一、动态参数
当我们有很多参数时,一个一个的去写形参,很感觉很麻烦,哪有什么简便的万能形参吗?答案是有的,那就是我们的动态参数!!!
昨天我们站在形参的角度可以把参数分为:位置参数和默认参数,今天我们将学习第三种:动态参数
1、动态接受位置参数
首先我们回顾一下位置参数,位置参数,按照位置进行传参(一定要注意实参与形参一一对应)
*args动态参数,万能参数,保存成一个元组
args接收的就是实参对应的所有位置参数,并将其放在元组中传给*后面的变量(可以通过Id查看变量的地址),注意的是,在def 函数名() 时就会给这个函数开辟一个内存地址,在之后学的return + 函数名时就是返回一个函数的内存地址
def chi(quality_food, junk_food): print("我要吃", quality_food, junk_food) chi("⼤⽶饭", "⼩米饭") # "⼤米饭"传递给quality_food "小米饭"传递给junk_food 按照位置传 现在问题来了. 我想吃任意的食物. 数量是任意的, 食物也是任意的. 这时我们就要用到 动态参数了. 在参数位置编写*表示接收任意内容 def chi(*food): print("我要吃", food) chi("⼤米饭", "⼩米饭") 结果: 我要吃 ('⼤米饭', '小米饭') # 多个参数传递进去. 收到的内容是元组tuple
需要注意的是这里将说有的位置参数打包成一个人元组赋值给food,所以打印food得到一个元组 动态接收参数的时候要注意: 动态参数必须在位置参数后面 def chi(*food, a, b): print("我要吃", food, a, b) chi("⼤米饭", "⼩米饭", "⻩瓜", "茄⼦") # 这里是要报错的,因为动态参数将所有位置参数接受完了 报错代码:Traceback (most recent call last): File "/Users/sylar/PycharmProjects/oldboy/fun.py", line 95, in <module> chi("⼤米饭", "⼩米饭", "⻩瓜", "茄子") TypeError: chi() missing 2 required keyword-only arguments: 'a' and 'b'
*args 名字可以改的,但是约定成熟使用*args
1.2、默认参数,运用关键字参数给出形参,当需要调用修改时才去修改
def chi(a, b, c='馒头', *food): print(a, b, c, food) chi("⾹蕉", "菠萝") # 香蕉 菠萝 馒头 (). 默认值⽣生效 chi("⾹蕉", "菠萝", "葫芦娃") # ⾹蕉 菠萝 葫芦娃 () 默认值不生效 chi("香蕉", "菠萝", "葫芦娃", "口罩") # ⾹蕉 菠萝 葫芦娃 ('口罩',) 默认值不生效 当位置参数占用默认参数时,就不会生效,且时动态影响动态参数 只有动态参数写在默认参数前,需要修改默认值时,运用关键字去修改 def chi(a, b, *food, c="娃哈哈"): print(a, b, food, c) chi("⾹蕉", "菠萝") # ⾹蕉 菠萝 () 娃哈哈 默认值生效 chi("⾹蕉", "菠萝", "葫芦娃") # ⾹蕉 菠萝 ('葫芦娃',) 娃哈哈 默认值生效 chi("⾹蕉", "菠萝", "葫芦娃", "口罩") # ⾹蕉 菠萝 ('葫芦娃', '口罩') 娃哈哈 默 认值⽣效
总结:在形参中在没有加动态关键字参数时的顺序: 位置参数 >>> *args >>> 默认参数 (因为默认参数在*args前,只要实参个数够多就会掩盖默认值)
2、动态接收关键字参数:
在python中可以动态的位置参数, 但是*这种情况只能接收位置参数⽆法接收关键字参数.在python中使⽤用**来接收动态关键字参数
**kwargs也是动态参数,和*args 不同的是,它只接收关键字参数.
**kwargs 动态传参,他将所有的关键字参数(未定义的)放到一个字典中
def func(**kwargs):
print(kwargs)
func(a=1, b=2, c=3)
func(a=1, b=2) #结果: {'a': 1, 'b': 2, 'c': 3} {'a': 1, 'b': 2},将传入的数据转换为字典
需要注意顺序的是:如果先给出关键字参数,则整个参数列表会报错,如 def func(a, b, c, d): print(a, b, c, d) # 关键字参数必须在位置参数后⾯面, 否则参数会混乱 func(1, 2, c=3, 4) # 一定注意关键字参数在后面
所以关键字参数必须在位置参数后⾯. 由于实参是这个顺序. 所以形参接收的时候也是这 个顺序. 也就是说位置参数必须在关键字参数前面. 动态接收关键字参数也要在后面 参数一定要从两种角度来看,一种是从实参,另一种是从形参上看
最终形参顺序(*): 位置参数 > *args > 默认值参数 > **kwargs 这四种参数可以任意的进⾏行行使⽤用. 最终实参参数顺序:
位置参数 > 关键字参数 如果想接收所有的参数: def func(*args, **kwargs): print(args, kwargs) func("麻花藤","⻢晕",wtf="胡辣汤")
2.1、动态参数的另一种传参方式(聚合与打散)
*魔法函数(聚合)
def func(*args): #形参实现聚合 print(args) #运行结果 (1, 2, 30) (1, 2, 30, 1, 2, 33, 21, 45, 66) l1 = [1,2,30] l2 = [1,2,33,21,45,66] #如何把两个列表赋值给args, func(*l1) func(*l1,*l2) #实参实现打散 当要打散字典时那: def func(**kwargs): print(kwargs) dic1 = {'name':'jack','age':22} dic2 = {'name1':'rose','age1':21} func(**dic1,**dic2) #{'name': 'jack', 'age': 22, 'name1': 'rose', 'age1': 21} 总结: *可迭代对象,代表打散(list,tuple,str,dict(键))将元素一一添加到args。 **字典,代表打散,将所有键值对放到一个kwargs字典里。 def func(*args,**kwargs): print(args,kwargs) dic1 = {'name':'jack','age':22} dic2 = {'name1':'rose','age1':21} func(*[1,2,3,4],*'asdk',**dic1,**dic2) 运行结果:(1, 2, 3, 4, 'a', 's', 'd', 'k') {'age1': 21, 'name': 'jack', 'age': 22, 'name1': 'rose'}# 1、解构时,出现这种情况,会让出位置
序列解压和打散:
1,当打散在前,后面参数不够时
*c,a,b = [1,2,3,4]
print(c) # [1,2]
2、当打散对象在前,但后面参数够时
*c,a,b,e,d = [1,2,3,4]
print(c) #[]
3,当打散对象在后时,
a,b,*c =[1,2,4,5]
print(c) #[4,5]
4,普通解压方式,注意字典打散接受的是键
a,_,_,d=(1,2,3,4)
>>> a # 1
>>> d # 4


def defult_param(a,l = []): l.append(a) print(l) defult_param('alex') defult_param('egon') 结果: ['alex'] ['alex', 'egon']
再谈聚合与打散:
def fun(*args):
print(args)
lst = [1, 4, 7]
fun(lst[0], lst[1], lst[2])
fun(*lst) # 可以使用*把⼀个列表按顺序打散 s = "⾂妾做不到"
fun(*s) # 字符串也可以打散, (可迭代对象)
在实参位置上给⼀个序列,列表,可迭代对象前⾯加个*表⽰把这个序列按顺序打散. 在形参的位置上的* 表⽰把接收到的参数组合成⼀个元组 如果是⼀个字典, 那么也可以打散. 不过需要用两个*
def fun(**kwargs): #在形参上聚合
print(kwargs)
dic = {'a':1, 'b':2}
dic_ = {'g':1,'c':3}
fun(**dic,**dic_) # 结果{'a': 1, 'b': 2, 'g': 1, 'c': 3},就是把传入的打散 ,实参上打散,把外皮剥了
总结:
args和 kwargs 是可以更换的,但是程序员约定都用它
用途:在不明确接受参数,数量时使用*args和**kwargs
动态位置参数 > 动态关键字参数
形参: 位置 > 动态位置 > 默认参数 > 动态默认参数
实参: 位置 > 关键字参数
在实参调用的时候 *将可迭代的对象打散,字典是将键取出
在形参处出现*就是在聚合
1、在实参调用的时候 **将字典打散成 2、关键字参数(键=值)
在形参处出现**就是将关键字参数聚合成一个字典
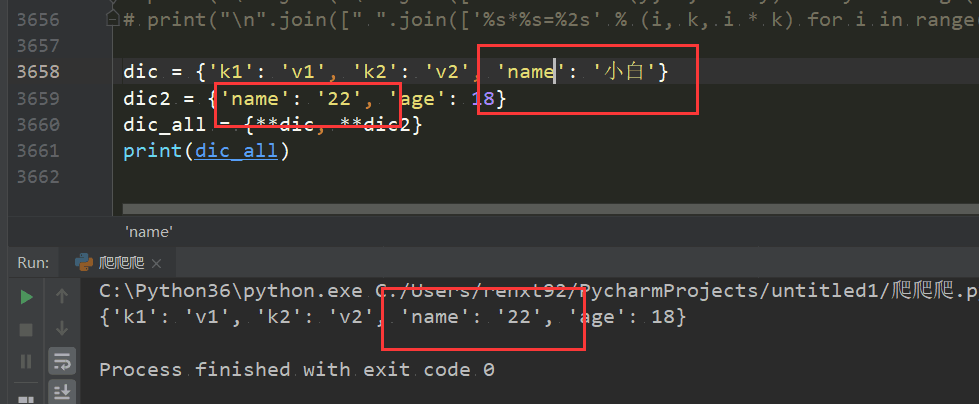
1、当字典不打散时,会被args接受 dic ={'a': 1, 'b': 1, 'c': 1} def func(a,b,c,*args,**kwargs): print(args,kwargs) func(1,2,3,dic) #({'a': 1, 'b': 1, 'c': 1},) {} 2、当字典的实参被一个*打散时,会生成已字典的键的元素 dic ={'a': 1, 'b': 1, 'c': 1} def func(a,b,c,*args,**kwargs): print(args,kwargs) #('a', 'b', 'c') {} func(1,2,3,*dic) # 这里将字典打散成键了,传给了args 3、

1、def func(a,b,c,d,*args,e='男',**kwargs): print(a,b,c,d,args,e,kwargs) func(1,2,3,4,5,6,7,v=3,m=7,h=9,e='女') # 1 2 3 4 (5, 6, 7) 女 {'v': 3, 'h': 9, 'm': 7} 2、当我们在实参上用两个*打散字典时, 要注意打散后字典的键不能和原有函数形参的参数重名 dic ={'a': 1, 'b': 1, 'c': 1} def func(e,*args,**kwargs): print(args,kwargs) #(2, 3) {'a': 1, 'b': 1, 'c': 1} func(1,2,3,**dic) # 这里将字典打散成a=1 b=1 c=1了,传给了args.最后经过函数形参*的聚合成为一个字典。 3、在函数中接收的*kwargs 是字典的键: dic ={'a': 1, 'b': 1, 'c': 1} def func(e,*args,**kwargs): print(args,*kwargs) # (2, 3) a b c func(1,2,3,**dic) 4、当使用两个**keargs时,打印就会报错。
3、函数的注释:(对函数的功能注释)
def chi(food, drink):
""" 这⾥是函数的注释 , 先写⼀下当前这个函数是⼲什么的 , 比如我这个函数就是一个吃
:param :param food: 参数 food 是什么意思
:param :param drink: 参数 drink 是什么意思
:return :return: 返回的是什么东东
"""
print(food, drink)
return "very good"
4、高阶函数:
接受一个函数作为参数的函数,称为高阶函数
5、如何查看一个包,类中所有可用的方法:
[x for x in dir(json) if not x.startswith('_')] [x for x in dir(os) if not x.startswith('_')] [x for x in dir(sys) if not x.startswith('_')] [x for x in dir(time) if not x.startswith('_')] [x for x in dir(list) if not x.startswith('_')] [x for x in dir(tuple) if not x.startswith('_')] [x for x in dir(set) if not x.startswith('_')] [x for x in dir(dict) if not x.startswith('_')]
help方法查看某个具体方法的使用:
help(类名) help(list)
help(类名.方法名) help(list.pop)
6,递归函数
在函数里面调用这个函数本身,叫做递归函数
def age(n):
if n == 1: # 递归函数需要设计一个出口,不然会一直递归下去
return 40
else:
return age(n-1)+2 # age(3)+2=>(age(2)+2)+2=>((age(1)+2)+2)+2
print(age(4)) # 46
menu = { '北京': { '海淀': { '五道口': { 'soho': {}, '网易': {}, 'google': {} }, '中关村': { '爱奇艺': {}, '汽车之家': {}, 'youku': {}, }, '上地': { '百度': {}, }, }, '昌平': { '沙河': { '老男孩': {}, '北航': {}, }, '天通苑': {}, '回龙观': {}, }, '朝阳': {}, '东城': {}, }, '上海': { '闵行': { "人民广场": { '炸鸡店': {} } }, '闸北': { '火车战': { '携程': {} } }, '浦东': {}, }, '山东': {}, } #代码实现 def threeLM(dic): while True: for k in dic:print(k) key = input('input>>').strip() if key == 'b' or key == 'q':return key elif key in dic.keys() and dic[key]: ret = threeLM(dic[key]) if ret == 'q': return 'q' threeLM(menu) 递归函数实现三级菜单
l=[menu] while l: print(l) for key in l[-1]:print(key) # 打印字典得键 k = input('input>>').strip() # 北京 if k in l[-1].keys() and l[-1][k]:l.append(l[-1][k]) #妙 满足条件则增加新环境 elif k == 'b':l.pop() elif k == 'q':break
二、命名空间
1、在python解释器开始执⾏之后, 就会在内存中开辟⼀个空间, 每当遇到⼀个变量的时候, 就 把变量名和值之间的关系记录下来, 但是当遇到函数定义的时候, 解释器只是把函数名读入内存,
表示这个函数存在了, ⾄于函数内部的变量和逻辑, 解释器是不关⼼的. 也就是说⼀开始的时候函数只是加载进来, 仅此⽽已, 只有当函数被调用和访问的时候, 解释器才会根据函数 内部声明
的变量量来进⾏开辟变量的内部空间. 随着函数执行完毕, 这些函数内部变量占⽤的空间也会随着函数执行完毕⽽被清空.
def fun(): a = 10 print(a) fun() print(a) # a不存在了已经
我们给存放名字和值的关系的空间起⼀个名字叫: 命名空间. 我们的变量在存储的时候就是存储在这片空间中的.
命名空间分类: (命名空间:存放名字与值的关系的空间)
1. 全局命名空间--> 代码在运行开始,创建的存储 “变量与值的关系”的空间
2. 局部命名空间--> 在函数的运行中开辟的临时空间
3. 内置命名空间--> 存放python解释器为我们提供的名字, list, tuple, str, int这些都是内置命名空间
加载顺序: 1. 内置命名空间
2. 全局命名空间
3. 局部命名空间(函数被执⾏的时候)
取值顺序: 1. 局部命名空间
2. 全局命名空间
3. 内置命名空间
2、 作⽤域: 作⽤域就是作用范围, 按照生效范围来看分为全局作⽤域和局部作用域
全局作⽤域: 包含内置命名空间和全局命名空间. 在整个⽂件的任何位置都可以使用(遵循 从上到下逐⾏执⾏).
局部作⽤域: 在函数内部可以使⽤.
作⽤域命名空间:
1. 全局作⽤域: 全局命名空间 + 内置命名空间
2. 局部作⽤域: 局部命名空间
我们可以通过globals()函数来查看全局作用域中的内容, 也可以通过locals()来查看局部作用域中的变量和函数信息
a = 10
def func():
a = 40
b = 20
def abc():
print("哈哈")
print(a, b) # 这⾥里里使⽤用的是局部作⽤用域
print(globals()) # 打印全局作⽤用域中的内容 包括一些内置函数
print(locals()) # 打印局部作⽤用域中的内容
func()
三、函数的嵌套
1、只要遇见了函数名()就是函数的调用,如果没有就不是函数的调用
2、函数的执行顺序
def fun1():
print(111)
def fun2():
print(222)
fun1() #从上至下依次执行
fun2()
print(111)
# 函数的嵌套
def fun2():
print(222)
def fun3():
print(666)
print(444)
fun3()
print(888)
print(33)
fun2()
print(555)
四、关键字global和nonlocal
⾸先我们写这样⼀个代码, 先在全局声明一个变量, 然后再局部调⽤用这个变量, 并改变这 个变量的值
a = 100
def func():
global a # 加了个global表示不再局部创建这个变量了. ⽽是直接使⽤全局的a
a = 28
print(a) #z注意再次调用的是全局的a,修改时同步到的
func()
print(a) # 28
def func():
global a
a = 28
print(a) #28 全局都没有找到这个a时,就会自动创建这个a
func()
print(a) # 2
lst = ["麻花藤", "刘嘉玲", "詹姆斯"]
def func():
lst.append("⻢云") # 对于可变数据类型可以直接进行访问. 但是不能改地址. 说⽩了. 不能赋值
print(lst)
func()
print(lst)
global和nonlocal关键:
global: 1、声明个全局变量 , 注意在全局都没有找到这个变量时,就会自动创建这个变量。
2、在局部作用域想要对全局变量进行修改时,需要用到global(限于字符串和数字)
nonlocal: 1、在局部寻找外层函数中离他最近的那个变量,可进行修改
2、注意它不能修改全局变量,只能在他的父级往上找直到全局变量,如果找不到就会报错
a = 10
def func1():
a = 20
def func2():
nonlocal a
a = 30
print(a)
func2()
print(a)
func1() #结果: 加了nonlocal 30 30 不加nonlocal 30 20
a = 10
def func1():
# a = 20 # 注释掉
def func2():
nonlocal a
a = 30
print(a)
func2()
print(a)
func1() # 报错,没有找到变量a,找到全局变量之前的都没找到所以报错,SyntaxError: no binding for nonlocal 'a' found
看看下面代码的结果:
a = 1
def fun_1():
a = 2
def fun_2():
global a
a = 3
def fun_3():
a = 4
print(a)
print(a)
fun_3()
print(a)
print(a)
fun_2()
print(a)
print(a)
fun_1()
print(a) #1,2, 3,4,3,2,3
再看看nonlocal的代码:
a = 1
def fun_1():
a = 2
def fun_2():
nonlocal a
a = 3
def fun_3():
a = 4
print(a)
print(a)
fun_3()
print(a)
print(a)
fun_2()
print(a)
print(a)
fun_1()
print(a) #1,2,3,4,3,3,1
易错点:
def wrapper():
print(a)
wrapper() # 结果:2 注意a 是全局作用域
a = 2
def wrapper():
def inner():
print(a)
# print(a)
inner()
wrapper() # 同理 结果也是2
def wrapper():
a = 1
def inner():
print(a)
inner()
wrapper() # 运行结果是1,可以调用局部没有去上一层拿
注意
def wrapper():
a = 1
def inner():
a += 1
print(a)
inner()
wrapper() 但是不能修改,除非用globa和nonlocal才能调用修改
cont = 9 def check(): print(cont) # 可以得到全局变量,但是不能修改 count += 1 # 报错要想修改全局变量需要global 引用一下 print(cont) check()
还有关于return的误区
def fun(a,b):
return print(a,b)
print(fun(3,1))
运行结果是 3,1 和None # 这里的return print(a,b) ==> print(a,b) return
a,b= 1,3
c = print(a,b)
print(c) #结果:1,3,None print执行后就是一个函数,这个函数是没有返回值的,
#可以理解位print函数里有一个return 所以接收的c为NOne效果一样
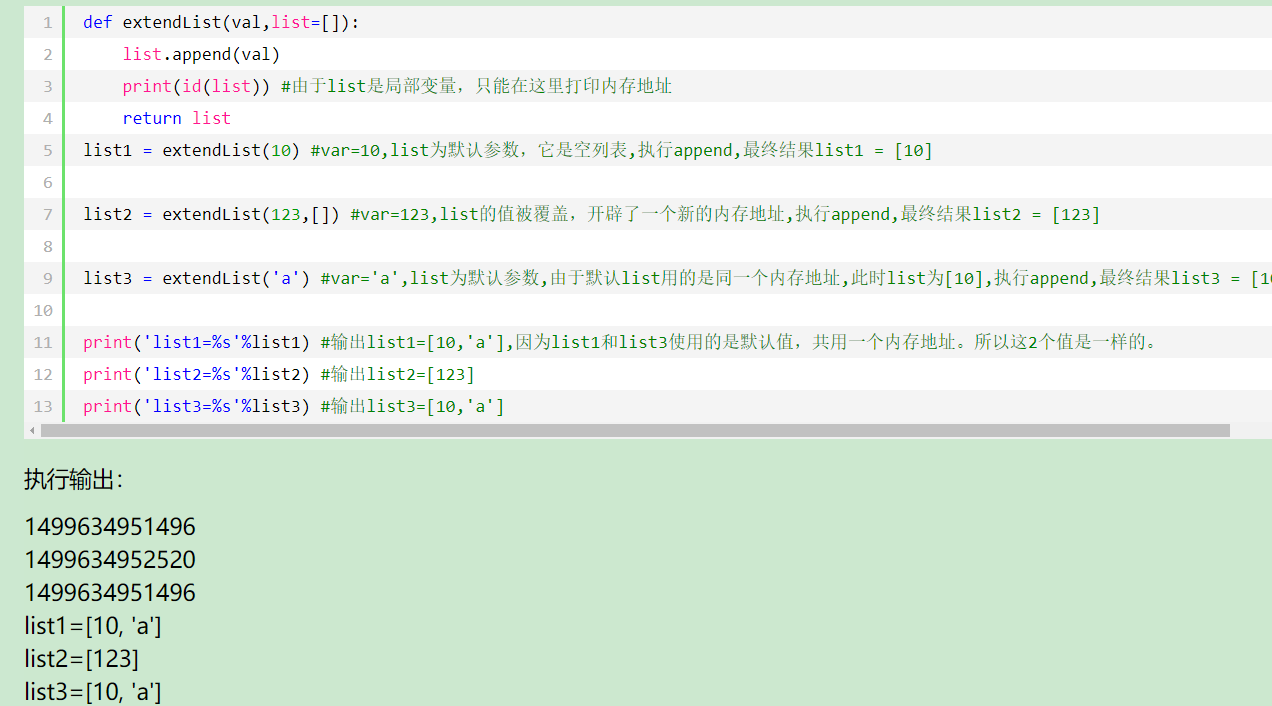
1、写函数,接收一个参数(此参数类型必须是可迭代对象),将可迭代对象的每个元素以’_’相连接,形成新的字符串,并返回. # 例如 传入的可迭代对象为[1,'老男孩','武sir']返回的结果为’1_老男孩_武sir’ def joi(*args): li=[] for i in args[0]: if type(i) != str: li.append(str(i)) else: li.append(i) return '_'.join(li) print(joi([1,'老男孩','武sir'])) 2、相关面试题(先从纸上写好答案,然后在运行): 1,有函数定义如下: def calc(a,b,c,d=1,e=2): return (a+b)*(c-d)+e 请分别写出下列标号代码的输出结果,如果出错请写出Error。 print(calc(1,2,3,4,5))__2___ print(calc(1,2))__Error__ print(calc(e=4,c=5,a=2,b=3))__24_ print(calc(1,2,3))__8___ print(calc(1,2,3,e=4))__10__ print(calc(1,2,3,d=5,4))__Error___ 2,下面代码打印的结果分别是_________,________,________. def extendList(val,list=[]): list.append(val) return list list1 = extendList(10) list2 = extendList(123,[]) list3 = extendList('a') print('list1=%s'%list1) print('list2=%s'%list2) print('list3=%s'%list3)