IP地址定义:
struct in_addr{ __u32 s_addr; };
in_addr_t inet_addr (__const char * __cp) :把点分十进制IP地址字符串转换为32位IP地址(网络存储顺序)。
in_addr_t inet_network (__const char * __cp) :把点分十进制IP地址字符串转换为32位IP地址(主机字节顺序)。
char * inet_ntoa (struct in_addr_in) :把32位网络字节顺序的IP地址转换成点分十进制表示。
int inet_aton (__const char *__cp, struct in_addr *__inp) :把点分十进制IP地址字符串转换为32位IP地址(网络字节顺序)。第二个参数是转换结果地址。成功返回0。与第一个函数功能相同。
#include<arpa/inet.h> #include<netinet/in.h> #include<stdio.h> #include<string.h> #include<sys/socket.h> int main(int argc, char *argv[]) { in_addr_t net; struct in_addr net_addr, ret; net = inet_addr("192.168.68.128"); net_addr.s_addr = net; //把点分十进制转换为网络存储顺序的IP printf("inet_addr(192.168.68.128) = 0x%x ", inet_addr("192.168.68.128")); //把点分十进制转换为主机存储顺序的IP printf("inet_network(192.168.68.128) = 0x%x ", inet_network("192.168.68.128")); //把网络存储顺序的IP转换为点分十进制 printf("inet_ntoa(net) = %s ", inet_ntoa(net_addr)); inet_aton("192.168.68.128", &ret); printf("inet_aton ret.s_addr = 0x%x ", ret.s_addr); }
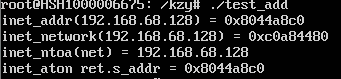
基于地址类型转换
int inet_pton (int __af, __const char *__restrict __cp, void *__restrict __buf) :将存储在起始位置为cp、地址协议类型为AF的点分十进制地址转换到buf中。如果IPv4,buf应为in_addr型,如果IPv6,buf应为in6_addr型。
char * inet_ntop (int __af, __const void *__restrict __cp, char *__restrict __buf, socklen_t __len) :将网络字节顺序存储的IP地址转为点分十进制。如果IPv4,cp应为in_addr型,如果IPv6,cp应为in6_addr型。
#include<arpa/inet.h> #include<netinet/in.h> #include<stdio.h> #include<string.h> #include<sys/socket.h> int main(int argc, char *argv[]) { in_addr_t net; struct in_addr net_addr, ret; char buf[128]; inet_pton(AF_INET, "192.168.68.128", &ret); inet_ntop(AF_INET, &ret, buf, 128); printf("buf = %s ", buf); }

in_addr_t inet_lnaof (struct in_addr __in) :从32位网络顺序IP地址中提取主机ID。
in_addr_t inet_netof (struct in_addr __in) :从32位网络顺序IP地址中提取网络ID。
struct in_addr inet_makeaddr (in_addr_t __net, in_addr_t __host) :把主机ID和网络ID合成一个IP地址。
IP数据报包头数据结构定义:

TCP包头信息结构体


UDP包头信息结构体

大小端原理
一个整数 0x12345678 中12是高字节,78是低字节
CPU处理数据有大端小端两种方式
小端模式:高字节放在高地址
大端模式:高字节放在低地址
检测当前系统字节顺序:
#include<stdio.h> #include<endian.h> int main(void) { printf("Big-endian: %d Little-endian: %d mine: %d ", __BIG_ENDIAN, __LITTLE_ENDIAN, __BYTE_ORDER); return 0; }

共用体检测系统大小端
对于结构体
union word { int a; char b; }c;
b在基地址开始存储或保存
#include<stdio.h> #include<stdlib.h> union word { int a; char b; }c; int checkCPU(void) { c.a = 1; return (c.b == 1); } int main(void) { int i; i = checkCPU(); if(i == 0) printf("this is Big_endian "); else if(i == 1) printf("this is Little_endian "); return 0; }

字节顺序转换函数
unsigned long int ntohl (unsigned long int) :long 网络字节顺序 转为 主机字节顺序
unsigned long int htonl (unsigned long int) :long 主机字节顺序 转为 网络字节顺序
unsigned short int ntohs (unsigned short int) :short 网络字节顺序 转为 主机字节顺序
unsigned short int htons (unsigned short int) :short 主机字节顺序 转为 网络字节顺序
网络编程统一使用大端模式!
----------------------------------------------------------------------------
插播知识点 #pragma pack(1) 的用途
设置结构体的边界对齐为1个字节,也就是所有数据在内存中是连续存储的。
比如你在C语言中定义下面这样的结构体:
struct s {
char ch;
int i;
};
然后在主函数中写一句:printf("%d", sizeof(struct s))
也就是输出结构体s所占的字节数
你觉得输出结果会是多少呢?
我们知道,char型占用1个字节,int型占4个字节,那么输出的结果是5吗?
答案是否定的。你可以自己试一下,输出结果为8。
为什么会这样呢?这是因为编译器为了让程序跑得跟快,减少CPU读取数据的指令周期,对结构体的存储进行了优化。实际上第一个char型成员虽然本来只有1个字节,但实际上却占用掉了4个字节,为的是让第二个int型成员的地址能够被4整除。因此实际占用的是8个字节。
而#pragma pack(1)让编译器将结构体数据强制连续排列,这样的话,sizeof(struct s)输出的结果就是5了。
------------------------------------------------------------------------------------------------
在数据传输时统一转换大小端的处理:
1.单字节数据,不需要转换大小端。如char buf[] = "Hello"
2.多字节数据,用字节顺序转换函数
3.自定义结构体:如果双方都知道结构体内成员,可以一个成员一个成员的转换
也可以用#pragm pack(1) 处理, 让两边字节对齐方式一致, 整体转换。