原文地址:https://blog.csdn.net/Hu_weichen/article/details/80820728
自己输入跑了一下:
#include <vector>
#define NULLKEY - 32768
class HashTable
{
public:
HashTable(int n);
~HashTable();
void InsertHash(int key);
int searchHash(int key);
void show();
private:
int hash(int key);
vector<int> elem;
int count;
int m;
};
HashTable::HashTable(int n):count(0),m(n)
{
for(int i =0 ;i <n;++i)
{
elem.push_back(NULLKEY);
}
}
HashTable::~HashTable()
{}
int HashTable::hash(int key)
{
return key % m;
}
void HashTable::InsertHash(int key)
{
int addr = hash(key);
while(NULLKEY != elem[addr])
{
addr = (addr+1)%m;
}
elem[addr] = key;
count++;
}
int HashTable::searchHash(int key)
{
int addr = hash(key);
while(elem[addr] != key)
{
addr = (addr +1)%m;
if(NULLKEY == elem[addr] || hash(key) == addr)
{
return -1;
}
}
return addr;
}
void HashTable::show()
{
for(int i = 0;i < m;i++)
{
cout << elem[i]<<endl;
}
}
int main()
{
int n,e,val;
vector<int> vec;
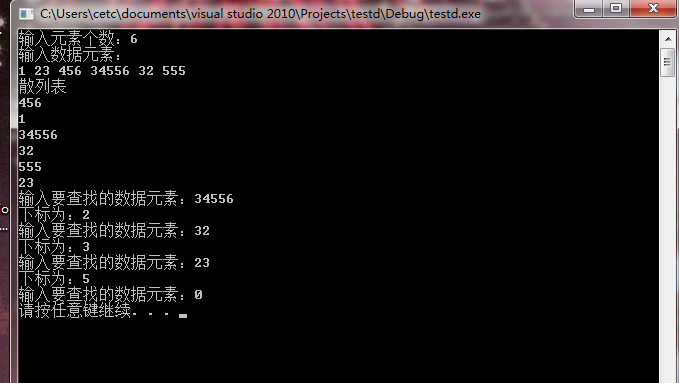
cout << "输入元素个数:";
cin >> n;
cout << "输入数据元素:"<<endl;
for(int i = 0; i < n ;i++)
{
cin >>e;
vec.push_back(e);
}
HashTable H(n);
for(int i =0;i<n;++i)
{
H.InsertHash(vec[i]);
}
cout<<"散列表"<<endl;
H.show();
while(1)
{
cout<<"输入要查找的数据元素:";
cin>>val;
e= H.searchHash(val);
if(-1 == e)
{
break;
cout<<"look up failed!"<<endl;
}
else
{
cout<<"下标为:"<<e<<endl;
}
}
system("pause");
}
以上是原文代码,主要说下自己输入的一点理解。
代码首先是构造了一个长度固定的vector来存储key值,当然这个固定的长度n也是手动输入的
散列函数用的是除留余数法
int HashTable::hash(int key)
{
return key % m;
}
主要是为了收敛key对应的地址,f(key)的值在0~m-1之间
插值函数:
void HashTable::InsertHash(int key)
{
int addr = hash(key);
while(NULLKEY != elem[addr])
{
addr = (addr+1)%m;
}
elem[addr] = key;
count++;
}
得到key的哈希地址addr之后,如果elem[addr]尚未被填充数据,则elem[addr] = key,否则addr加上一个偏移量继续直到找到未被填充数据的elem[addr], 原文这里addr = (addr+1)%key显然不对,因为地址显然在0~(m-1)之间移动,已修正
查找函数:
int HashTable::searchHash(int key)
{
int addr = hash(key);
while(elem[addr] != key)
{
addr = (addr +1)%m;
if(NULLKEY == elem[addr] || hash(key) == addr)
{
return -1;
}
}
return addr;
}
这个函数是整个里面唯一不太好理解的,这个要结合插值函数看,首先如果这个查询的key值存在对应的地址对应,那么在不断的偏移判断elem[addr] 是否为key的循环中,定然能找到elem[addr] = key的addr值,所以第一次情况如果NULLKEY == elem[addr] 了都没有将key值插入这个存储数组中,那显然这个key并没有对应的地址,这种情况存储的key地址对是小于m的,所以存在未填充key的地方,所以还存在第二种情形,key地址对与m,n是相等的,elem[]数组被填充满,addr+1地址从0~m-1遍历了一遍任未找到elem[addr] = key,然后又回到了0(假设从第一次哈希运算得到0),这时使得hash(key) == addr又重新成立,此种情形也能说明哈希表中不存在这个key值。