Automatic sense prediction for implicit discourse relations in text(文本中隐含篇章关系的自动sense预测)(2009)
2009年,科普,快速看
Abstract(摘要)
提出了一系列 自动识别 隐含篇章关系 sense 的实验。
结果: 在代表自然发生 senses 的分布的 测试集上报告结果。
我们使用了几个语言学上的信息特征:
-
包括polarity tags(极性标签)
-
Levin verb classes(莱文动词类别)
-
length of verb phrases(动词短语长度)
-
modality(情态)、context(上下文) 和 lexical features(词汇特征)
此外,回顾了过去使用 未标注文本中的词汇对作为特征的方法,解释了它们的一些缺点并提出了修改建议。
特征的最佳组合 比 数据密集型方法的baseline 在comparison 上高 4%,contingency上高16%、
1 Introduction
-
使用了PDTB
-
得益于数据密集型方法,这些方法,依赖于 大量未标注的文本
-
论文针对 隐式篇章关系
我们 研究了 各种旨在 捕捉词汇和语义规律 以识别隐含关系sense的 特征的有效性
介绍其他几种获取跨度语义的方法(polarity features, semantic classes, tense, etc.)
这是第一个报告文本中自然发生的隐含关系的分类结果,并使用各种sense的自然分布的研究。
2 Related Work
Experiments on implicit and explicit relations(z实验在 包含显性和隐性关系 数据上):
- 许多有用的特征,特别是句法,利用了连接词的两个论元都在同一个句子中的事实。这些特征不适用于分析在句际间发生的隐含关系。(RST corpus)
Experiments on artificial implicits(实验在 人工隐含数据上)
-
使用数据 [Arg1, but Arg2]
-
在平衡的数据 关系上 使用二分类
-
使用相同数量的每种类型可能会产生误导。
-
Expansion最多,Causal和Comparison对应用最有用。
-
因此,分类的 Recall 应该是成功的主要衡量标准。
-
3. Penn Discourse Treebank(PDTB)
4 Word pair features in prior work(词对特征)
总结:我们期望成对的虚词(function words)是有助于预测话语关系意义的信息特征。在我们接下来描述的工作中,我们使用特征选择来详细研究单词对
Cross product of words
-
在没有明确标记的情况下,最容易获得的特征是关系的两个文本跨度中的单词。
-
认为两个论元中的词之间存在某种关系。
Semantic relations vs. function word pairs
-
特征选择
-
数据稀疏:特征选择工作的元分析
-
一种减少特征数量的方法遵循单词之间语义关系的假设:
-
即使有数百万个训练例子,使用所有单词的预测结果 也优于 仅基于成对非虚词(non-function)的预测结果。
-
然而,由于去除虚词(function words)后学习曲线更加陡峭,他们假设一旦有足够的训练数据可用,仅使用非虚词将优于使用所有词
-
动词,最有用的特征
-
-
-
(1) stemming(词干) (2) 使用一个小的固定词库大小,只包含最频繁的词干(这往往是由虚词主导的)(3)最小频率的一个特征的cutoff ==> 提高性能
- 过滤停用词对结果有负面影响。
-
我们期望成对的虚词是有助于预测话语关系意义的信息特征。在我们接下来描述的工作中,我们使用特征选择来详细研究单词对
5 Analysis of word pair features

6 Features for sense prediction of implicit discourse relations
虽然我们同意论元中的实际单词非常有用,但我们也定义了与单词的各种语义属性相对应的几个高级特征。
一个关系的两个文本跨度中的单词取自PDTB中的黄金标准注释
-
Polarity Tags: 单词的情感的属性,每个单词的极性是根据其在多视角 Question Answering Opinion Corpus中的条目来分配的
- 使用number of negated and non-negated positive, negative, and neutral sentiment words in the two text spans as features.
-
Inquirer Tags:(查询)我们只包含两个论元中的动词及其叉积的查询标签。就像极性特征一样,我们包括特征的每个标签及其否定。
-
Money/Percent/Num:
-
Word Pairs
- 我们训练了一个基于未标注文本的词对模型。用于训练的单词对由PDTB隐含关系的文本跨度(Arg1×Arg2)中的单词的叉积形成。
7 Classification Results
-
四个二分类
-
因为除了Expansion之外的每一个关系都是不常见的,所以我们使用 相同数量的目标关系 的正负例子进行训练。反面例子是随机选取的。
-
我们使用第21节和第22节进行测试,因此测试集代表自然分布。

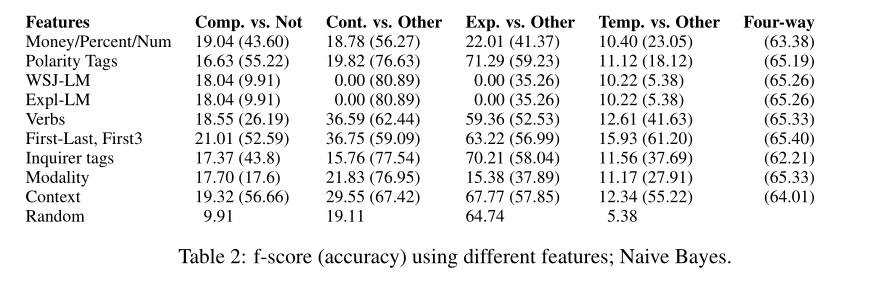
7.1 Non-Wordpair Features
-
F-score
-
Baseline: 按照测试集中真实分布比例 随机分配类别 实现的f-score
7.2 Which word pairs help?
解决其他人在最近的工作中提出的两个重要的相关问题
(1)来自显式的未标注数据是否有助于消除隐式话语关系歧义的训练模型
(2)显式和隐式关系在本质上彼此不同。

7.3 Best results
8 Conclusion(总结)
-
该研究预测了现实环境中隐含篇章关系(区分利益关系和所有其他关系,这些关系以它们的自然分布出现)
-
我们的实验证明,特征 被发展来捕捉 词的极性word polarity、verb classes动词的类别 和 方向orientation。词汇特征是话语关系类型的有力指标
-
我们发现这些 特征 事实上并没有捕捉语义关系,而是给出了关于虚词共现的信息。然而,它们仍然是篇章关系预测的有用信息来源。
-
这些特征的最有益的应用:是当它们是从一个大的未标注的显式关系语料库中选择的,但是 然后在人工标注的隐式关系上训练。