A PDTB-Styled End-to-End Discourse Parser(2010年)
科普,快速浏览,1h
1 Abstract
-
开发了一个full discourse parser in PDTB style。
-
这个训练的解析器:首先识别所有的篇章和非篇章关系,定位 并 标记 他们的论元,然后对他们关系类型进行分类。
-
在适当的时候,这些关系的 attribution spans 也被确定。
-
从 component-wise(组件级) 和 error-cascading(错误级)的角度给出全面评估。
2 Introduction
-
discourse analysis: the process of understanding the internal structure of a text
-
discourse parsing: the process of realizing the semantic relations in between text units
-
在组件方面,我们引入了两种新的方法来准确 定位 和 标记论元,以及标记 属性跨度。
-
我们还通过新引入的特性对当前最先进的 连接词分类器 进行了显著改进。
3 The Penn Discourse Treebank
4 System Overview
- 算法流程:

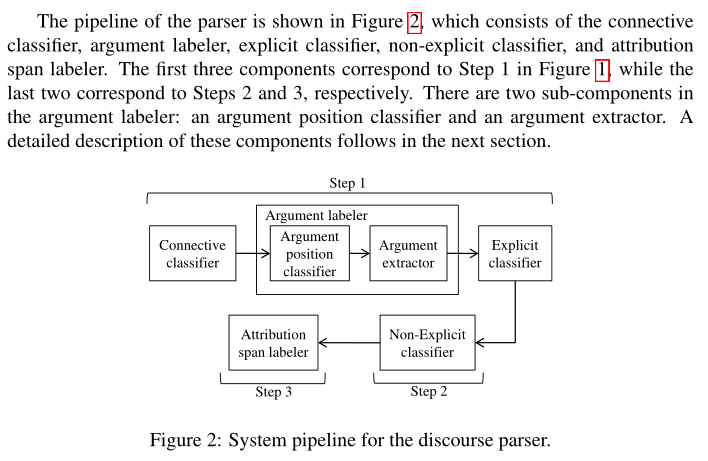
Step1: connective classifier, argument labeler, explicit classifier
Step2: non-explicit classifier
Step3: attribution span labeler.
sub-components argument labeler: an argument position classifier and an argument extractor.
5 Components
5.1 Connective Classifier
-
从成分分析树中提取的句法特征对于消除话语连接词的歧义非常有用
-
连接词本身作为一个特征之外,他们还应用了其他句法特征:树中的最高节点,它只覆盖连接词(他们称之为自我范畴),自我范畴的父、左、右兄弟,以及检查右兄弟是否包含VP和/或踪迹的两个二元特征。
-
他们展示的最佳特征集还包括 连接词 和 每个句法特征之间的 成对交互特征,以及 成对句法特征 之间的 交互特征。
5.2 Argument Labeler
(1)识别Arg1和Arg2的位置,以及(2)标记它们的范围。我们注意到Arg2是与连接词在句法上相关联的参数

5.3 Explicit Classifier
5.4 Non-Explicit Classifier
5.5 Attribution Span Labeler
标注四个方面:their sources, types, scopal polarities, and determinacy.(来源、类型、范围极性和确定性)
6 Evaluation
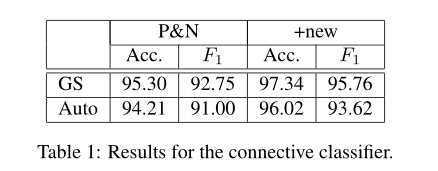

7 Future Work
8 Conclusion
我们设计了一个在PDTB表示中执行话语解析的解析算法,并将其实现到一个端到端系统中。这是第一个端到端的话语解析器,它可以以PDTB的方式将任何不受限制的文本解析成它的话语结构。