Towards Cross-Domain PDTB-Style Discourse Parsing(2014)
走向跨域的PDTB式篇章分析,1h,速读
Motivation
-
Discourse Relation Parsing是为了理解句子边界以外的文本。
-
文献表明,篇章连接词检测 和 篇章关系sense分类的 篇章分析子任务不能很好地 跨领域推广
-
在本文中,提出了 PDTB训练的 篇章关系分析器的 跨域评估,并评估了 论元跨度提取 子任务上的 特征级域自适应技术。
-
我们证明子任务可以很好地跨领域推广。
具体步骤
-
Argument Position Classification
-
Argument Span Extraction
实验结果
- 评估方法

训练好的 论元跨度提取模型(SS,PS,ALL) 的域内性能
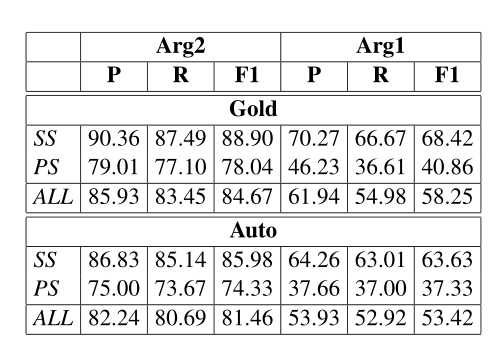
-
Cross-Domain Argument Position Classification
-
In-Domain Argument Span Extraction: PDTB
-
In-Domain Argument Span Extraction: BioDRB
-
Cross-Domain Argument Span Extraction: PDTB - BioDRB
- we additionally train PDTB models on the automatic features. (通过自动句子分割、标记化和句法分析从PDTB中提取的特征。)
-
论元跨度提取 比 搜索连接检测和关系sense分类的论述子任务更好地推广到生物医学领域。
-
Feature-Level Domain Adaptation(特征级领域适应)

-
跨域论元提取实验表明,在优化特征集上训练的模型具有良好的泛化能力。
-
然而,它们依赖于关系sense分类任务,这不能很好地概括。
-
通过用 “connective labels” 替换连接词senses,我们获得了独立于该任务的模型,同时保持了相当的性能。
结论
-
提出了 跨域语篇分析器 对 论元位置分类 和 论元跨度提取子任务的评价。
-
观察到的跨域性能表明了良好的模型概括。
-
但是,由于这些模型是在 pipeline 的后期应用的,它们会受到其他任务跨域性能的影响。
-
此外,我们还提出了特征级领域自适应技术,以 减少 跨领域论元跨度提取 对其他语篇分析子任务的依赖。
-
提供句子切分 和 标记化的句法解析器(斯坦福)在Penn Treebank上训练,即对于PDTB是域内,对于BioDRB是域外;
-
众所周知,域优化的标记化 提高了各种自然语言处理任务的性能。因此,这项工作的未来方向是使用针对生物医学领域优化的工具来评估 论元跨度提取