Easily Identifiable Discourse Relations(易于识别的篇章关系)
2008年,科普,快速看
Abstract(摘要)
提出基于PDTB研究,PDTB是一个人工标注的大型语料库,包含显式或隐式实现的contingency, comparison, temporal,expansion relations
Temporal的显示篇章连接词会有歧义,但是整体是明确的,允许篇章关系进行高精度的分类。
我们对显性关系的分类准确率为93.09%,总体准确率为74.74%。
此外,我们表明,一些关系对在文本中一起出现的频率比预期的更偶然。
- 这一发现表明,对文本中的关系 进行全局序列分类可以得到更好的结果,特别是对于隐含关系。
1 Introduction(引言)
1.1 问题
认知上最显著的关系是 causal (contingency), contrast (comparison), and temporal.
Discourse Relation自动分类的另一个复杂之处是,即使存在明确的话语连接词,连接词在几个意义之间也可能是模糊的。
- 例如,since can be used to signal either a temporal or a contingency relation.

出现了几个与自动识别篇章关系的effort是直接相关的问题。
-
隐性关系更难识别,它们比例越大,文本中整体篇章关系任务任务就越困难
-
discourse connectives的意思模糊
1.2 提出解决方法
在一篇文本中,相邻的话语关系是 相互独立的 还是 某些关系序列更有可能?
-
在后一种情况下,可以使用文本的“discourse grammar”,并且容易识别关系
-
例如,明确的显式关系,可以帮助确定紧随其后 或 在它们之前的 隐式关系的类别。
在这篇研究,使用了PDTB,工作是对对数据密集型方法的补充。这些方法,使用 启发式方法 来规避获取 annotations 的费用问题。
-
思想:明确标记的显示篇章关系 可以被用于 学习隐性篇章关系 的分类器
-
方法:
-
从一个大的语料库中收集明确的例子,例如包含“because”的句子被提取为代表因果(causal)关系
-
而包含连接词“bug”的句子被提取为代表对比(contrast)关系。
-
测试结果分类器的性能,无需手动注释,而是使用一种巧妙的技术——从句子中删除连接词,并基于不同于 篇章连接词本身的特征 来 预测 篇章关系。
-
-
缺点:
-
产生误导,明确的显性例子上训练的篇章关系分类器在实际的、手写注释的隐性例子上测试时表现不佳
-
数据密集型的无监督方法留下了一些未解决的问题,如篇章连接词的整体歧义是什么(只使用了少数明确的连接词),以及给定类型的显性和隐性关系的相对比例是多少。
-
本文回答了两个问题:
-
从整体上量化了discourse连接词的歧义程度(第3节),并证明了仅基于显性话语连接词就可以实现discourse连接词的合理分类(第4节)。
-
最后,我们表明,由于文本中的关系序列中存在模式,无歧义的显性篇章关系 有助于识别 隐性篇章关系(第5节)。
2. The Penn Discourse Tree Bank(旧的版本)
2.1 PDTB简介
略
在这项工作中,我们计算了两种注释的意义。所以即使只有18,459种显示relation,这里有 19,458种显示senses。语料库中标注的隐性关系共有16,584个
这里需要强调的是,每一种篇章关系总是与两个论点联系在一起。
-
在显式关系的情况下,其中一个参数总是在语法上与显式连接词相关联。另一个参数在文本中的位置不受限制。
-
对于隐式关系,这两个参数必须在结构上相邻。
PDTB还包含其他三种不太常见的类型的注释,在这些情况下,无法推断出隐式关系。
-
AltLex(Alternative Lexicalization):被注释在两个相邻的句子之间,这种结构模式不是话语连接,而是表示篇章关系的存在。在这种情况下,隐含连接词的插入会导致 关系表达的 冗余。
-
EntRel (Entity Relation):当两个相邻的句子仅仅因为提到同一个 discourse entity(实体),而不是通过一个 discourse relation而相关时
-
NoRel (No Relation):当无法推断上述任何关系时,会被注释。
2.2 本文重点
在本文中,我们重点关注显性和隐性关系,因为它们构成了语料库的绝大多数。在接下来的内容中,我们将把AltLex、EntRel和NoRel视为其他类别的一部分。
top class level:Expansion,Comparison,Contingency,Temporal


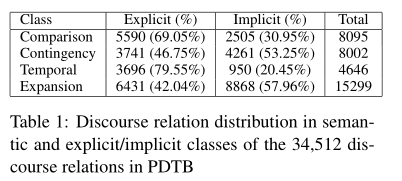
在我们的实验中,我们选择只使用语义层次的top class level,因此将我们自己限制在Expansion, Comparison, Contingency, and Temporal
我们假设,对于大多数应用来说,两个句子在temporally(时序的) or contingently(偶然的)相关的区别 比 细微的区别更重要,比如关系是并列(juxtaposition)还是对立(opposition)。
3 Ambiguity of discourse connectives(篇章连接词的歧义)
3.1 歧义表现
旧版本

表示 comparison 和 contingency的连接词大多数是明确的。明显的例外是常用于表示 Temporal关系的连接词:while 和 since
-
这些连接词的主要意义分别是比较(66.07%)和偶然性(52.17%)。
-
Temporal连接词也相当有歧义:meanwhile, as, when, until, and then


-
到目前为止,我们一直关注不同类型关系之间的模糊性。根据上面的数据,人们可能会认为可以选择几乎总是对应于特定意义(例如,and总是Expansion)的连接词,并使用这些词来找到显式关系。
-
但是,这种观点可能过于乐观。还有另一种类型的歧义:
-
单词可能对它们是否作为discourse连接物有歧义。例如,考虑"and"的以下两种用法。
-
Selling picked up as previous buyers bailed out of their positions and aggressive short sellers – anticipating further declines – moved in.
- 这里 and 做 Discourse connective
-
My favorite colors are blue and green.
- 只是连接两个句子,不标记为连接词
-
-
基于句法特征的话语和一般用法之间的歧义消除可以以高精度和召回率(高于0.95)来执行(不咋地)
- 名词化的连接词(because of等),表达的connective:non-connective比例更高
4 Automatic classification of discourse relations(篇章关系的自动分类)
-
四个二分类的性能
-
表格用十折交叉验证,显示了四个二分类器的分类准确度(accuracy),precision,Recall
5 N-gram discourse relation models(N-gram篇章关系模型)
我们现在看一下在PDTB中各种关系相邻的频率。
我们计算了每对关系在两个方向上的转移概率。对于向前的方向,我们计算:

向后的方向,计算:
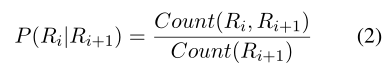
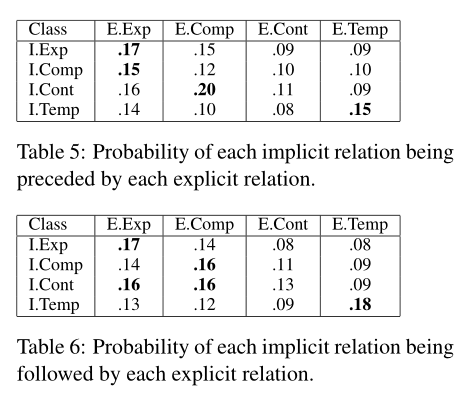
从表5和表6中可以看出,每种类型的关系都有一种独特的模式,尽管这种模式很弱。
显式展开最有可能与隐式展开相邻,显式比较最有可能跟随隐式比较,显式比较最有可能与隐式偶然性相邻,显式时态最有可能与隐式时态相邻。
这些结果表明,相邻的显性关系可能是隐性关系自动分类器的一个有用特征。
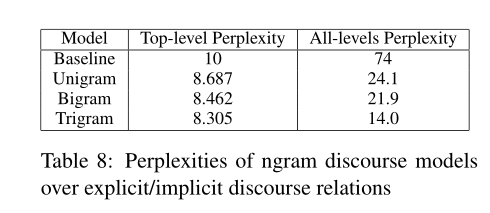
5.1 Perplexity(困惑)
在finergrained的情况下,增加更多的上下文确实大大减少了困惑。
预测完整注释的平均分支因子仅在单图模型下为24.1,但在前两个标签下降至14.0。
因此,即使一个人主要关心顶层意义类,预测完整的注释也可能是有用的,因为它更有助于预测周围的关系。
粗体显示了显式/隐式组合,它们显示出显著的关联

6 Conclusion
balbalba
未来将文本中的篇章关系标注作为一个序列标注问题,并使用周围关系的显性线索词作为特征来寻找“隐藏”的隐性关系。