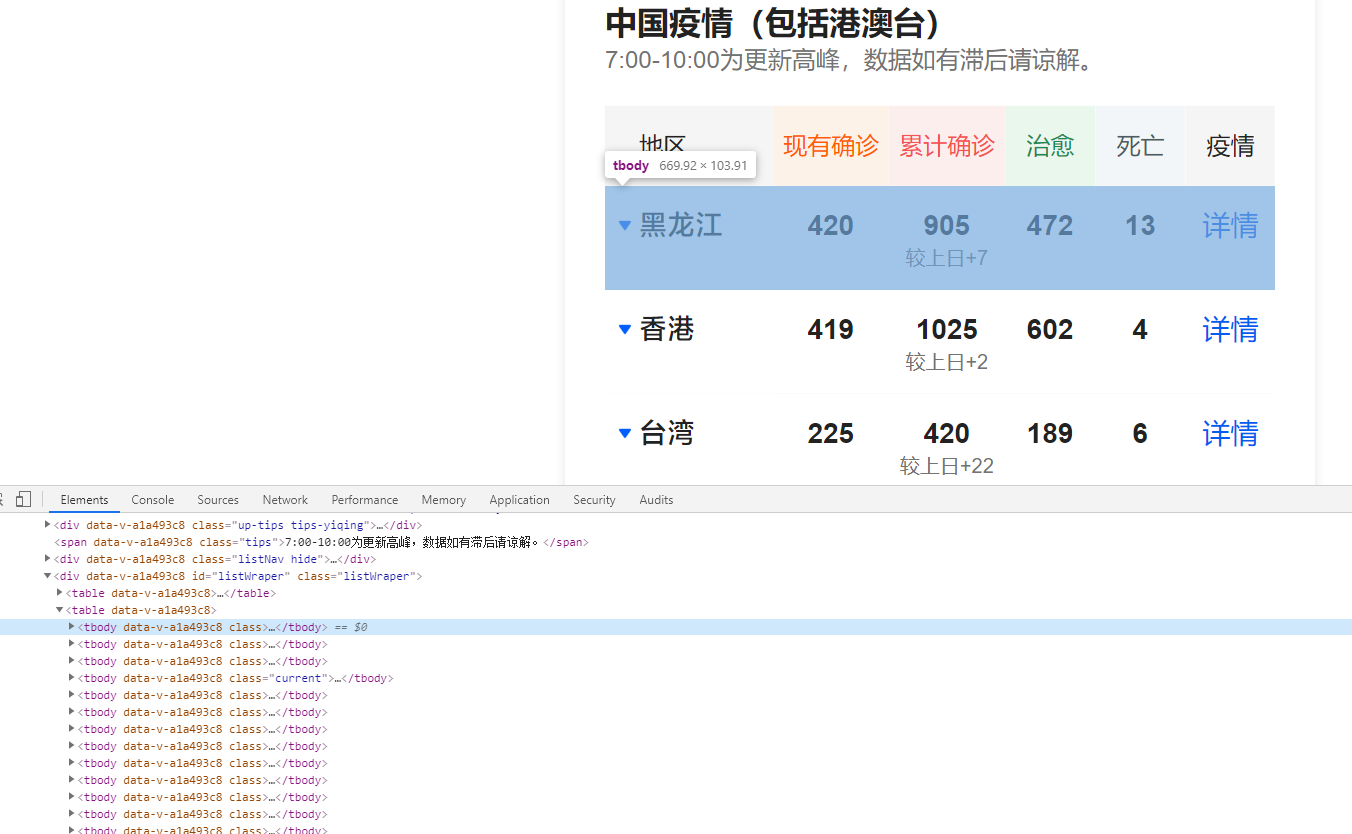
国内疫情,数据列表在id为foreignWraper的元素下
数据都是存在html内的,这里我们用scrapy + selenium + phantom的方式进行爬取
4 定义数据
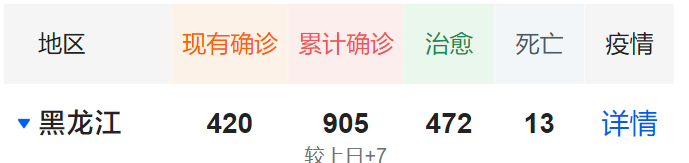
通过页面可以看到数据项共有6项
打开爬虫项目,找到之前scrapy生成项目模板的items.py文件,定义一个item类,依次是集合,表名,地区名称,父地区名称,新增数,现有数,累计数,治愈数,死亡数
class Covid19Item(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() collection = table = 'covid19' name = scrapy.Field() parent = scrapy.Field() new = scrapy.Field() now = scrapy.Field() total = scrapy.Field() cure = scrapy.Field() death = scrapy.Field()
5 Spider实现
切换到spider文件夹下的Covid19Spider.py
修改 start_requests方法,使用meta头传递请求的页面标识
def start_requests(self): # 定义要爬取的页面列表 urls = ["https://news.qq.com/zt2020/page/feiyan.htm#/?ct=United%20States&nojump=1", "https://news.qq.com/zt2020/page/feiyan.htm#/global?ct=United%20States&nojump=1"] # 循环发送请求 for i in range(len(urls)): if i == 0: # 执行中国疫情页面的parer yield scrapy.Request(urls[i], callback=self.parse_China, meta={'page': i}, dont_filter=True) else: # 执行海外疫情页面的parer yield scrapy.Request(urls[i], callback=self.parse_Outsee, meta={'page': i}, dont_filter=True)
新增国内parser方法
# 疫情 中国 def parse_China(self, response): provinces = response.xpath( '//*[@id="listWraper"]/table[2]/tbody').extract() for prn in provinces: item = Covid19Item() prnNode = Selector(text=prn) item['name'] = prnNode.xpath( '//tr[1]/th/p[1]/span//text()').extract_first().replace('区', '') item['parent'] = '' item['new'] = prnNode.xpath( '//tr[1]/td[2]/p[2]//text()').extract_first() item['now'] = prnNode.xpath( '//tr[1]/td[1]/p[1]//text()').extract_first() item['total'] = prnNode.xpath( '//tr[1]/td[2]/p[1]//text()').extract_first() item['cure'] = prnNode.xpath( '//tr[1]/td[3]/p[1]//text()').extract_first() item['death'] = prnNode.xpath( '//tr[1]/td[4]/p[1]//text()').extract_first() cityNodes = prnNode.xpath('//*[@class="city"]').extract() for city in cityNodes: cityItem = Covid19Item() cityNode = Selector(text=city) cityItem['name'] = cityNode.xpath( '//th/span//text()').extract_first().replace('区', '') cityItem['parent'] = item['name'] cityItem['new'] = '' cityItem['now'] = cityNode.xpath( '//td[1]//text()').extract_first() cityItem['total'] = cityNode.xpath( '//td[2]//text()').extract_first() cityItem['cure'] = cityNode.xpath( '//td[3]//text()').extract_first() cityItem['death'] = cityNode.xpath( '//td[4]//text()').extract_first() yield cityItem yield item
新增国外parser方法
# 海外 def parse_Outsee(self, response): countries = response.xpath( '//*[@id="foreignWraper"]/table/tbody').extract() for country in countries: countryNode = Selector(text=country) item = Covid19Item() item['name'] = countryNode.xpath( '//tr/th/span//text()').extract_first() item['parent'] = '' item['new'] = countryNode.xpath( '//tr/td[1]//text()').extract_first() item['now'] = '' item['total'] = countryNode.xpath( '//tr/td[2]//text()').extract_first() item['cure'] = countryNode.xpath( '//tr/td[3]//text()').extract_first() item['death'] = countryNode.xpath( '//tr/td[4]//text()').extract_first() yield item
6 downloader中间件
使用downloader中间件进行页面的请求,在中间件中实现selenium + phantomjs的页面请求,并将htmlresponse返回给spider处理
修改middlewares.py文件,新增SeleniumMiddelware类,根据之前设定的meta头决定页面的显示等待元素
from scrapy import signals from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from scrapy.http import HtmlResponse from logging import getLogger from time import sleep class SeleniumMiddelware(): def __init__(self,timeout=None,service_args=[]): self.logger = getLogger(__name__) self.timeout = timeout self.browser = webdriver.PhantomJS(service_args=service_args) self.browser.set_window_size(1400,700) self.browser.set_page_load_timeout(self.timeout) self.wait = WebDriverWait(self.browser,self.timeout) def __del__(self): self.browser.close() def process_request(self,request,spider): self.logger.debug('PhantomJs is Starting') page = request.meta.get('page',1) try: # 访问URL self.browser.get(request.url) # 等待爬取的元素的加载 if page == 0: self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#listWraper'))) else: self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#foreignWraper'))) # sleep(2) return HtmlResponse(url=request.url,body=self.browser.page_source,request=request,encoding='utf-8',status=200) except TimeoutException: return HtmlResponse(url=request.url,status=500,request=request) @classmethod def from_crawler(cls,crawler): return cls(timeout=crawler.settings.get('SELENIUM_TIMEOUT'), service_args=crawler.settings.get('PHANTOMJS_SERVICE_ARGS'))
这里定义了两个配置,
在settings.py新增配置
一个是selenium的超时时间,一个是phantomjs服务的配置
SELENIUM_TIMEOUT = 20 PHANTOMJS_SERVICE_ARGS = ['--load-images=false', '--disk-cache=true']
启用donwloader中间件
DOWNLOADER_MIDDLEWARES = { 'COVID19.middlewares.SeleniumMiddelware': 543, }
7 Pipelines
pipelines定义了对数据items的处理方式,在这里可以进行数据的存储,定义两个类,一个是mongo的存储,一个是mysql的存储
定义mongodb的操作类
class MongoPipeline(object): def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls, crawler): return cls( mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DB') ) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def process_item(self, item, spider): self.db[item.collection].insert(dict(item)) return item def close_spider(self, spider): self.client.close()
定义mysql的操作类
class MySqlPipeLine(object): def __init__(self, host, database, user, password, port): self.host = host self.database = database self.user = user self.password = password self.port = port @classmethod def from_crawler(cls, crawler): return cls( host=crawler.settings.get('MYSQL_HOST'), database=crawler.settings.get('MYSQL_DB'), user=crawler.settings.get('MYSQL_USER'), password=crawler.settings.get('MYSQL_PASSWORD'), port=crawler.settings.get('MYSQL_PORT') ) def open_spider(self, spider): self.db = pymysql.connect( self.host, self.user, self.password, self.database, charset='utf8', port=self.port) self.cursor = self.db.cursor() def close_spider(self, spider): self.db.close() def process_item(self, item, spider): data = dict(item) keys = ', '.join(data.keys()) values = ', '.join(['%s'] * len(data)) sql = 'insert into {table}({keys}) values ({values}) on duplicate key update'.format( table=item.table, keys=keys, values=values) update = ','.join([" {key}=%s".format(key=key) for key in data]) sql += update try: if self.cursor.execute(sql, tuple(data.values())*2): print('successful') self.db.commit() except pymysql.MySQLError as e: print(e) self.db.rollback() return item
这里分别定义了两个pipeline,其中调用了数据库的配置
在settings.py增加配置
MONGO_URI = 'localhost' MONGO_DB = 'COVID19' MYSQL_HOST = 'localhost' MYSQL_DB = 'covid19' MYSQL_USER = 'root' MYSQL_PASSWORD = '123456' MYSQL_PORT = 3306
启用pipeline中间件
ITEM_PIPELINES = { 'COVID19.pipelines.MongoPipeline': 300, 'COVID19.pipelines.MySqlPipeLine': 300 }
8 mysql数据库
创建一个covid19的数据库
CREATE DATABASE covid19
创建数据表,一个是疫情数据表covid19,一个是地区经纬度的字典表dic_lnglat
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for covid19 -- ---------------------------- DROP TABLE IF EXISTS `covid19`; CREATE TABLE `covid19` ( `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `parent` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `new` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `now` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `total` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `cure` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `death` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`name`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Table structure for dic_lnglat -- ---------------------------- DROP TABLE IF EXISTS `dic_lnglat`; CREATE TABLE `dic_lnglat` ( `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `lng` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `lat` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `type` int(0) NULL DEFAULT NULL, PRIMARY KEY (`name`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1;
9 地区经纬度
爬虫只能从这个页面爬取到疫情的数据,如果要应用这些数据在3D地球VDEarth上显示,还需要相关地区的经纬度
爬出的一共两种类型数据,一种是国内的,包含省份和省份下的市,区等,一种是国外,只有国家名称
国内的直接使用各城市的经纬度,国外使用国家的首都的经纬度,之前工作中,我已经存放了相关的数据,没有的话可以参考
国内城市经纬度整理:参考 https://www.cnblogs.com/chunguang/p/5905607.html
没有找到合适的国外首都经纬度,附上国外首都经纬度整理


1 globe = { 2 "阿富汗": [69.11,34.28], 3 "阿尔巴尼亚": [19.49,41.18], 4 "阿尔及利亚": [3.08,36.42], 5 "美属萨摩亚": [-170.43,-14.16], 6 "安道尔": [1.32,42.31], 7 "安哥拉": [13.15,-8.50], 8 "安提瓜和巴布达": [-61.48,17.20], 9 "阿根廷": [-60.00,-36.30], 10 "亚美尼亚": [44.31,40.10], 11 "阿鲁巴": [-70.02,12.32], 12 "澳大利亚": [149.08,-35.15], 13 "奥地利": [16.22,48.12], 14 "阿塞拜疆": [49.56,40.29], 15 "巴哈马": [-77.20,25.05], 16 "巴林": [50.30,26.10], 17 "孟加拉国": [90.26,23.43], 18 "巴巴多斯": [-59.30,13.05], 19 "白俄罗斯": [27.30,53.52], 20 "比利时": [4.21,50.51], 21 "伯利兹": [-88.30,17.18], 22 "贝宁": [2.42,6.23], 23 "不丹": [89.45,27.31], 24 "玻利维亚": [-68.10,-16.20], 25 "波斯尼亚和黑塞哥维那": [18.26,43.52], 26 "博茨瓦纳": [25.57,-24.45], 27 "巴西": [-47.55,-15.47], 28 "英属维尔京群岛": [-64.37,18.27], 29 "文莱": [115.00,4.52], 30 "保加利亚": [23.20,42.45], 31 "布基纳法索": [-1.30,12.15], 32 "布隆迪": [29.18,-3.16], 33 "柬埔寨": [104.55,11.33], 34 "喀麦隆": [11.35,3.50], 35 "加拿大": [-75.42,45.27], 36 "佛得角": [-23.34,15.02], 37 "开曼群岛": [-81.24,19.20], 38 "中非共和国": [18.35,4.23], 39 "乍得": [14.59,12.10], 40 "智利": [-70.40,-33.24], 41 "中国": [116.20,39.55], 42 "哥伦比亚": [-74.00,4.34], 43 "科摩罗": [43.16,-11.40], 44 "刚果": [15.12,-4.09], 45 "哥斯达黎加": [-84.02,9.55], 46 "科特迪瓦": [-5.17,6.49], 47 "克罗地亚": [15.58,45.50], 48 "古巴": [-82.22,23.08], 49 "塞浦路斯": [33.25,35.10], 50 "捷克共和国": [14.22,50.05], 51 "朝鲜": [125.30,39.09], 52 "刚果(扎伊尔)": [15.15,-4.20], 53 "丹麦": [12.34,55.41], 54 "吉布提": [42.20,11.08], 55 "多米尼加": [-61.24,15.20], 56 "多米尼加共和国": [-69.59,18.30], 57 "东帝汶": [125.34,-8.29], 58 "厄瓜多尔": [-78.35,-0.15], 59 "埃及": [31.14,30.01], 60 "萨尔瓦多": [-89.10,13.40], 61 "赤道几内亚": [8.50,3.45], 62 "厄立特里亚": [38.55,15.19], 63 "爱沙尼亚": [24.48,59.22], 64 "埃塞俄比亚": [38.42,9.02], 65 "福克兰群岛(马尔维纳斯群岛)": [-59.51,-51.40], 66 "法罗群岛": [-6.56,62.05], 67 "斐济": [178.30,-18.06], 68 "芬兰": [25.03,60.15], 69 "法国": [2.20,48.50], 70 "法属圭亚那": [-52.18,5.05], 71 "法属波利尼西亚": [-149.34,-17.32], 72 "加蓬": [9.26,0.25], 73 "冈比亚": [-16.40,13.28], 74 "格鲁吉亚": [44.50,41.43], 75 "德国": [13.25,52.30], 76 "加纳": [-0.06,5.35], 77 "希腊": [23.46,37.58], 78 "格陵兰": [-51.35,64.10], 79 "瓜德罗普岛": [-61.44,16.00], 80 "危地马拉": [-90.22,14.40], 81 "根西岛": [-2.33,49.26], 82 "几内亚": [-13.49,9.29], 83 "几内亚比绍": [-15.45,11.45], 84 "圭亚那": [-58.12,6.50], 85 "海地": [-72.20,18.40], 86 "赫德岛和麦当劳群岛": [74.00,-53.00], 87 "洪都拉斯": [-87.14,14.05], 88 "匈牙利": [19.05,47.29], 89 "冰岛": [-21.57,64.10], 90 "印度": [77.13,28.37], 91 "印度尼西亚": [106.49,-6.09], 92 "伊朗": [51.30,35.44], 93 "伊拉克": [44.30,33.20], 94 "爱尔兰": [-6.15,53.21], 95 "以色列": [35.12,31.47], 96 "意大利": [12.29,41.54], 97 "牙买加": [-76.50,18.00], 98 "约旦": [35.52,31.57], 99 "哈萨克斯坦": [71.30,51.10], 100 "肯尼亚": [36.48,-1.17], 101 "基里巴斯": [173.00,1.30], 102 "科威特": [48.00,29.30], 103 "吉尔吉斯斯坦": [74.46,42.54], 104 "老挝": [102.36,17.58], 105 "拉脱维亚": [24.08,56.53], 106 "黎巴嫩": [35.31,33.53], 107 "莱索托": [27.30,-29.18], 108 "利比里亚": [-10.47,6.18], 109 "阿拉伯利比亚民众国": [13.07,32.49], 110 "列支敦士登": [9.31,47.08], 111 "立陶宛": [25.19,54.38], 112 "卢森堡": [6.09,49.37], 113 "马达加斯加": [47.31,-18.55], 114 "马拉维": [33.48,-14.00], 115 "马来西亚": [101.41,3.09], 116 "马尔代夫": [73.28,4.00], 117 "马里": [-7.55,12.34], 118 "马耳他": [14.31,35.54], 119 "马提尼克岛": [-61.02,14.36], 120 "毛里塔尼亚": [57.30,-20.10], 121 "马约特岛": [45.14,-12.48], 122 "墨西哥": [-99.10,19.20], 123 "密克罗尼西亚(联邦) ": [158.09,6.55], 124 "摩尔多瓦共和国": [28.50,47.02], 125 "莫桑比克": [32.32,-25.58], 126 "缅甸": [96.20,16.45], 127 "纳米比亚": [17.04,-22.35], 128 "尼泊尔": [85.20,27.45], 129 "荷兰": [04.54,52.23], 130 "荷属安的列斯": [-69.00,12.05], 131 "新喀里多尼亚": [166.30,-22.17], 132 "新西兰": [174.46,-41.19], 133 "尼加拉瓜": [-86.20,12.06], 134 "尼日尔": [2.06,13.27], 135 "尼日利亚": [7.32,9.05], 136 "诺福克岛": [168.43,-45.20], 137 "北马里亚纳群岛": [145.45,15.12], 138 "挪威": [10.45,59.55], 139 "阿曼": [58.36,23.37], 140 "巴基斯坦": [73.10,33.40], 141 "帕劳": [134.28,7.20], 142 "巴拿马": [-79.25,9.00], 143 "巴布亚新几内亚": [147.08,-9.24], 144 "巴拉圭": [-57.30,-25.10], 145 "秘鲁": [-77.00,-12.00], 146 "菲律宾": [121.03,14.40], 147 "波兰": [21.00,52.13], 148 "葡萄牙": [-9.10,38.42], 149 "波多黎各": [-66.07,18.28], 150 "卡塔尔": [51.35,25.15], 151 "韩国": [126.58,37.31], 152 "罗马尼亚": [26.10,44.27], 153 "俄罗斯": [37.35,55.45], 154 "卢旺达": [30.04,-1.59], 155 "圣基茨和尼维斯": [-62.43,17.17], 156 "圣卢西亚": [-60.58,14.02], 157 "圣皮埃尔和密克隆": [-56.12,46.46], 158 "圣文森特和格林纳丁斯": [-61.10,13.10], 159 "萨摩亚": [-171.50,-13.50], 160 "圣马力诺": [12.30,43.55], 161 "圣多美和普林西比": [6.39,0.10], 162 "沙特阿拉伯": [46.42,24.41], 163 "塞内加尔": [-17.29,14.34], 164 "塞拉利昂": [-13.17,8.30], 165 "斯洛伐克": [17.07,48.10], 166 "斯洛文尼亚": [14.33,46.04], 167 "所罗门群岛": [159.57,-9.27], 168 "索马里": [45.25,2.02], 169 "比勒陀利亚": [28.12,-25.44], 170 "西班牙": [-3.45,40.25], 171 "苏丹": [32.35,15.31], 172 "苏里南": [-55.10,5.50], 173 "斯威士兰": [31.06,-26.18], 174 "瑞典": [18.03,59.20], 175 "瑞士": [7.28,46.57], 176 "阿拉伯叙利亚共和国": [36.18,33.30], 177 "塔吉克斯坦": [68.48,38.33], 178 "泰国": [100.35,13.45], 179 "马其顿": [21.26,42.01], 180 "多哥": [1.20,6.09], 181 "汤加": [-174.00,-21.10], 182 "突尼斯": [10.11,36.50], 183 "土耳其": [32.54,39.57], 184 "土库曼斯坦": [57.50,38.00], 185 "图瓦卢": [179.13,-8.31], 186 "乌干达": [32.30,0.20], 187 "乌克兰": [30.28,50.30], 188 "阿联酋": [54.22,24.28], 189 "英国": [-0.05,51.36], 190 "坦桑尼亚": [35.45,-6.08], 191 "美国": [-77.02,39.91], 192 "美属维尔京群岛": [-64.56,18.21], 193 "乌拉圭": [-56.11,-34.50], 194 "乌兹别克斯坦": [69.10,41.20], 195 "瓦努阿图": [168.18,-17.45], 196 "委内瑞拉": [-66.55,10.30], 197 "越南": [105.55,21.05], 198 "南斯拉夫": [20.37,44.50], 199 "赞比亚": [28.16,-15.28], 200 "津巴布韦": [31.02,-17.43] 201 }
可以在python内增加写入mysql库的同步进字典表
10 执行爬取
执行scrapy命令启动爬虫
scrapy crawl covid19spider
可以看到爬虫运行的控制台日志输出,打开数据库查看
上面pipeline章节使用了mysql和mongo,可以看到数据已经写入mysql和mongo中,实际选择一个就好
爬虫虽然能工作了,但是每次启动都要手动执行命令,新增一个running.py文件,定时去调用爬虫
# -*- coding: utf-8 -*- from multiprocessing import Process from scrapy import cmdline import time import logging import os # 配置参数即可, 爬虫名称,运行频率 confs = [ { "spider_name": "covid19spider", "frequency": 10, }, ] def start_spider(spider_name, frequency): args = ["cd covid19","scrapy", "crawl", spider_name] while True: start = time.time() p = Process(target=cmdline.execute, args=(args,)) p.start() p.join() logging.debug("### use time: %s" % (time.time() - start)) time.sleep(frequency) if __name__ == '__main__': for conf in confs: process = Process(target=start_spider,args=(conf["spider_name"], conf["frequency"])) process.start() time.sleep(86400)
这样爬虫就可以定时的去爬取数据,也可以使用其他的方式进行定时的调度,这里不多说
至此 疫情数据的爬虫就完成了
相关链接
从0开始疫情3D地球 - 3D疫情地球VDEarth - 1- 引言
从0开始疫情3D地球 - 3D疫情地球VDEarth - 2 - 前端代码构建
从0开始疫情3D地球 - 3D疫情地球VDEarth - 3 - 3D地球组件实现(1)
从0开始疫情3D地球 - 3D疫情地球VDEarth - 4 - 3D地球组件实现(2)
从0开始疫情3D地球 - 3D疫情地球VDEarth - 5 - 疫情数据爬虫
从0开始疫情3D地球 - 3D疫情地球VDEarth - 6 - 数据推送