1. 训练集&验证集&测试集
-
训练集:训练数据
-
验证集:验证不同算法(比如,利用网格搜索对超参数进行调整等),检验哪种更有效
-
测试集:正确评估分类器的性能
-
正常流程:
-
验证集会记录每个时间戳的参数
-
在加载test数据前会加载那个最好的参数,再来评估。
-
比方说训练完6000个epoch后,发现在第3520个epoch的validation表现最好,测试时会加载第3520个epoch的参数。
-
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
# 超参数
batch_size=200
learning_rate=0.01
epochs=10
# 获取训练数据
train_db = datasets.MNIST('../data', train=True, download=True, # train=True则得到的是训练集
transform=transforms.Compose([ # transform进行数据预处理
transforms.ToTensor(), # 转成Tensor类型的数据
transforms.Normalize((0.1307,), (0.3081,)) # 进行数据标准化(减去均值除以方差)
]))
# DataLoader把训练数据分成多个小组,此函数每次抛出一组数据。直至把所有的数据都抛出。就是做一个数据的初始化
train_loader = torch.utils.data.DataLoader(train_db, batch_size=batch_size, shuffle=True)
# 获取测试数据
test_db = datasets.MNIST('../data', train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
test_loader = torch.utils.data.DataLoader(test_db, batch_size=batch_size, shuffle=True)
#将训练集拆分成训练集和验证集
print('train:', len(train_db), 'dev:', len(test_db)) # train: 60000 dev: 10000
train_db, val_db = torch.utils.data.random_split(train_db, [50000, 10000])
print('db1:', len(train_db), 'db2:', len(val_db)) # db1: 50000 db2: 10000
train_loader = torch.utils.data.DataLoader(train_db, batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(val_db, batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential( #定义网络的每一层,
nn.Linear(784, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 10),
nn.ReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
net = MLP()
#定义sgd优化器,指明优化参数、学习率,net.parameters()得到这个类所定义的网络的参数[[w1,b1,w2,b2,...]
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss()
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28) # 将二维的图片数据摊平[样本数,784]
logits = net(data) # 前向传播
loss = criteon(logits, target) # nn.CrossEntropyLoss()自带Softmax
optimizer.zero_grad() # 梯度信息清空
loss.backward() # 反向传播获取梯度
optimizer.step() # 优化器更新
if batch_idx % 100 == 0: # 每100个batch输出一次信息
print('Train Epoch: {} [{}/{} ({:.0f}%)] Loss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
#验证集用来检测训练是否过拟合
val_loss = 0
correct = 0
for data, target in val_loader:
data = data.view(-1, 28 * 28)
logits = net(data) # 前向传播
val_loss += criteon(logits, target).item() # 代价函数
pred = logits.data.max(dim=1)[1]
correct += pred.eq(target.data).sum()
val_loss /= len(val_loader.dataset)
print('
VAL set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)
'.format(
val_loss, correct, len(val_loader.dataset),
100. * correct / len(val_loader.dataset)))
#测试集用来评估
test_loss = 0
correct = 0 # correct记录正确分类的样本数
for data, target in test_loader:
data = data.view(-1, 28 * 28)
logits = net(data)
test_loss += criteon(logits, target).item() # 其实就是criteon(logits, target)的值,标量
pred = logits.data.max(dim=1)[1] # 也可以写成pred=logits.argmax(dim=1)
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('
Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)
'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
view result
train: 60000 dev: 10000
db1: 50000 db2: 10000
Train Epoch: 0 [0/50000 (0%)] Loss: 2.301233
Train Epoch: 0 [20000/50000 (40%)] Loss: 2.121324
Train Epoch: 0 [40000/50000 (80%)] Loss: 1.711887
VAL set: Average loss: 0.0071, Accuracy: 6522/10000 (65%)
Train Epoch: 1 [0/50000 (0%)] Loss: 1.394418
Train Epoch: 1 [20000/50000 (40%)] Loss: 0.941196
Train Epoch: 1 [40000/50000 (80%)] Loss: 0.618081
VAL set: Average loss: 0.0027, Accuracy: 8606/10000 (86%)
Train Epoch: 2 [0/50000 (0%)] Loss: 0.451805
Train Epoch: 2 [20000/50000 (40%)] Loss: 0.463975
Train Epoch: 2 [40000/50000 (80%)] Loss: 0.389160
VAL set: Average loss: 0.0020, Accuracy: 8914/10000 (89%)
Train Epoch: 3 [0/50000 (0%)] Loss: 0.358770
Train Epoch: 3 [20000/50000 (40%)] Loss: 0.348269
Train Epoch: 3 [40000/50000 (80%)] Loss: 0.315913
VAL set: Average loss: 0.0018, Accuracy: 9030/10000 (90%)
Train Epoch: 4 [0/50000 (0%)] Loss: 0.314491
Train Epoch: 4 [20000/50000 (40%)] Loss: 0.347182
Train Epoch: 4 [40000/50000 (80%)] Loss: 0.208284
VAL set: Average loss: 0.0016, Accuracy: 9091/10000 (91%)
Train Epoch: 5 [0/50000 (0%)] Loss: 0.306007
Train Epoch: 5 [20000/50000 (40%)] Loss: 0.234249
Train Epoch: 5 [40000/50000 (80%)] Loss: 0.253510
VAL set: Average loss: 0.0015, Accuracy: 9160/10000 (92%)
Train Epoch: 6 [0/50000 (0%)] Loss: 0.307625
Train Epoch: 6 [20000/50000 (40%)] Loss: 0.311399
Train Epoch: 6 [40000/50000 (80%)] Loss: 0.332431
VAL set: Average loss: 0.0014, Accuracy: 9218/10000 (92%)
Train Epoch: 7 [0/50000 (0%)] Loss: 0.354180
Train Epoch: 7 [20000/50000 (40%)] Loss: 0.227610
Train Epoch: 7 [40000/50000 (80%)] Loss: 0.374276
VAL set: Average loss: 0.0014, Accuracy: 9224/10000 (92%)
Train Epoch: 8 [0/50000 (0%)] Loss: 0.199506
Train Epoch: 8 [20000/50000 (40%)] Loss: 0.288594
Train Epoch: 8 [40000/50000 (80%)] Loss: 0.371002
VAL set: Average loss: 0.0013, Accuracy: 9270/10000 (93%)
Train Epoch: 9 [0/50000 (0%)] Loss: 0.199139
Train Epoch: 9 [20000/50000 (40%)] Loss: 0.180454
Train Epoch: 9 [40000/50000 (80%)] Loss: 0.251302
VAL set: Average loss: 0.0012, Accuracy: 9320/10000 (93%)
Test set: Average loss: 0.0012, Accuracy: 9347/10000 (93%)
2. 正则化
正则化可以解决过拟合问题。
2.1 L2范数(更常用)
- 在定义优化器的时候设定
weigth_decay,即L2范数前面的 (lambda) 参数。
optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate, weight_decay=0.01)
2.2 L1范数(不咋用)
Pytorch没有直接可以调用的方法,实现如下:

3. 动量(Momentum)
- 使用
args.momentum
optimizer = torch.optim.SGD(model.parameters(), args=lr,
momentum=args.momentum,
weight_decay=args.weight_decay)

- 使用adam优化器
# 定义Adam优化器,指明优化目标是x,学习率是1e-3
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
4. 学习率衰减
torch.optim.lr_scheduler中提供了基于多种epoch数目 调整学习率的方法。
4.1 ReduceLROnPlateau
torch.optim.lr_scheduler.ReduceLROnPlateau:基于 测量指标 对学习率进行动态的下降
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min',
factor=0.1, patience=10, verbose=False,
threshold=0.0001, threshold_mode='rel',
cooldown=0, min_lr=0, eps=1e-08)
-
训练过程中,optimizer会把
learning rate交给scheduler管理- 当指标(比如loss)连续patience次数还没有改进时,需要降低学习率,factor为每次下降的比例。
-
scheduler.step(loss_val)每调用一次就会监听一次loss_val。
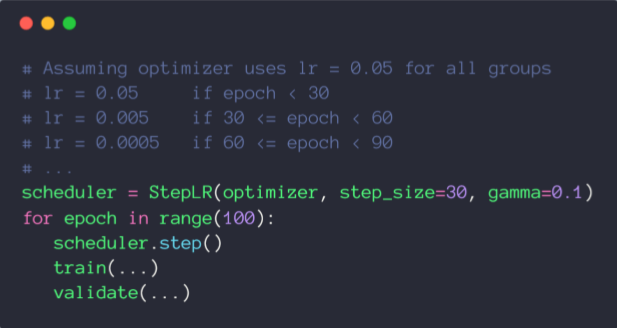
4.2 StepLR
torch.optim.lr_scheduler.StepLR:基于epoch
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
- 当epoch每过stop_size时,学习率都变为初始学习率的
gamma倍。
5. 提前停止(防止overfitting)
- 基于经验值
6. Dropout随机失活
-
遍历每一层,设置消除神经网络中的节点概率,得到精简后的一个样本。
-
torch.nn.Dropout(p=dropout_prob) -
p 表示的是 删除节点数 的比例(Tip:tensorflow中keep_prob表示保留节点数的比例,不要混淆)

-
测试阶段无需使用dropout
-
所以在train之前执行
net_dropped.train()相当于启用dropout -
测试之前执行
net_dropped.eval()相当于不启用dropout。
-
