从逻辑回归开始展示我们如何一点一点修改来得到本质上的支持向量机。

2. 支持向量机


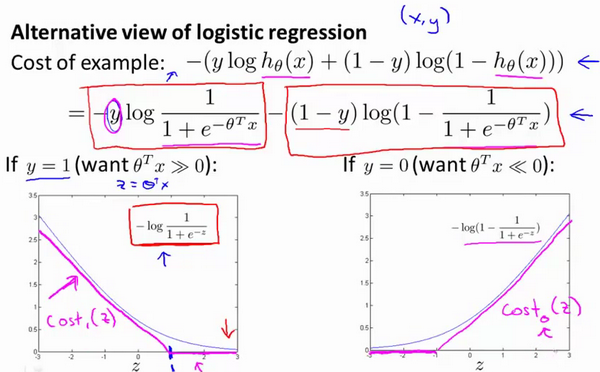
最后有别于逻辑回归输出的概率。在这里,我们的代价函数,当最小化代价函数,获得参数时,支持向量机所做的是它来直接预测 y 的值等于1,还是等于0。因此,这个假设函数会预测1。当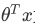 大于或者等于0时,或者等于0时,所以学习参数θ 就是支持向量机假设函数的形式。那么,这就是支持向量机数学上的定义。
大于或者等于0时,或者等于0时,所以学习参数θ 就是支持向量机假设函数的形式。那么,这就是支持向量机数学上的定义。
3. 大边界的直观理解
人们有时将支持向量机看作是 大间距分类器。在这一部分,我将介绍其中的含义,这有助于我们直观理解SVM模型的假设是什么样的。

支持向量机的要求更高,不仅仅要能正确分开输入的样本,即不仅仅要求>0,我们需要的是比0值大很多,比如大于等于1,我也想这个比0小很多,比如我希望它小于等于-1,这就相当于在支持向量机中嵌入了一个 额外的安全因子,或者说安全的间距因子。
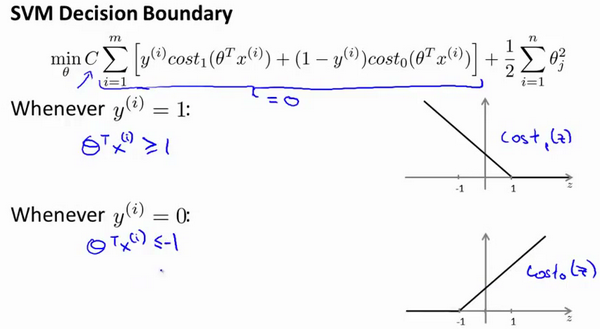
我们将这个常数C设置成一个非常大的值。比如我们假设C的值为100000或者其它非常大的数,然后来观察支持向量机会给出什么结果?
3.1 SVM决策边界(线性分类器)
-
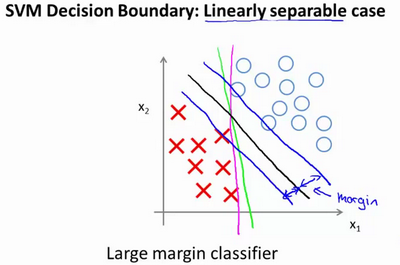
支持向量机将会选择这个黑色的决策边界,相较于之前我用粉色或者绿色画的决策界。这条黑色的看起来好得多,黑线看起来是更稳健的决策界。在分离正样本和负样本上它显得的更好。数学上来讲,这是什么意思呢?这条 黑线有更大的距离,这个距离叫做间距(margin)。
-
当画出这两条额外的蓝线,我们看到:黑色的决策界和训练样本之间有更大的最短距离。然而粉线和蓝线离训练样本就非常近,在分离样本的时候就会比黑线表现差。因此,这个距离叫:做支持向量机的间距,而这是支持向量机具有鲁棒性的原因,因为它努力用一个最大间距来分离样本。因此支持向量机有时被称为大间距分类器,而这其实是求解上一节优化问题的结果。
添加异常点
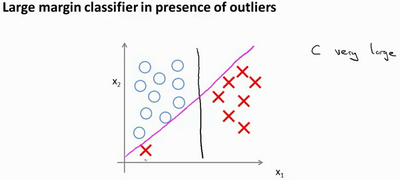
-
如果你将C设置的不要太大,则你最终会得到这条黑线。
-
应用支持向量机的时候,当C不是非常非常大的时候,它可以忽略掉一些异常点的影响,得到更好的决策界。甚至当你的数据不是线性可分的时候,支持向量机也可以给出好的结果。
-
回顾
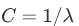 ,因此:
,因此: -
C 较大时,相当于 λ 较小,可能会导致过拟合,高方差。
-
C 较小时,相当于 λ 较大,可能会导致低拟合,高偏差。
4. 大边界分类背后的数学

这就是我们先前给出的支持向量机模型中的目标函数。为了讲解方便,我做一点简化,仅仅是为了让目标函数更容易被分析。
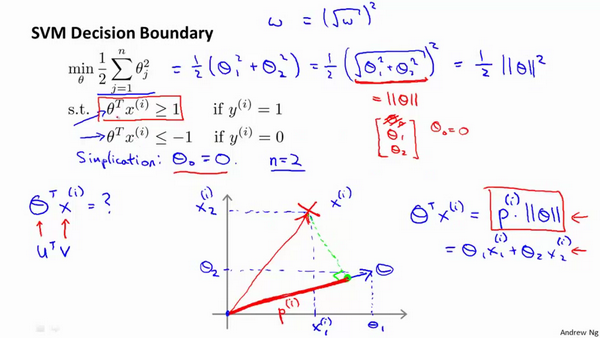
因此在我们接下来的推导中去掉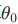 不会有影响。这意味着我们的目标函数:
不会有影响。这意味着我们的目标函数: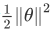
因此支持向量机做的全部事情,就是极小化参数向量θ**范数的平方,或者说长度的平方**。

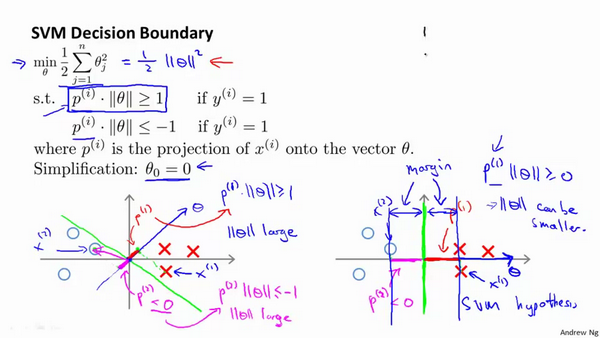
支持向量机最终会找到 大间距分类器的原因:它试图极大化这些的范数 ,它们是 训练样本到决策边界的距离。
,它们是 训练样本到决策边界的距离。
最后一点,我们的推导自始至终使用了这个简化假设,就是参数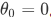 。
。

-
这个的作用是:
 :我们让决策界通过原点;
:我们让决策界通过原点; -
如果你令
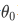 不是0:你希望决策界不通过原点。
不是0:你希望决策界不通过原点。 -
即便
不等于0,支持向量机要做的事情都是:优化这个目标函数对应着C值非常大的情况,但是可以说明的是,即便 不等于0,支持向量机仍然会找到正样本和负样本之间的大间距分隔。
5. 核函数1(思想)
5.1 高级数的多项式模型

5.2 高斯核函数
5.21 地标
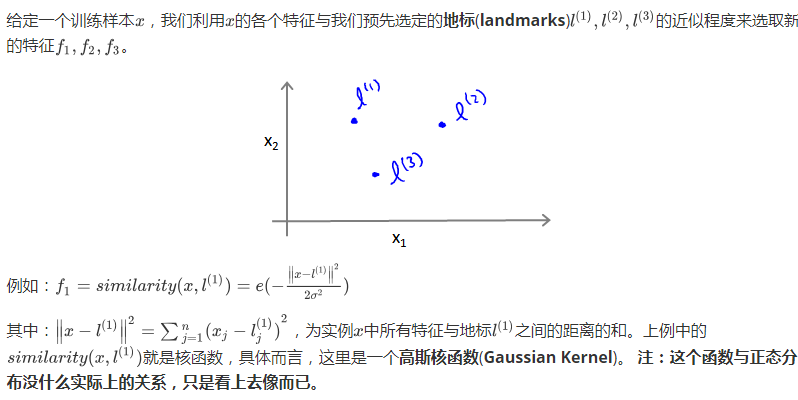
地标的作用:
-
因此,这些特征变量的作用是度量x到标记l的相似度。
-
如果训练样本 x 与 地标 l 之间的 距离,近似0,则,新特征 f,近似 1 【 e^(-0) 】
-
如果训练样本 x 与 地标 l 之间的 距离,较远, 则,新特征 f,近似 0 【 e^(- 一个较大数) 】
5.22 举例

注:σ越大,速率越慢;σ越小,速率越快。
5.23 通过标记点 和 相似函数(similarity)来定义新的特征变量,从而训练复杂的非线性分类器


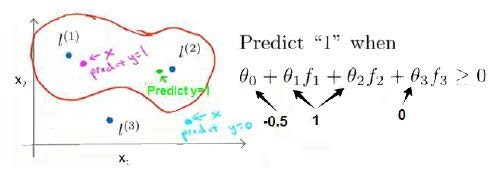
-
这样,图中红色的封闭曲线所表示的范围,便是我们 依据一个单一的训练样本和我们选取的地标所得出的判定边界。
-
在预测时,我们采用的特征不是训练样本本身的特征,而是通过核函数计算出的新特征f1, f2, f3
6. 核函数2(细节)☆☆☆☆☆
6.1 如何选择地标?
![]()

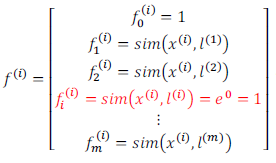
6.2 下面我们将核函数运用到支持向量机中
修改我们的支持向量机假设为
-
给定 x;
-
计算新特征 f(编写核函数);(见6.1)
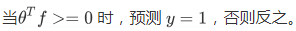 (θ0*f0 + θ1*f1+......θm*fm)
(θ0*f0 + θ1*f1+......θm*fm)-
修改相应代价函数(最小化代价,计算出θ)【注:通常不用自己最小化支持向量机的代价函数】;
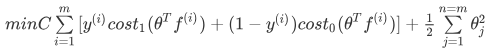
5. 正则化项进行些微调整
-
-
 【M是矩阵(依赖你采用的核函数)。目的:为了简化计算(适应超大数据集)】
【M是矩阵(依赖你采用的核函数)。目的:为了简化计算(适应超大数据集)】
-
注意:
-
我们不介绍最小化支持向量机的代价函数的方法,你可以使用现有的软件包(如liblinear,libsvm等)。
-
在使用这些软件包最小化我们的代价函数之前,我们通常需要编写核函数,并且【如果我们使用高斯核函数,那么在使用之前进行 特征缩放 是非常必要的】
-
不使用核函数又称为线性核函数(linear kernel),当我们不采用非常复杂的函数,或者我们的 训练集特征非常多 而 样本非常少 的时候,可以采用这种不带核函数的支持向量机。
下面是支持向量机的两个参数C和σ的影响:(选择在 cross-validation 数据集上表现最好的参数)
-
C = 1 / λ
-
C 较大时,相当于 λ 较小,可能会导致 过拟合,高方差;
-
C 较小时,相当于 λ 较大,可能会导致 低拟合,高偏差;(会忽略异常点)
-
σ 较大时,可能会导致 低方差,高偏差;(速率慢)
-
σ 较小时,可能会导致
7. 运行 支持向量机
-
选择参数 C 【运用库,如liblinear、libsvm等】
-
选择 核函数 或 要使用的 相似度函数 【注:线性核函数是未使用核函数】
-
线性核函数(训练集特征 非常多 而 样本 非常少)
-
高斯核函数 (原来的特征变量: x是 n × m 维,n(特征数)特别小;m(样本数)大小中等;需要拟合更复杂的非线性判定边界)
-
 (计算核函数的特定特征;将自动生成所有特征变量【x-->(f1,f2.....fm)】)
(计算核函数的特定特征;将自动生成所有特征变量【x-->(f1,f2.....fm)】) -
大小很不一样的特征变量使用前:进行归一化
- 其他核函数
-
多项式核函数(Polynomial Kernel)(内积值永不是负数)
-
字符串核函数(String kernel)、卡方核函数( chi-square kernel)、直方图交集核函数(histogram intersection kernel)
-
-
- 多分类问题
-
如果一共有个类,则我们需要 k 个模型,以及个 k 参数向量。需要:训练 k 个支持向量机 来解决多类分类问题。
-
但是大多数支持向量机软件包都有内置的多类分类功能,我们只要直接使用即可。

-
8. 选择逻辑回归还是支持向量机
(1) 如果相较于m而言,n(特征数)要大许多 , 即训练集数据量不够支持我们训练一个复杂的非线性模型, 我们选用 逻辑回归模型或者不带核函数的支持向量机。
(2) 如果 n较小,而且m大小中等,例如n在1-1000之间, 而m在10- 10000之间, 使用高斯核函数的支持向量机。
(3) 如果 n较小,而m较大, 例如n在1-1000之间, 而m大于50000 , 则使用支持向量机会非常慢。解决方案:创造、增加更多的特征, 然后使用逻辑回归 或 不带核函数的支持向量机。
值得一提的是,神经网络在以上三种情况下都可能会有较好的表现,但是训练神经网络可能非常慢, 选择支持向量机的原因:其 代价函数是凸函数,不存在局部最小值,
注:算法确实重要,但是通常更重要的是:
-
你有多少数据
-
你有多熟练
-
是否擅长做 误差分析 和 调试学习算法
-
如何设计新的特征变量
-
找出应该输入给学习算法的其它特征变量等方面