1. 基于bs4库的HTML内容查找方法

1.1 <>.find_all() 和 re (正则表达式库)

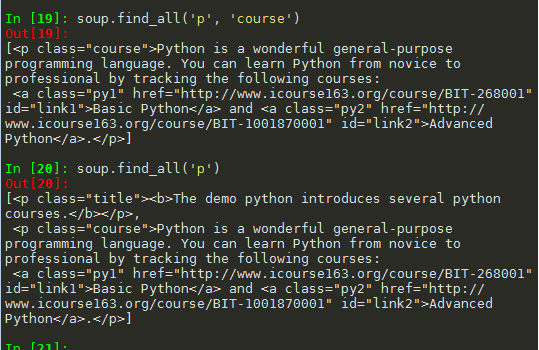
(1)参数为单一字符串

(2)参数为 列表
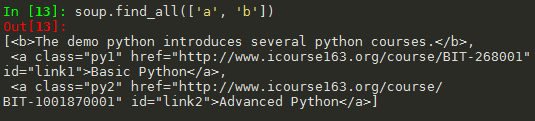
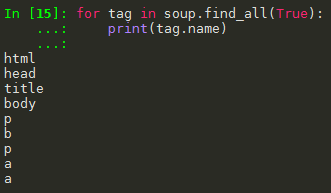
(3)参数为True,则返回所有标签内容
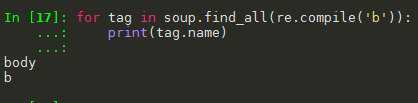
(4)显示 以 b 开头的标签,如 b,body。(使用 re:正则表达式库)
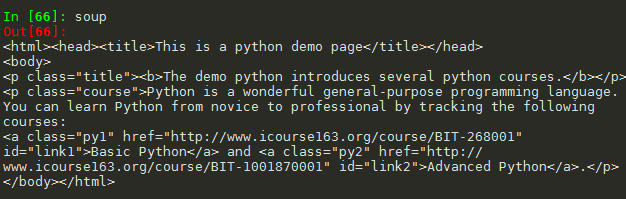
import requests from bs4 import BeautifulSoup import re r = requests.get("http://python123.io/ws/demo.html") demo = r.text soup = BeautifulSoup(demo, "html.parser") for tag in soup.find_all(re.compile('b')): print(tag.name)
(5)find_all中的 attrs:返回带有 attr属性值的 name标签

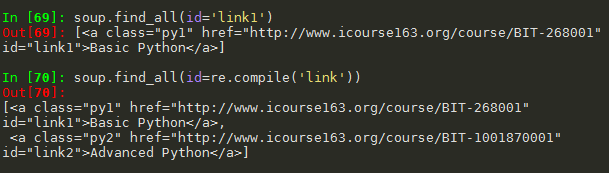
(6)查找 id属性,值为 link的数据 (正则表达式:https://www.cnblogs.com/douzujun/p/12241804.html#_label1)
(7)对该标签的子孙结点进行检索(True),只对该标签的儿子层面结点进行检索(False)


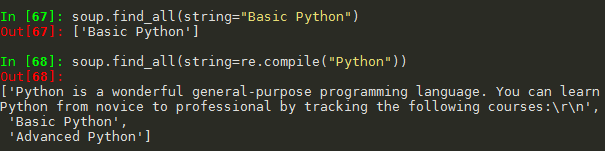
(8)对<>...</>中字符串区域的检索

1.2 find_all()简写

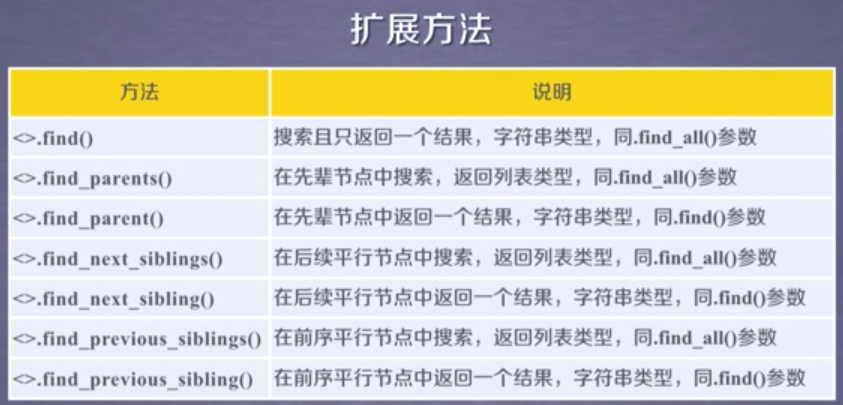
2. 扩展方法