状态码
状态码是HTTP请求过程结果的描述,由三位数字组成。这三位数字描述了请求过程中所发生的情况。状态码位于响应的起始行中,如在 HTTP/1.0 200 OK 中,状态码就是 200。
每个状态码的第一位数字都用于描述状态(“成功”、“出错”等)。
如200 到 299 之间的状态码表示成功;
300 到 399 之间的代码表示资源已经转移。
400 到 499 之间的代码表示客户端的请求出错了。
500 到 599 之间的代码表示服务器出错了。
| 整体范围 | 已定义范围 | 分 类 |
|---|---|---|
| 100~199 | 100~101 | 信息提示 |
| 200~299 | 200~206 | 成功 |
| 300~399 | 300~305 | 重定向 |
| 400~499 | 400~415 | 客户端错误 |
| 500~599 | 500~505 | 服务器错误 |
301,302,303,307
301
是永久重定向,常用的场景是使用域名跳转。
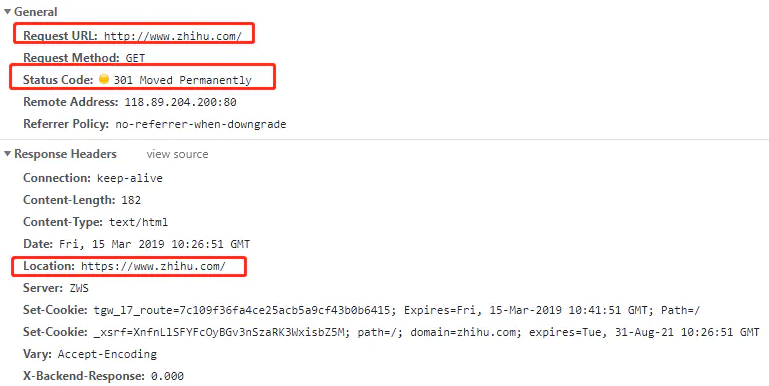
302
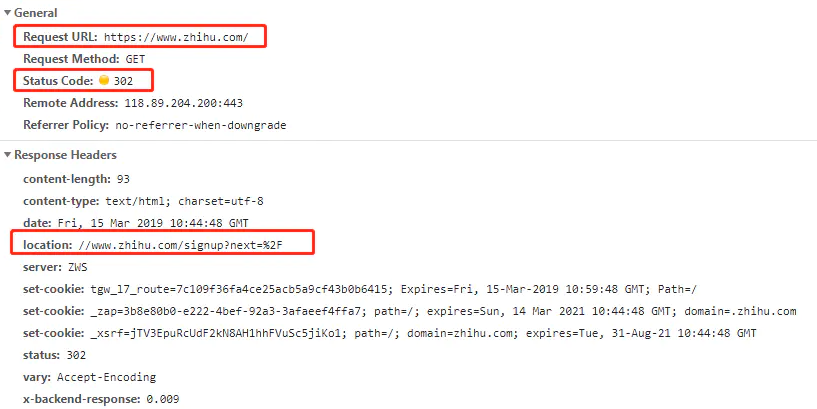
301和302都是代表重定向的意思。但有啥区别?
http 1.0规范中有2个重定向——301和302,在http 1.1规范中存在4个重定向——301、302、303和307。
其中301在http 1.0以及http 1.1中都表示永久重定向,就不讨论了。
那302呢?
在http1.0中,302的规范是这样的:
原请求是post,则不能自动进行重定向;原请求是get,可以自动重定向。
但是浏览器和服务器的实现并没有严格遵守HTTP中302的规范,服务器不加遵守的返回302,浏览器即便原请求是post也会自动重定向,导致规范和实现出现了二义性。
所以HTTP 1.1中将302的规范细化成了303和307
303和307
继承了HTTP 1.0中302的实现(即原请求是post,也允许自动进行重定向,结果是无论原请求是get还是post,都可以自动进行重定向)。
307则继承了HTTP 1.0中302的规范(即如果原请求是post,则不允许进行自动重定向,结果是post不重定向,get可以自动重定向)。
HTTP中的重定向和请求转发的区别
##转发是服务器行为,重定向是客户端行为。看两个动作的工作流程:##
转发过程:客户浏览器发送http请求——》web服务器接受此请求——》调用内部的一个方法在容器内部完成请求处理和转发动作——》将目标资源发送给客户;
在这里,转发的路径必须是同一个web容器下的url,其不能转向到其他的web路径上去,中间传递的是自己的容器内的request。在客户浏览器路径栏显示的仍然是其第一次访问的路径,也就是说客户是感觉不到服务器做了转发的。转发行为是浏览器只做了一次访问请求。
重定向过程:客户浏览器发送http请求——》web服务器接受后发送302状态码响应及对应新的location给客户浏览器——》客户浏览器发现是302响应,则自动再发送一个新的http请求,请求url是新的location地址——》服务器根据此请求寻找资源并发送给客户。
在这里location可以重定向到任意URL,既然是浏览器重新发出了请求,则就没有什么request传递的概念了。在客户浏览器路径栏显示的是其重定向的路径,客户可以观察到地址的变化的。重定向行为是浏览器做了至少两次的访问请求的。
重定向,其实是两次request
第一次,客户端request A,服务器响应,并response回来,告诉浏览器,你应该去B。这个时候IE可以看到地址变了,而且历史的回退按钮也亮了。重定向可以访问自己web应用以外的资源。在重定向的过程中,传输的信息会被丢失。
使用linux-curl抓去地址
curl不会进行跳转,curl -L会跟随跳转

curl是一种命令行工具,作用是发出网络请求,然后得到和提取数据。
我们直接在curl命令后加上网址,就可以看到网页源码。
curl www.baidu.comcurl 默认是不进行重定向的。如果要进行重定向,我们需要加上-L参数
curl -L taobao.com加上 -o 参数可以保存网页源代码到本地
curl -o taobao.txt taobao.com -L加上-i参数可以看到响应报文
curl -i baidu.com