-
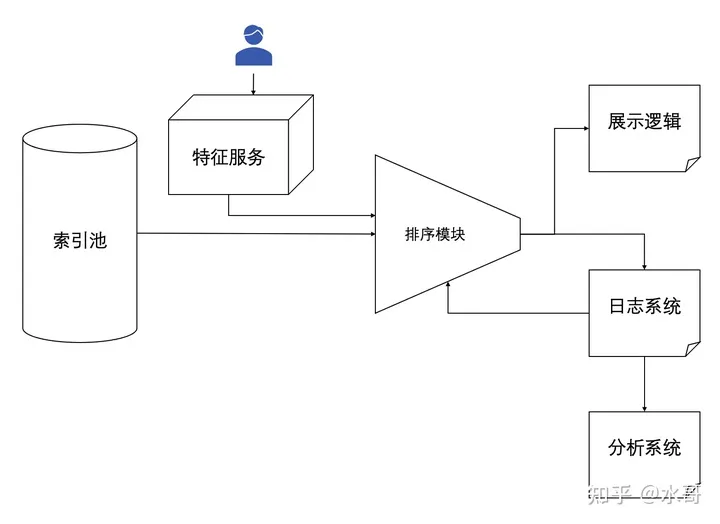
索引池是对当前所有item的判定,并不是所有item都可以出现在推荐这整个大的逻辑下面。举个例子,广告主的某个计划,只设定了相应的预算,如果预算花完了,或者广告主已经不想投了,那就需要从索引池里面拿掉。另一种情况是可能有多种索引池,广告主不想投放20-30的人群的时候,索引池就等于是其他年龄段的索引池合并起来。
-
特征服务,用户发生请求(刷新,刚进入app等都会有请求发生)时,算出该用户信息所对应的特征,比如通过他的一些行为判定他的年龄性别等。另一个很重要的则是获取这个用户的一些历史行为。对于item当然也要提取特征,但是图上没有画出来,原因是item的大多数特征都相对固定,而用户的行为特征变化很快,需要专门的服务来处理
排序模块,这就是模型主导的部分了,下面要讲的召回精排粗排都在这里,下一讲要涉及的打压保送策略也包含在内。排序模块的作用就是从很多候选的item中挑出最好的一个或者多个进入到展示逻辑中 -
展示逻辑,这里有的同学可能会问,知道哪个最好不就直接放出去就好了吗?为啥还要有一个逻辑的区分?其实这里一个主要的点指的是广告和内容的混排,或者是视频和文章的混排。广告和文章,在各自的排序阶段是谁也看不见谁的,也就是说,上面的排序系统是双倍的。当双方都排好之后,需要对广告进行判定,要么是质量很高(预估的ctr,cvr都很高),要么是此刻之前展示的广告比较少,门槛下降了。如果符合这两种情况就可以对广告选择合适的位置投放。
-
日志系统:记录推送前后系统发生的一切事情。注意在图上有一个日志系统返回排序模块的箭头,这个箭头的含义是,用户的行为要落盘,形成新的训练数据来让排序模块继续训练
-
分析系统:这个系统依赖于日志,此处主要指AB测试系统。AB测试就是指,把用户随机进行划分,一部分用户应用对照组(A组,也就是原来的系统),另一部分用户应用实验组(B组,也就是我们想添加的改进点)。通过对比AB之间的差异,来展示我们所加的改进点是否有效。所以整个系统的迭代都是严重依赖AB实验的,想一个idea-做线下实验-上AB试试-有效就推广到全量,一般是这么个流程。当然AB实验也不是万能的,这个后面会讲到。另外要注意的是,虽然这里叫做AB测试,但是实际上对照组的用户不是都放在同一个桶里面,实践中往往是AABB实验,即对照组也有多组,实验组也有多组。这么做是为了观察组内的方差和组间的方差,假如两个对照组之间的观看时长差距有3%,对照组和实验组差距只有2%,那我们就无法说明这个实验是有正向的。
上面是对于整个系统框架的梳理,下面我们就细化到排序模块里面,看看具体是如何排序的.