前言
在之前 《Oracle打怪升级之路一》中我们主要介绍了Oracle的基础和Oracle常用查询及函数,这篇文章作为补充,主要介绍Oracle的对象,视图、序列、同义词、索引等,以及PL/SQL编程的相关知识
视图
什么是视图
视图是一种数据库对象,是从一个或者多个数据表或视图中导出的虚表,视图所对应的数据并不真正地存储在视图中,而是存储在所引用的数据表中,视图的结构和数据是对数据表进行查询的结果。根据创建视图时给定的条件,视图可以是一个数据表的一部分,也可以是多个基表的联合,它存储了要执行检索的查询语句的定义,以便在引用该视图时使用。
使用视图的优点:
- 简化数据操作:视图可以简化用户处理数据的方式。
- 着重于特定数据:不必要的数据或敏感数据可以不出现在视图中。
- 视图提供了一个简单而有效的安全机制,可以定制不同用户对数据的访问权限。
- 提供向后兼容性:视图使用户能够在表的架构更改时为表创建向后兼容接口。
创建或修改视图语法
语法
CREATE [OR REPLACE] [FORCE] VIEW view_name
AS subquery
[WITH CHECK OPTION ]
[WITH READ ONLY]
选项解释
- OR REPLACE :若所创建的试图已经存在,ORACLE 自动重建该视图;
- FORCE :不管基表是否存在 ORACLE 都会自动创建该视图;
- subquery :一条完整的 SELECT 语句,可以在该语句中定义别名;
- WITH CHECK OPTION :插入或修改的数据行必须满足视图定义的约束;
- WITH READ ONLY :该视图上不能进行任何 DML 操作。
删除视图的语法
DROP VIEW view_name;
案例
创建简单视图
需求:创建视图 :业主类型为 1 的业主信息
语句
create or replace view view_owners1 as
select * from T_OWNERS where ownertypeid=1
利用该视图进行查询
select * from view_owners1 where addressid=1;
就像使用表一样去使用视图就可以了。
对于简单视图,我们不仅可以用查询,还可以增删改记录。
我们下面写一条更新的语句,试一下:
update view_owners1 set name='王刚' where id=2;
我们再次查询表数据发现表的数据也跟着更改了。由此我们得出结论:视图其实是一个虚拟的表,它的数据其实来自于表。如果更改了视图的数据,表的数据也自然会变化,更改了表的数据,视图也自然会变化。一个视图所存储的并不是数据,而是一条 SQL语句。
带检查的约束视图
需求:根据地址表(T_ADDRESS)创建视图 VIEW_ADDRESS2 ,内容为区域 ID为 2 的记录。
语句
create or replace view view_address2 as
select * from T_ADDRESS where areaid=2
with check option
执行下列更新语句:
update view_address2 set areaid=1 where id=4
系统提示如下错误信息:

只读视图的创建与使用
如果我们创建一个视图,并不希望用户能对视图进行修改,那我们就需要创建视图时指定 WITH READ ONLY 选项,这样创建的视图就是一个只读视图。
需求:将上边的视图修改为只读视图
查询语句
create or replace view view_owners1 as
select * from T_OWNERS where ownertypeid=1
with read only
修改后,再次执行 update 语句,会出现如下错误提示

创建带错误的视图
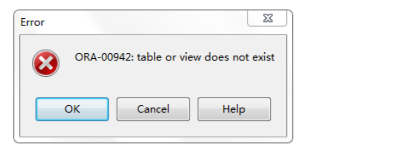
我们创建一个视图,如果视图的 SQL 语句所设计的表并不存在,如下
create or replace view view_TEMP as
select * from T_TEMP
T_TEMP 表并不存在,此时系统会给出错误提示
有的时候,我们创建视图时的表可能并不存在,但是以后可能会存在,我们如果
此时需要创建这样的视图,需要添加 FORCE 选项,SQL 语句如下:
create or replace FORCE view view_TEMP as
select * from T_TEMP
此时视图创建成功。
复杂视图的创建与使用
所谓复杂视图,就是视图的 SQL 语句中,有聚合函数或多表关联查询。
我们看下面的例子:
多表关联查询的例子
需求:创建视图,查询显示业主编号,业主名称,业主类型名称
查询语句
create or replace view view_owners as
select o.id 业主编号,o.name 业主名称,ot.name 业主类型
from T_OWNERS o,T_OWNERTYPE ot
where o.ownertypeid=ot.id;
使用该视图进行查询
select * from view_owners;
那这个视图能不能去修改数据呢?
我们试一下下面的语句:
update view_owners set 业主名称='范小冰' where 业主编号=1;
可以修改成功。
我们再试一下下面的语句:
update view_owners set 业主类型='普通居民' where 业主编号=1;
这次我们会发现,系统弹出错误提示:
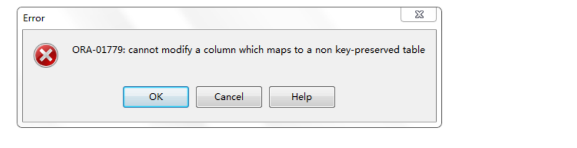
这个是什么意思?是说我们所需改的列不属于键保留表的列。
什么叫键保留表呢?
键保留表是理解连接视图修改限制的一个基本概念。该表的主键列全部显示在视图中,并且它们的值在视图中都是唯一且非空的。也就是说,表的键值在一个连接视图中也是键值,那么就称这个表为键保留表。
在我们这个例子中,视图中存在两个表,业主表(T_OWNERS)和业主类型表(T_OWNERTYPE), 其中 T_OWNERS 表就是键保留表,因为 T_OWNERS 的主键也是作为视图的主键。键保留表的字段是可以更新的,而非键保留表是不能更新的。
分组聚合统计查询视图
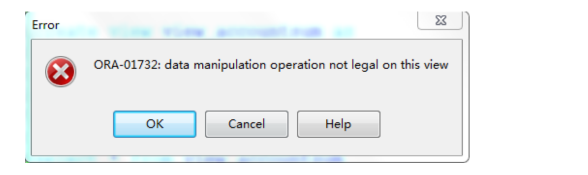
需求:创建视图,按年月统计水费金额,效果如下
create view view_accountsum as
select year,month,sum(money) moneysum
from T_ACCOUNT
group by year,month
order by year,month;
此例用到聚合函数,没有键保留表,所以无法执行 update
物化视图
什么是物化视图
视图是一个虚拟表(也可以认为是一条语句),基于它创建时指定的查询语句返回的结果集。每次访问它都会导致这个查询语句被执行一次。为了避免每次访问都执行这个查询,可以将这个查询结果集存储到一个物化视图(也叫实体化视图)。
物化视图与普通的视图相比的区别是物化视图是建立的副本,它类似于一张表,需要占用存储空间。而对一个物化视图查询的执行效率与查询一个表是一样的。
创建物化视图语法
CREATE METERIALIZED VIEW view_name
[BUILD IMMEDIATE | BUILD DEFERRED ]
REFRESH [FAST|COMPLETE|FORCE] [
ON [COMMIT |DEMAND ] | START WITH (start_time) NEXT
(next_time)
]
AS
subquery
语法解释
- BUILD IMMEDIATE 是在创建物化视图的时候就生成数据
- BUILD DEFERRED 则在创建时不生成数据,以后根据需要再生成数据。默认为 BUILD IMMEDIATE。
- 刷新(REFRESH):指当基表发生了 DML 操作后,物化视图何时采用哪种方式和基表进行同步。
REFRESH 后跟着指定的刷新方法有三种:FAST、COMPLETE、FORCE。FAST刷新采用增量刷新,只刷新自上次刷新以后进行的修改。COMPLETE 刷新对整个物化视图进行完全的刷新。如果选择 FORCE 方式,则 Oracle 在刷新时会去判断是否可以进行快速刷新,如果可以则采用 FAST 方式,否则采用 COMPLETE的方式。FORCE 是默认的方式。
刷新的模式有两种:ON DEMAND 和 ON COMMIT。ON DEMAND 指需要手动刷新物化视图(默认)。ON COMMIT 指在基表发生 COMMIT 操作时自动刷新。
案例
创建手动刷新的物化视图
需求:查询地址 ID,地址名称和所属区域名称, 结果如下:
create materialized view mv_address
as
select ad.id,ad.name adname,ar.name ar_name
from t_address ad,t_area ar
where ad.areaid=ar.id
执行上边的语句后查询
select * from mv_address;
这时,我们向地址表(T_ADDRESS)中插入一条新记录,
insert into t_address values(8,'宏福苑小区',1,1);
再次执行上边的语句进行查询,会发现新插入的语句并没有出现在物化视图中。
我们需要通过下面的语句(PL/SQL),手动刷新物化视图:
begin
DBMS_MVIEW.refresh('MV_ADDRESS','C');
end;
或者通过下面的命令手动刷新物化视图:
EXEC DBMS_MVIEW.refresh('MV_ADDRESS','C');
注意:此语句需要在命令窗口中执行。
执行此命令后再次查询物化视图,就可以查询到最新的数据了。
DBMS_MVIEW.refresh 实际上是系统内置的存储过程
创建自动刷新的物化视图
语句如下
create materialized view mv_address2
refresh
on commit
as
select ad.id,ad.name adname,ar.name ar_name
from t_address ad,t_area ar
where ad.areaid=ar.id
创建此物化视图后,当 T_ADDRESS 表发生变化时,MV_ADDRESS2 自动跟着改变。
创建时不生成数据的物化视图
create materialized view mv_address3
build deferred
refresh
on commit
as
select ad.id,ad.name adname,ar.name ar_name
from t_address ad,t_area ar
where ad.areaid=ar.id;
创建后执行下列语句查询物化视图
select * from mv_address3
执行下列语句生成数据
begin
DBMS_MVIEW.refresh('MV_ADDRESS3','C');
end;
由于我们创建时指定的 on commit ,所以在修改数据后能立刻看到最新数据,无须再次执行 refresh
创建增量刷新的物化视图
如果创建增量刷新的物化视图,必须首先创建物化视图日志
create materialized view log on t_address with rowid;
create materialized view log on t_area with rowid
创建的物化视图日志名称为 MLOG$_表名称
创建物化视图
create materialized view mv_address4
refresh fast
as
select ad.rowid adrowid ,ar.rowid arrowid, ad.id,ad.name
adname,ar.name ar_name
from t_address ad,t_area ar
where ad.areaid=ar.id;
注意:创建增量刷新的物化视图,必须:
- 创建物化视图中涉及表的物化视图日志。
- 在查询语句中,必须包含所有表的 rowid ( 以 rowid 方式建立物化视图日志 )
当我们向地址表插入数据后,物化视图日志的内容:

SNAPTIME$$:用于表示刷新时间。
DMLTYPE$$:用于表示 DML 操作类型,I 表示 INSERT,D 表示 DELETE,U表示 UPDATE。
OLD_NEW$$:用于表示这个值是新值还是旧值。N(EW)表示新值,O(LD)表示旧值,U 表示 UPDATE 操作。
CHANGE_VECTOR$$:表示修改矢量,用来表示被修改的是哪个或哪几个字段。此列是 RAW 类型,其实 Oracle 采用的方式就是用每个 BIT 位去映射一个列。插入操作显示为:FE, 删除显示为:OO 更新操作则根据更新字段的位置而显示不同的值。
当我们手动刷新物化视图后,物化视图日志被清空,物化视图更新。
begin
DBMS_MVIEW.refresh('MV_ADDRESS4','C');
end;
序列
什么是序列
序列是 ORACLE 提供的用于产生一系列唯一数字的数据库对象。
创建与使用简单序列
创建序列语法
-- 通过序列的伪列来访问序列的值
create sequence 序列名称;
语法解释
- NEXTVAL 返回序列的下一个值
- CURRVAL 返回序列的当前值
注意:我们在刚建立序列后,无法提取当前值,只有先提取下一个值时才能再次提取当前值。
提取下一个值
select 序列名称.nextval from dual
提取当前值
select 序列名称.currval from dual
创建复杂序列
CREATE SEQUENCE sequence //创建序列名称
[INCREMENT BY n] //递增的序列值是 n 如果 n 是正数就递增,如果是负数就递减 默
认是 1
[START WITH n] //开始的值,递增默认是 minvalue 递减是 maxvalue
[{MAXVALUE n | NOMAXVALUE}] //最大值
[{MINVALUE n | NOMINVALUE}] //最小值
[{CYCLE | NOCYCLE}] //循环/不循环
[{CACHE n | NOCACHE}];//分配并存入到内存中
案例
创建有最大值的非循环序列
创建序列语句
create sequence seq_test1
increment by 10
start with 10
maxvalue 300
minvalue 20
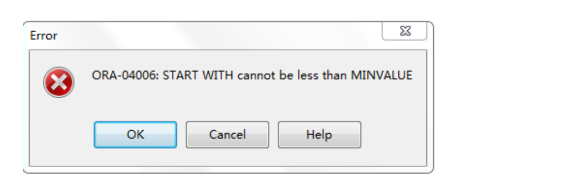
以上的错误,是由于我们的开始值小于最小值 。开始值不能小于最小值,修改以上语句:
create sequence seq_test1
increment by 10
start with 10
maxvalue 300
minvalue 5
我们执行下列语句提取序列值,当序列值为 300(最大值)的时候再次提取值,系统会报异常信息。

创建有最大值的循环序列
create sequence seq_test2
increment by 10
start with 10
maxvalue 300
minvalue 5
cycle ;
当序列当前值为 300(最大值),再次提取序列的值
select seq_test2.nextval from dual
循环的序列,第一次循环是从开始值开始循环,而第二次循环是从最小值开始循环。创建的是一个循环的序列,所以必须指定最大值,
创建带缓存的序列
create sequence seq_test3
increment by 10
start with 10
maxvalue 300
minvalue 5
cycle
cache 50;
我们执行上边语句的意思是每次取出 50 个缓存值,但是执行会提示错误
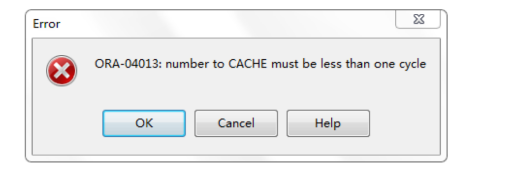
上边错误提示的意思是:缓存设置的数必须小于每次循环的数。
我们缓存设定的值是 50,而最大值是 300,那么为什么还会提示这样的信息呢?其实我们的 cache 虽然是 50,但是我们每次增长值是 10。这样 50 次缓存提取出的数是 500 (50*10)
我们更改为下列的语句:
create sequence seq_test4
increment by 10
start with 10
maxvalue 500
minvalue 10
cycle
cache 50;
下列语句依然会提示上边的错误,这是因为还存在一个 minvalue ,minvalue 和maxvalue 之间是 490 个数,也就是一次循环可以提取 490,但是我们的缓存是
500。
我们再次修改语句:
create sequence seq_test5
increment by 10
start with 10
maxvalue 500
minvalue 9
cycle
cache 50;
把最小值减 1,或把最大值加 1,都可以通过。
修改和删除序列
修改序列
使用 ALTER SEQUENCE 语句修改序列,不能更改序列的 START WITH 参数
ALTER SEQUENCE 序列名称 MAXVALUE 5000 CYCLE;
删除序列
DROP SEQUENCE 序列名称;
同义词
什么是同义词
同义词实质上是指定方案对象的一个别名。通过屏蔽对象的名称和所有者以及对分布式数据库的远程对象提供位置透明性,同义词可以提供一定程度的安全性。同时,同义词的易用性较好,降低了数据库用户的 SQL 语句复杂度。同义词允许基对象重命名或者移动,这时,只需对同义词进行重定义,基于同义词的应用程序可以继续运行而无需修改。
你可以创建公共同义词和私有同义词。其中,公共同义词属于 PUBLIC 特殊用户组,数据库的所有用户都能访问;而私有同义词包含在特定用户的方案中,只允许特定用户或者有基对象访问权限的用户进行访问。
同义词本身不涉及安全,当你赋予一个同义词对象权限时,你实质上是在给同义词的基对象赋予权限,同义词只是基对象的一个别名。
创建与使用同义词
创建同义词语法
create [public] SYNONYM synooym for object;
其中 synonym 表示要创建的同义词的名称,object 表示表,视图,序列等我们要创建同义词的对象的名称。
创建私有同义词
需求:为表 T_OWNERS 创建( 私有 )同义词 名称为 OWNERS
语句
create synonym OWNERS for T_OWNERS;
使用同义词
select * from OWNERS ;
创建公有同义词
需求:为表 T_OWNERS 创建( 公有 )同义词 名称为 OWNERS2:
create public synonym OWNERS2 for T_OWNERS;
索引
什么是索引
索引是用于加速数据存取的数据对象。合理的使用索引可以大大降低 i/o 次 数,从而提高数据访问性能。
索引是需要占据存储空间的,也可以理解为是一种特殊的数据。形式类似于下图的一棵“树”,而树的节点存储的就是每条记录的物理地址,也就是我们提到的伪列(ROWID)
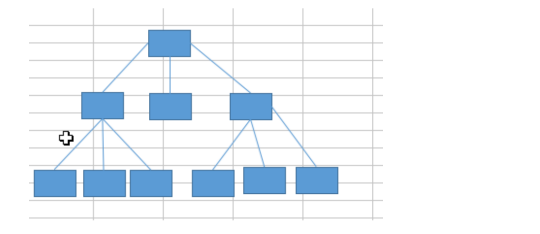
普通索引
创建语法
create index 索引名称 on 表名(列名);
需求:基于业主表的 name 字段来建立索引,创建语句
create index index_owners_name on T_OWNERS(name)
索引性能测试
- 创建一个两个字段的表
create table T_INDEXTEST (
ID NUMBER,
NAME VARCHAR2(30));
- 编写 PL/SQL 插入 100 万条记录
BEGIN
FOR i in 1..1000000
loop
INSERT INTO T_INDEXTEST VALUES(i,'AA'||i);
end loop;
commit;
END;
- 创建完数据后,根据 name 列创建索引
CREATE INDEX INDEX_TESTINDEX on T_INDEXTEST(name)
- 执行下面两句 SQL 执行
SELECT * from T_INDEXTEST where ID=765432;
SELECT * from T_INDEXTEST where NAME='AA765432';
我们会发现根据 name 查询所用的时间会比根据 id 查询所用的时间要短
唯一索引
如果我们需要在某个表某个列创建索引,而这列的值是不会重复的。这是我们可以创建唯一索引
创建语法
create unique index 索引名称 on 表名(列名);
需求:在业主表的水表编号一列创建唯一索引
create unique index index_owners_watermeter on T_OWNERS(watermeter);
复合索引
我们经常要对某几列进行查询,比如,我们经常要根据学历和性别对学员进行搜索,如果我们对这两列建立两个索引,因为要查两棵树,查询性能不一定高。那如何建立索引呢?我们可以建立复合索引,也就是基于两个以上的列建立一个索引 。
创建语法
create index 索引名称 on 表名(列名,列名.....);
根据地址和门牌号对学员表创建索引,语句如下
create index owners_index_ah
on T_OWNERS(addressid,housenumber);
反向键索引
应用场景:当某个字段的值为连续增长的值,如果构建标准索引,会形成歪脖子树。这样会增加查询的层数,性能会下降。建立反向键索引,可以使索引的值变得不规则,从而使索引树能够均匀分布。
创建语法
create index 索引名称 on 表名(列名) reverse;
位图索引
使用场景:位图索引适合创建在低基数列上。位图索引不直接存储 ROWID,而是存储字节位到 ROWID 的映射
优点:减少响应时间,节省空间占用
创建语法
create bitmap index 索引名称 on 表名(列名);
需求:我们在 T_owners 表的 ownertypeid 列上建立位图索引,创建语句
create bitmap index index_owners_typeid on T_OWNERS(ownertypeid)
PL/SQL
什么是PL/SQL
PL/SQL(Procedure Language/SQL)是 Oracle 对 sql 语言的过程化扩展,指在 SQL 命令语言中增加了过程处理语句(如分支、循环等),使 SQL 语言具有过程处理能力。把 SQL 语言的数据操纵能力与过程语言的数据处理能力结合起来,使得 PLSQL 面向过程但比过程语言简单、高效、灵活和实用。
基本语法结构
[declare
--声明变量
]
begin
--代码逻辑
[exception
--异常处理
]
end;
变量
变量声明
变量名 类型(长度);
变量赋值
变量名:=变量值
需求:声明变量水费单价、水费字数、吨数、金额。对水费单价、字数、进行赋值 。吨数根据水费字数换算,规则为水费字数除以1000,并且四舍五入,保留两位小数。计算金额,金额=单价*吨数。输出单价 、数量和金额。
--变量的用法--
declare
v_price number(10,2);--水费单价
v_usenum number; --水费字数
v_usenum2 number(10,2);--吨数
v_money number(10,2);--金额
begin
v_price:=2.45;--水费单价
v_usenum:=8012;--字数
--字数换算为吨数
v_usenum2:= round( v_usenum/1000,2);
--计算金额
v_money:=round(v_price*v_usenum2,2);
dbms_output.put_line('单价:'||v_price||'吨 数:'||v_usenum2||'金额:'||v_money);
end;
Select into 方式 赋值
select 列名 into 变量名 from 表名 where 条件
注意:结果必须是一条记录 ,有多条记录和没有记录都会报错
declare
v_price number(10,2);--单价
v_usenum number;--水费字数
v_num0 number;--上月字数
v_num1 number;--本月字数
v_usenum2 number(10,2);--使用吨数
v_money number(10,2);--水费金额
begin
--对单价进行赋值
v_price:=3.45;
--变量赋值
select usenum,num0,num1 into v_usenum,V_num0,V_num1 from
T_ACCOUNT
where year='2012' and month='01' and owneruuid=1;
v_usenum2:= round(v_usenum/1000,2);
v_money:=v_price*v_usenum2;
DBMS_OUTPUT.put_line('单价:'||v_price||'吨数:'
||v_usenum2||'金额:'||v_money||'上月字数:'||v_num0||'本月
字数'||v_num1);
end;
属性类型
%TYPE 引用型
作用:引用某表某列的字段类型
declare
v_price number(10,2);--单价
v_usenum T_ACCOUNT.USENUM%TYPE;--水费字数
v_num0 T_ACCOUNT.NUM0%TYPE;--上月字数
v_num1 T_ACCOUNT.NUM1%TYPE;--本月字数
v_usenum2 number(10,2);--使用吨数
v_money number(10,2);--水费金额
begin
--对单价进行赋值
v_price:=3.45;
--v_usenum:=8090;
select usenum,num0,num1 into v_usenum,V_num0,V_num1 from
T_ACCOUNT
where year='2012' and month='01' and owneruuid=1;
--使用吨数
v_usenum2:= round(v_usenum/1000,2);
--计算金额
v_money:=v_price*v_usenum2;
DBMS_OUTPUT.put_line('单价:'||v_price||'吨数:'
||v_usenum2||'金额:'||v_money||'上月字数:'||v_num0||'本月
字数'||v_num1);
end;
%ROWTYPE 记录型
作用: 标识某个表的行记录类型
--变量的用法--
declare
v_price number(10,2);--单价
v_account T_ACCOUNT%ROWTYPE;--记录型
v_usenum2 number(10,2);--使用吨数
v_money number(10,2);--水费金额
begin
--对单价进行赋值
v_price:=3.45;
--赋值
select * into v_account from T_ACCOUNT
where year='2012' and month='01' and owneruuid=1;
--使用吨数
v_usenum2:= round(v_account.usenum/1000,2);
--计算金额
v_money:=v_price*v_usenum2;
DBMS_OUTPUT.put_line('单价:'||v_price||'吨数:'
||v_usenum2||'金额:'||v_money||'上月字数:
'||v_account.num0||'本月字数'||v_account.num1);
end;
异常
在运行程序时出现的错误叫做异常发生异常后,语句将停止执行,控制权转移到 PL/SQL 块的异常处理部分。
异常有两种类型:
- 预定义异常 - 当 PL/SQL 程序违反 Oracle 规则或超越系统限制时隐式引发
- 用户定义异常 - 用户可以在 PL/SQL 块的声明部分定义异常,自定义的异常通过 RAISE 语句显式引发
预定义异常类型
Oracle 预定义异常 21 个
| 命名的系统异常 | 产生原因 |
|---|---|
| ACCESS_INTO_NULL | 未定义对象 |
| CASE_NOT_FOUND | CASE 中若未包含相应的 WHEN ,并且没有设置 ELSE 时 |
| COLLECTION_IS_NULL | 集合元素未初始化 |
| CURSER_ALREADY_OPEN | 游标已经打开 |
| DUP_VAL_ON_INDEX | 唯一索引对应的列上有重复的值 |
| INVALID_CURSOR | 在不合法的游标上进行操作 |
| INVALID_NUMBER | 内嵌的 SQL 语句不能将字符转换为数字 |
| NO_DATA_FOUND | 使用 select into 未返回行 |
| **TOO_MANY_ROWS ** | 执行 select into 时,结果集超过一行 |
| ZERO_DIVIDE | 除数为 0 |
| SUBSCRIPT_BEYOND_COUNT | 元素下标超过嵌套表或 VARRAY 的最大值 |
| SUBSCRIPT_OUTSIDE_LIMIT | 使用嵌套表或 VARRAY 时,将下标指定为负数 |
| VALUE_ERROR | 赋值时,变量长度不足以容纳实际数据 |
| LOGIN_DENIED | PL/SQL 应用程序连接到 oracle 数据库时,提供了不正确的用户名或密码 |
| NOT_LOGGED_ON | PL/SQL 应用程序在没有连接 oralce 数据库的情况下访问数据 |
| PROGRAM_ERROR | PL/SQL 内部问题,可能需要重装数据字典& pl./SQL 系统包 |
| ROWTYPE_MISMATCH | 宿主游标变量与 PL/SQL 游标变量的返回类型不兼容 |
| SELF_IS_NULL | 使用对象类型时,在 null 对象上调用对象方法 |
| STORAGE_ERROR | 运行 PL/SQL 时,超出内存空间 |
| SYS_INVALID_ID | 无效的 ROWID 字符串 |
| TIMEOUT_ON_RESOURCE | Oracle 在等待资源时超时 |
语法结构
exception
when 异常类型 then
异常处理逻辑
根据上例中的代码,添加异常处理部分
--变量的用法--
declare
v_price number(10, 2);--水费单价
v_usenum T_ACCOUNT.USENUM%type; --水费字数
v_usenum2 number(10, 3);--吨数
v_money number(10, 2);--金额
begin
v_price := 2.45;--水费单价
select usenum
into v_usenum
from T_ACCOUNT
where owneruuid = 1
and year = '2012'
and month = '01';
--字数换算为吨数
v_usenum2 := round(v_usenum / 1000, 3);
--计算金额
v_money := round(v_price * v_usenum2, 2);
dbms_output.put_line('单价:' || v_price || '吨 数:' || v_usenum2 || '金额:' || v_money);
exception
when NO_DATA_FOUND then
dbms_output.put_line('未找到数据,请核实');
when TOO_MANY_ROWS then
dbms_output.put_line('查询条件有误,返回多条信息,请核实');
end;
条件判断
基本语法1
if 条件 then
业务逻辑
end if;
基本语法2
if 条件 then
业务逻辑
else
业务逻辑
end if;
基本语法3
if 条件 then
业务逻辑
elsif 条件 then
业务逻辑
else
业务逻辑
end if;
需求:设置三个等级的水费 5 吨以下 2.45 元/吨 5 吨到 10 吨部分 3.45 元/吨 ,超过 10 吨部分 4.45 ,根据使用水费的量来计算阶梯水费。
declare
v_price1 number(10, 2);--不足 5 吨的单价
v_price2 number(10, 2);--超过 5 吨不足 10 吨单价
v_price3 number(10, 2);--超过 10 吨单价
v_account T_ACCOUNT%ROWTYPE;--记录型
v_usenum2 number(10, 2);--使用吨数
v_money number(10, 2);--水费金额
begin
-- 对单价进行赋值
v_price1 := 2.45;
v_price2 := 3.45;
v_price3 := 4.45;
-- 赋值
select *
into v_account
from T_ACCOUNT
where year = '2012'
and month = '01'
and owneruuid = 1;
-- 使用吨数
v_usenum2 := round(v_account.usenum / 1000, 2);
-- 计算金额(阶梯水费)
if v_usenum2 <= 5 then--第一个阶梯
v_money := v_price1 * v_usenum2;
elsif v_usenum2 > 5 and v_usenum2 <= 10 then --第二个阶梯
v_money := v_price1 * 5 + v_price2 * (v_usenum2 - 5);
else --第三个阶梯
v_money := v_price1 * 5 + v_price2 * 5 +
v_price3 * (v_usenum2 - 10);
end if;
DBMS_OUTPUT.put_line('吨数:'
|| v_usenum2 || '金额:' || v_money || '上月字数: ' || v_account.num0 || '本月字数' || v_account.num1);
exception
when NO_DATA_FOUND then
DBMS_OUTPUT.put_line('没有找到数据');
when TOO_MANY_ROWS then
DBMS_OUTPUT.put_line('返回的数据有多行');
end;
循环
无条件循环
语法结构
loop
--循环语句
end loop;
范例:输出从1开始的100个数
declare
v_num number := 1;
begin
loop
dbms_output.put_line(v_num);
v_num := v_num + 1;
exit when v_num > 100;
end loop;
end ;
条件循环
语法结构
while 条件
loop
end loop;
范例:输出从1开始的100个数
declare
v_num number := 1;
begin
while v_num <= 100
loop
dbms_output.put_line(v_num);
v_num := v_num + 1;
end loop;
end ;
for循环
基础语法
for 变量 in 起始值..终止值
loop
end loop;
范例:输出从1开始的100个数
begin
for v_num in 1..100
loop
dbms_output.put_line(v_num);
end loop;
end;
游标
什么是游标
游标是系统为用户开设的一个数据缓冲区,存放 SQL 语句的执行结果。我们可以把游标理解为 PL/SQL 中的结果集。

语法结构及示例
创建语法
cursor 游标名称 is SQL 语句;
使用游标语法
open 游标名称
loop
fetch 游标名称 into 变量
exit when 游标名称%notfound
end loop;
close 游标名称
需求:打印业主类型为 1 的价格表
代码
declare
v_pricetable T_PRICETABLE%rowtype;--价格行对象
cursor cur_pricetable is select *
from T_PRICETABLE
where ownertypeid = 1;--定义游标
begin
open cur_pricetable;--打开游标
loop
fetch cur_pricetable into v_pricetable;--提取游标到变量
exit when cur_pricetable%notfound;--当游标到最后一行下面退
出循环 dbms_output.put_line( '价格:'
||v_pricetable.price ||'吨位:'||v_pricetable.minnum||'-'||v_pricetable.maxnum );
end loop;
close cur_pricetable;--关闭游标
end ;
创建带参数的游标
我们的查询语句的条件值有可能是在运行时才能决定的,比如性业主类型,可能是运行时才可以决定,那如何实现呢?
我们接下来学习带参数的游标,修改上述案例
declare
v_pricetable T_PRICETABLE%rowtype;--价格行对象
cursor cur_pricetable(v_ownertypeid number) is select *
from T_PRICETABLE
where ownertypeid = v_ownertypeid;--定义游
标
begin
北京市昌平区建材城西路金燕龙办公楼一层 电话:400-618-9090
open cur_pricetable(2);--打开游标
loop
fetch cur_pricetable into v_pricetable;--提取游标到变量
exit when cur_pricetable%notfound;--当游标到最后一行下面退
出循环 dbms_output.put_line('价格:'||v_pricetable.price ||'吨
位:'||v_pricetable.minnum||'-'||v_pricetable.maxnum );
end loop;
close cur_pricetable;--关闭游标
end ;
for循环提取游标值
我们每次提取游标,需要打开游标 关闭游标 循环游标 提取游标 控制循环的退出等等,好麻烦!有没有更简单的写法呢?
有!用 for 循环一切都那么简单,上例的代码可以改造为下列形式
declare
cursor cur_pricetable(v_ownertypeid number) is
select * from T_PRICETABLEwhere ownertypeid = v_ownertypeid;--定义游标
begin
for v_pricetable in cur_pricetable(3)
loop
dbms_output.put_line('价格:' || v_pricetable.price ||
'吨位:' || v_pricetable.minnum || '-' || v_pricetable.maxnum);
end loop;
end ;
存储函数
什么是存储函数
存储函数又称为自定义函数。可以接收一个或多个参数,返回一个结果。在函数中我们可以使用 P/SQL 进行逻辑的处理。
存储函数语法结构
创建或修改存储过程的语法如下
CREATE
[ OR REPLACE ] FUNCTION 函数名称
(参数名称 参数类型, 参数名称 参数类型, ...
)
RETURN 结果变量数据类型
IS
变量声明部分;
BEGIN
逻辑部分;
RETURN 结果变量;
[
EXCEPTION
异常处理部分]
END;
案例
需求: 创建存储函数,根据地址 ID 查询地址名称。
创建语句
create function fn_getaddress(v_id number)
return varchar2
is
v_name varchar2(30);
begin
select name into v_name from t_address where id=v_id;
return v_name;
end;
测试此函数
select fn_getaddress(3) from dual
需求:查询业主 ID,业主名称,业主地址,业主地址使用刚才我们创建的函数来实现。
select id 编号,name 业主名称,fn_getaddress(addressid) 地址
from t_owners
存储过程
什么是存储过程
存储过程是被命名的 PL/SQL 块,存储于数据库中,是数据库对象的一种。应用程序可以调用存储过程,执行相应的逻辑。存储过程与存储函数都可以封装一定的业务逻辑并返回结果,存在区别如下:
- 存储函数中有返回值,且必须返回;而存储过程没有返回值,可以通过传出参数返回多个值。
- 存储函数可以在 select 语句中直接使用,而存储过程不能。过程多数是被应用程序所调用。
- 存储函数一般都是封装一个查询结果,而存储过程一般都封装一段事务代码。
存储过程语法结构
创建或修改存储过程的语法如下:
CREATE
[ OR REPLACE ] PROCEDURE 存储过程名称
(参数名 类型, 参数名 类型, 参数名 类型
)
IS|AS
变量声明部分;
BEGIN
逻辑部分
[EXCEPTION
异常处理部分]
END;
参数只指定类型,不指定长度
过程参数的三种模式:
- IN 传入参数(默认)
- OUT 传出参数 ,主要用于返回程序运行结果
- IN OUT 传入传出参数
案例
创建不带传出参数的存储过程:添加业主信息
--增加业主信息序列
create sequence seq_owners start with 11;
--增加业主信息存储过程
create or replace procedure pro_owners_add(
v_name varchar2,
v_addressid number,
v_housenumber varchar2,
v_watermeter varchar2,
v_type number
)
is
begin
insert into T_OWNERS
values (seq_owners.nextval, v_name, v_addressid, v_housenumb
er, v_watermeter, sysdate, v_type);
commit;
end;
PL/SQL 中调用存储过程
call pro_owners_add('赵伟',1,'999-3','132-7',1);
创建带传出参数的存储过程
需求:添加业主信息,传出参数为新增业主的 ID
--增加业主信息存储过程
create or replace procedure pro_owners_add(
v_name varchar2,
v_addressid number,
v_housenumber varchar2,
v_watermeter varchar2,
v_type number,
v_id out number
)
is
begin
select seq_owners.nextval into v_id from dual;
insert into T_OWNERS
values (v_id, v_name, v_addressid, v_housenumber, v_watermete
r, sysdate, v_type);
commit;
end;
PL/SQL 调用该存储过程
declare
v_id number;--定义传出参数的变量
begin
pro_owners_add('王旺旺', 1, '922-3', '133-7', 1, v_id);
DBMS_OUTPUT.put_line('增加成功,ID:' || v_id);
end;
触发器
什么是触发器
数据库触发器是一个与表相关联的、存储的 PL/SQL 程序。每当一个特定的数据操作语句(Insert,update,delete)在指定的表上发出时,Oracle 自动地执行触发器中定义的语句序列。
触发器的作用
- 数据确认
- 实施复杂的安全性检查
- 做审计,跟踪表上所做的数据操作等
- 数据的备份和同步
触发器的分类
- 前置触发器(BEFORE)
- 后置触发器(AFTER)
创建触发器的语法
语法
CREATE [or REPLACE] TRIGGER 触发器名
BEFORE | AFTER
[DELETE ][[or] INSERT] [[or]UPDATE [OF 列名]]
ON 表名
[ FOR EACH ROW ][WHEN(条件) ]
declare
……
begin
PLSQL 块
End ;
FOR EACH ROW 作用是标注此触发器是行级触发器 语句级触发器
在触发器中触发语句与伪记录变量的值
| 触发语句 | :old :new | :new |
|---|---|---|
| Insert | 所有字段都是空(null) | 将要插入的数据 |
| Update | 更新以前该行的值 | 更新后的值 |
| delete | 删除以前该行的值 | 所有字段都是空(null) |
案例
前置触发器
需求:当用户输入本月累计表数后,自动计算出本月使用数 。
语句:
create or replace trigger tri_account_updatenum1
before
update of num1
on t_account
for each row
declare
begin
:new.usenum:=:new.num1-:new.num0;
end;
后置触发器
需求:当用户修改了业主信息表的数据时记录修改前与修改后的值
--创建业主名称修改日志表:用于记录业主更改前后的名称
create table t_owners_log
(
updatetime date,
ownerid number,
oldname varchar2(30),
newname varchar2(30)
);
--创建后置触发器,自动记录业主更改前后日志
create trigger tri_owners_log
after
update of name
on t_owners
for each row
declare
begin
insert into t_owners_log
values(sysdate,:old.id,:old.name,:new.name);
end;
测试
--更新数据
update t_owners set name='杨小花' where id=3;
commit;
--查询日志表
select * from t_owners_log;