上一篇我们说了索引的重要性,一个索引不仅能让一条语句起飞,也能大量减少系统对CPU、内存、磁盘的依赖。我想上一篇中的例子可以说明了。给出上一篇和目录文链接:
SQL SERVER全面优化-------索引有多重要?
SQL SERVER全面优化-------Expert for SQL Server 诊断系列
书接前文,我们知道了索引的重要,也知道了索引怎么加,那么我们应该往那些语句加?语句一条一条漫无目的的优化么?我怎么找出系统的问题语句?怎么样的一个优先级?
很多对数据库了解不是很多的人,也许一片茫然!还真不知道,那么多存储过程,那么多程序语句,我总不能都看一遍吧?
对数据库有些了解的人可能会知道用profiler,系统视图等,这是个不错的方式!
但是个人觉得这些不够直观,还是不能抓住重点,如果业务多变也会消耗大量时间。
所谓工欲善其事,必先利其器!那么本篇我利用 Expert for sqlserver 讲述怎样抓住重点语句来优化你的系统!
首先还是上座驾:

--------------博客地址---------------------------------------------------------------------------------------
Expert 诊断优化系列 http://www.cnblogs.com/double-K/
废话不多说,直接开整-----------------------------------------------------------------------------------------
本文选用的例子为一个服务器高配,跑了一个小业务,硬件资源充足,但是语句执行很慢!(32CPU,32G内存跑了个只有10G 数据文件的库)
下面简单的一个展示:

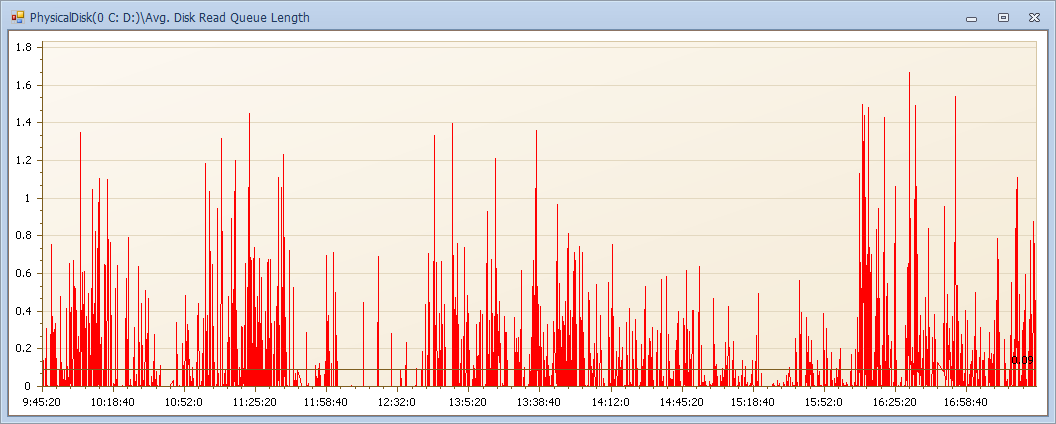

性能计数器指标请参见前文,本例中磁盘队列全天小于2,内存充足,CPU使用60%略有压力(主要是缺失索引导致)
下面看一下总体的语句执行情况:

语句可以看出超过1-3秒的语句有近8W次,3-5秒 5-10秒均接近2W,10秒以上的也有1W+,可见充足的资源配置下系统语句仍然很慢!
-
语句优先级
前面很多文章中都已经介绍过了,优化一定要针对重点语句,优化10条执行频率低的语句效果不及半条高频语句。那么找到系统中的高频语句就是优化的重中之重!
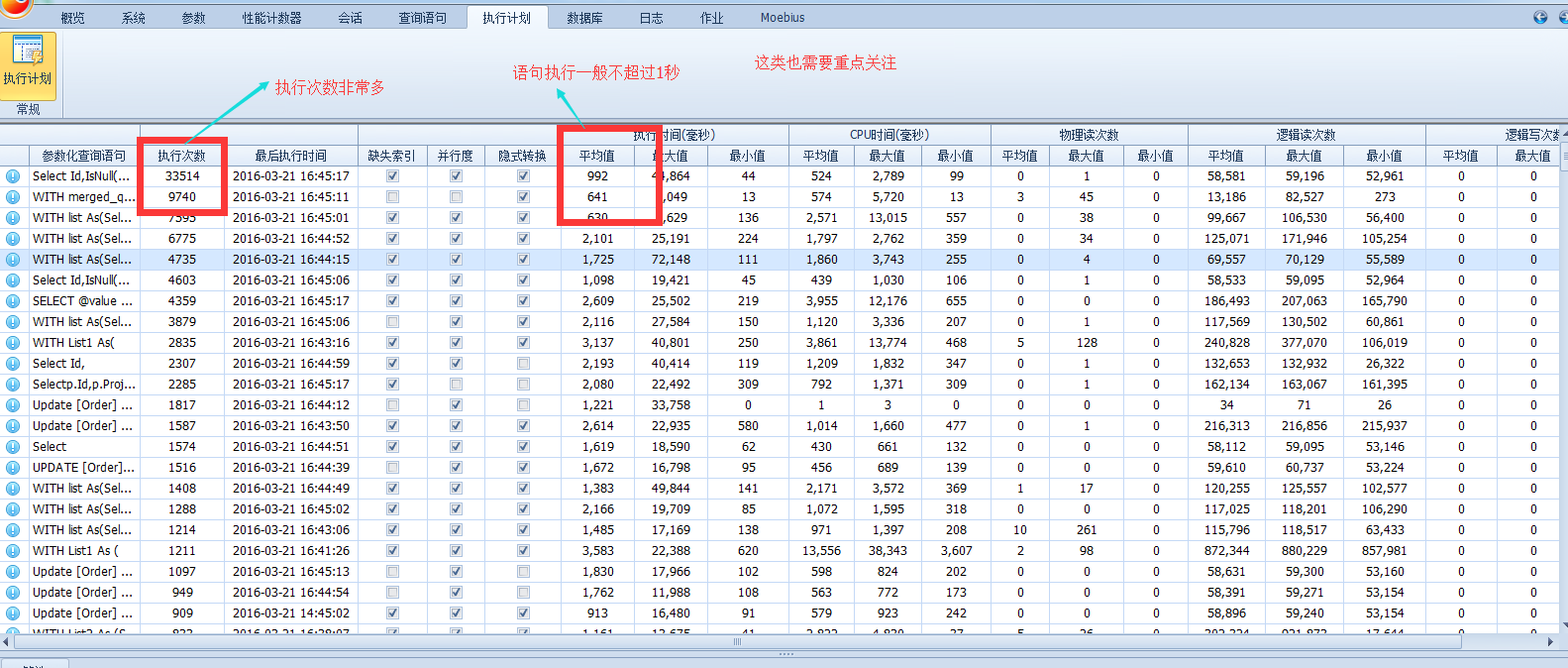
直接上图!

图中按照语句的执行次数排序,这也强烈符合我的优化套路,可以看出系统中执行频率最高的语句,平均执行时间都在3秒左右甚至更长,逻辑读都很高,但是影响的行数很少。这就是典型的缺少索引的情况!
高能提示: 看到这样的一个统计界面,你是否知道如何下手了?怎么样的一个优先级? 没错次数从高往低,来吧!开整!
根据个人习惯也可以按照逻辑读/写,cpu消耗等排出优先级。
-
针对语句调索引
拿到了重点语句,那么我们就从重点语句下手详细分析一下。上一篇已经介绍了简单粗暴的添加索引,简单粗暴大概能应对80%的场景了,但是也要有一些注意!下面新手看官们要认真体会了!


我们看到了缺失索引的提示,这就和前文介绍执行计划的大绿字是一个个东西。这里不再详细介绍。那么拿到这个索引缺失我们就直接创建么?前文中告诉你们的答案是直接创建!新的文章中当然要学点新东西!创建前请先核实一下索引!何为核实一下呢? 首先我们看一下执行计划!由于执行计划比较大只贴出消主要耗部分~


执行计划看出,缺失语句主要消耗在两部分,都是这个customer表,index scan 说明有相关字段的索引,但是不是最优的!那么提示的索引算是正确(字段验证这里就忽略了),那么现在可以创建了? 还需要再核查几个地方!
要创建索引的表有多少数据?

表上有150W+数据 确实适合创建索引!
是否有这个类似索引?
那么表上现在有什么索引呢?是新创建还是修改原有索引呢?

一堆索引...一屏没截下....但是你会发现一个覆盖索引都没有?也没有针对这条语句的最优索引! 也许这个系统的维护人员知道索引的重要性,但是不知道怎么创建一个最优的索引,HOHO 让他看看上篇文章就好了!
那么这回可以直接创建提示索引就OK了吧? 答案是大写的“NO”! 还需要你的细心!
创建的索引是否能使用?
前面 SQL SERVER全面优化-------写出好语句是习惯 已经提到过,where条件的字段中不能使用函数,不能有隐式转换,也不能用 like “%XXXX%” 这样就不能用索引查找seek了! 我们要看一下是否是提示的索引不能使用!
如果你仔细的看了前文,你会反问:不能用不是就不提示了么? 哈哈,真是认真,确实是这样!这里只是个需要细心的温馨提示!
但是每一篇文章重要更深入一下么,对吧! 前面看到原计划中customer表使用了index scan ,细心的看官们会发现还有个key lookup,index scan + key lookup 你不觉得奇怪么?

我们看一下具体的语句:语句太长,只贴where 部分了

我们可以看到customername 确实使用了 like ”%%“ 无法使用seek,但是companyid 和createdate 可以使用索引呀~所以我们再看一下 提示出的索引:
CREATE NONCLUSTERED INDEX [EFS_IX_Customer_b87864c46d0f4d3ca4ad4e4db8232063] ON [dbo].[Customer] ([CompanyId],[CreateDate]) INCLUDE ([Id],[CustomerId],[CustomerName],[Project],[IndustryOneId],[IndustryTwoId],[SourceId],[StateId],[TypeId],[ProtectId],[Audit],[delFlag]) GO
还是比较智能吧~这回你可以创建这个索引了!
还得啰嗦一句:覆盖索引虽好,但创建要注意,不要把过多的列放在索引里。个人建议索引的筛选列+包含列不要超过表字段的1/3 ,纯属个人建议不是那么绝对。
文章至此已经在上一篇的基础上又做了一些细节的说明。看官们可以按照优先级动手了。
-
大面积创建缺失索引
如果系统完全没有过保养,表上基本没有创建过什么索引,那么上面的创建方式一样很伤体力,这里还有一种简单粗暴的方式for you!

大批量创建索引切记不要看到就创建,一定是影响、开销、次数都很高的,并且要优化合并生成的脚本,也就是上一篇提到的精简索引!
-
根据执行计划创建
这种方式和根据语句创建有异曲同工之妙,但不同的是一般的收集工具只收集1秒以上的语句。默认超过1秒才算慢,但是系统中有些语句执行不到一秒,但非常高频,这也是需要关注的一大类! 限于篇幅这里就不展开说了!
--------------博客地址---------------------------------------------------------------------------------------
Expert 诊断优化系列 http://www.cnblogs.com/double-K/
-----------------------------------------------------------------------------------------------------
总结 : 往往一个系统的整体缓慢都是因为索引问题导致的,优化索引是对你系统最简单的保养!
不要小看一条语句的威力,一条语句足可以让你的系统彻底无法工作!
相反优化一条重要的高频语句就可以让你的系统变的流畅!
优化索引要有自己的方法,不能逮到一条做一条,效率又差又可能抓不住重点。
每个人优化都有自己的一套方法,只有是够系统,够全面就可以。本文只是简单介绍自己的优化方式,不喜勿喷~
Expert工具下载链接: http://www.grqsh.com/product_Expert.html
相关文章链接 :
SQL SERVER全面优化-------索引有多重要?
SQL SERVER全面优化-------写出好语句是习惯
Expert 诊断优化系列------------------语句调优三板斧
----------------------------------------------------------------------------------------------------
注:此文章为原创,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,非常感谢!
引用高大侠的一句话 :“拒绝SQL Server背锅,从我做起!”
为了方便阅读给出系列文章的导读链接: