项目开发中,前端攻城狮往往走在UI的最前沿,在看脸的潮流下,提高网页的颜值,让用户过目不想忘那非前端不行了,当然少不了UI童鞋的脑洞大开。
HTML5的很多特性更是让攻城狮尽情的发挥化妆的基本技能,当然性能还是要考虑的,毕竟要有让更多的用户同时观赏的条件和能力,最近的项目中还是用到了web端获取多媒体文件的功能。简单描述一下,用户对着麦克风说话,获取语音流,经过编码获取base64传给后台的星弟们,调取模型然后返回给前台分析的结果,可能有文本结果,也可能有数字结果,毕竟维度那么多,比如流利不流利,准确不准确,感情是不是丰富等等,我们暂时不care,因为能看到这个文章的人,需要的结果肯定不一样。万变不离其宗,知道怎么拿到即可。
大致流程:
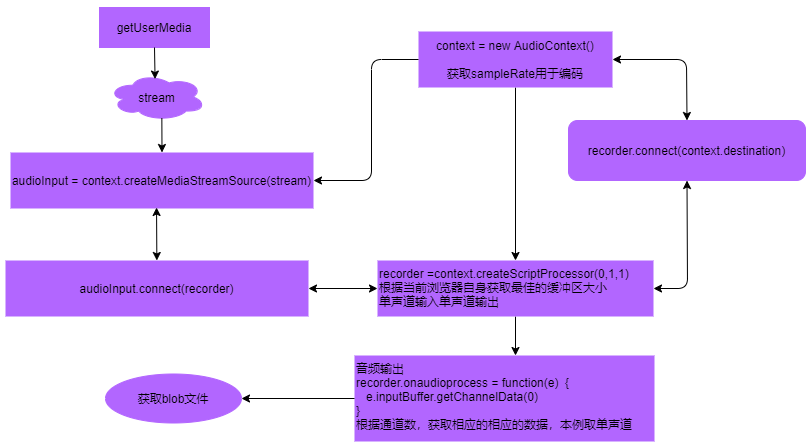
1、首先我们要从浏览器获取麦克风或者摄像头权限,出于隐私和安全,这是相当必要的通过getUserMedia,我们拿到了获取麦克风权限拿到了音频流stream。
2、通过AudioContext获取一个音频接收的实例context,音频实例我们拿到了,下一步是怎么设置缓冲区,这是要获取音频buffer最原始二进制流文件的地方。
3、通过context.createScriptProcessor产生了一个recorder,createScriptProcessor的三个参数分别表示缓冲区大小,输入通道数,输出通道数,缓冲区大小我们就不要随便写了,虽然正常是2的幂次,但是我们不知道什么时候是最好的,毕竟设备有区别,设为0让他自适应,通道数设置为1即可。
4、然后recorder和context.destination连接一下这个destination表示context中所有音频(节点)的最终目标节点,一般是音频渲染设备,比如扬声器。通过recorder的onaudioprocess事件就可以取到音频流了。当然为了获取到音频的音量大小到目前为止我们已经获取了基本的条件,距离成功只差和stream关联起来。
5、context的createMediaStreamSource我们取audioInput,接收一下stream,毕竟流文件已经来了,context不能闲着,打通最后一关,audioInput和recorder连接一下整个流程完成闭环。
参考文档:
3、github干货