1. nn.LSTM
1.1 lstm=nn.LSTM(input_size, hidden_size, num_layers)
lstm=nn.LSTM(input_size, hidden_size, num_layers)
参数:
-
input_size:输入特征的维度, 一般rnn中输入的是词向量,那么 input_size 就等于一个词向量的维度,即feature_len; -
hidden_size:隐藏层神经元个数,或者也叫输出的维度(因为rnn输出为各个时间步上的隐藏状态); -
num_layers:网络的层数;
1.2 out, (h_t, c_t) = lstm(x, [h_t0, c_t0])
-
x:[seq_len, batch, feature_len] -
h/c:[num_layer, batch, hidden_len] -
out:[seq_len, batch, hidden_len]

import torch
from torch import nn
# 4层的LSTM,输入的每个词用100维向量表示,隐藏单元和记忆单元的尺寸是20
lstm = nn.LSTM(input_size=100, hidden_size=20, num_layers=4)
# 3句话,每句10个单词,每个单词的词向量维度(长度)100
x = torch.rand(10, 3, 100)
# 不传入h_0和c_0则会默认初始化
out, (h, c) = lstm(x)
print(out.shape) # torch.Size([10, 3, 20])
print(h.shape) # torch.Size([4, 3, 20])
print(c.shape) # torch.Size([4, 3, 20])
2. nn.LSTMCell
nn.LSTMCell与nn.LSTM的区别 和nn.RNN与nn.RNNCell的区别一样。
2.1 nn.LSTMCell()
- 初始化方法和上面一样。
2.2 h_t, c_t = lstmcell(x_t, [h_t-1, c_t-1])
-
(x_t):[batch, feature_len]表示t时刻的输入
-
(h_{t-1}, c_{t-1}):[batch, hidden_len],(t-1)时刻本层的隐藏单元和记忆单元
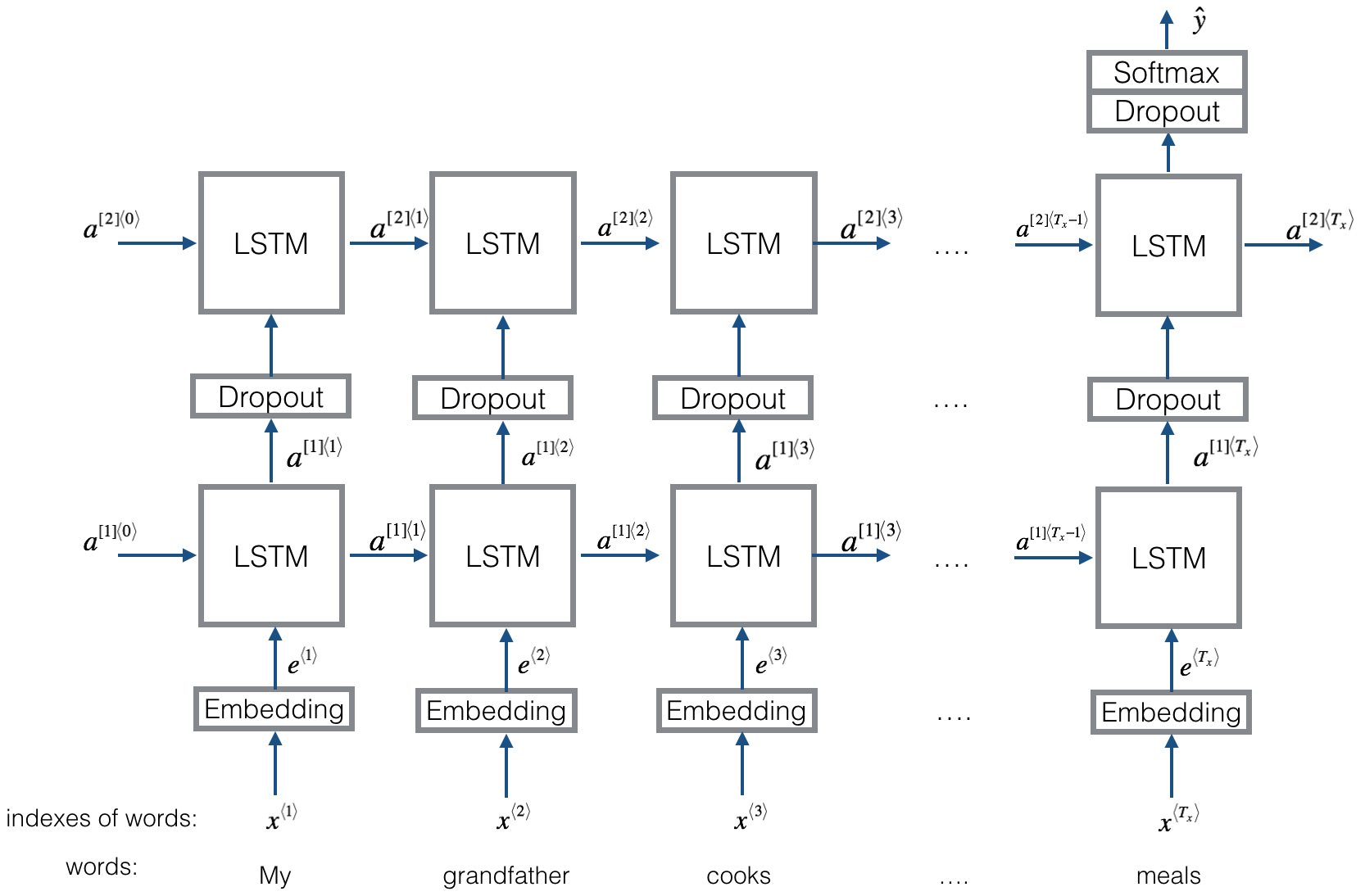
多层LSTM类似下图:
import torch
from torch import nn
# 单层LSTM
# 1层的LSTM,输入的每个词用100维向量表示,隐藏单元和记忆单元的尺寸是20
cell = nn.LSTMCell(input_size=100, hidden_size=20)
# seq_len=10个时刻的输入,每个时刻shape都是[batch,feature_len]
# x = [torch.randn(3, 100) for _ in range(10)]
x = torch.randn(10, 3, 100)
# 初始化隐藏单元h和记忆单元c,取batch=3
h = torch.zeros(3, 20)
c = torch.zeros(3, 20)
# 对每个时刻,传入输入xt和上个时刻的h和c
for xt in x:
b, c = cell(xt, (h, c))
print(b.shape) # torch.Size([3, 20])
print(c.shape) # torch.Size([3, 20])
# 两层LSTM
# 输入的feature_len=100,变到该层隐藏单元和记忆单元hidden_len=30
cell_L0 = nn.LSTMCell(input_size=100, hidden_size=30)
# hidden_len从L0层的30变到这一层的20
cell_L1 = nn.LSTMCell(input_size=30, hidden_size=20)
# 分别初始化L0层和L1层的隐藏单元h 和 记忆单元C,取batch=3
h_L0 = torch.zeros(3, 30)
C_L0 = torch.zeros(3, 30)
h_L1 = torch.zeros(3, 20)
C_L1 = torch.zeros(3, 20)
x = torch.randn(10, 3, 100)
for xt in x:
h_L0, C_L0 = cell_L0(xt, (h_L0, C_L0)) # L0层接受xt输入
h_L1, C_L1 = cell_L1(h_L0, (h_L1, C_L1)) # L1层接受L0层的输出h作为输入
print(h_L0.shape, C_L0.shape) # torch.Size([3, 30]) torch.Size([3, 30])
print(h_L1.shape, C_L1.shape) # torch.Size([3, 20]) torch.Size([3, 20])