总结一下spark的调优方案--性能调优:
一、调节并行度
1、性能上的调优主要注重一下几点:
Excutor的数量
每个Excutor所分配的CPU的数量
每个Excutor所能分配的内存量
Driver端分配的内存数量
2、如何分配资源
在生产环境中,提交spark作业的时候,使用的是spark-submit shell脚本,里面调整对应的参数。
./bin/spark-submit --class com.spark.sparkTest.WordCount --num-executors 3 #此处配置的是executor的数量 --driver-memory 100m #此处配置的是driver的内存(影响不大) --executor-memory 100m #配置每个executor的内存大小 --total-executor-core 3 #配置所有executor的cpu core 数量 /usr/local/SparkTest-0.0.1-SNAPSHOT-jar-with-dependencies.jar
如何调节呢??
常用的资源调度模式有两种Spark Standalone 和 Spark on Yarn 。比如说你的每台机器能够给你使用60G内存,10个core,20台机器。那么executor的数量是20个。平均每个executor所能分配60G内存和10个CPU core。
以上面为计算原则:
增加executor:
如果executor比较少的话,那么能够并行执行的task的数量就很少,就意味着,我们的Application的并行执行的能力就很弱。
如果有3个executor,每个executor有2个core,那么同时就能够执行6个task。
增加了executor之后,意味着能够并行更多的task。所以速度也就比以前提升了数倍。
增加每个executor的cpu core:
增加了执行的并行能力,原来有3个executor,每个有2个core,现在有每个executor有4个core。那么现在的并行task数量是12,相比以前的6,从物理性能上看提升了2倍。
增加每个executor的内存大小:
增加内存后主要提升了一下三点:
1、若是RDD进行了cache,那么有了更多的内存,就可以缓存更多的数据,写入磁盘的数据就少了,甚至是可以不用写入磁盘了,就减少的磁盘IO,写入速度明显加快。
2、对于shuffle操作,reduce端,会需要内存来存放拉取的数据进行聚合,如果内存不够,也会写入磁盘,如果分配更多的内存之后,一样会减少磁盘IO,提升性能。
3、对于task的执行,会创建很多的对象,如果内存过小的话,JVM堆内存满了之后,会频繁的进行GC操作,垃圾回收等。速度会非常慢,加大内存之后就避免了这些问题。
调节并行度:
并行度是指spark作业中,各个stage的task的数量。代表了spark作业的各个阶段的并行度。
若是不调节的话会浪费你的资源:
比如现在spark-submit脚本里面,给我们的spark作业分配了足够多的资源,比如50个executor,每个executor有10G内存,每个executor有3个cpu core。
基本已经达到了集群或者yarn队列的资源上限。task没有设置,或者设置的很少,比如就设置了100个task,你的Application任何一个stage运行的时候,都有总数在150个cpu core,可以并行运行。但是你现在,只有100个task,平均分配一下,每个executor分配到2个task,ok,那么同时在运行的task,只有100个,每个executor只会并行运行2个task。每个executor剩下的一个cpu core, 就浪费掉了。
你的资源虽然分配足够了,但是问题是,并行度没有与资源相匹配,导致你分配下去的资源都浪费掉了。
合理的并行度的设置,应该是要设置的足够大,大到可以完全合理的利用你的集群资源。比如上面的例子,总共集群有150个cpu core,可以并行运行150个task。那么就应该将你的Application的并行度,至少设置成150,才能完全有效的利用你的集群资源,让150个task,并行执行。而且task增加到150个以后,即可以同时并行运行,还可以让每个task要处理的数据量变少。比如总共150G的数据要处理,如果是100个task,每个task计算1.5G的数据,现在增加到150个task,可以并行运行,而且每个task主要处理1G的数据就可以。
很简单的道理,只要合理设置并行度,就可以完全充分利用你的集群计算资源,并且减少每个task要处理的数据量,最终,就是提升你的整个Spark作业的性能和运行速度。
如何调配:
1、task的数量,至少设置成spark application的总cpu core数量相同。
2、官方推荐,task的数量设置成spark application总cpu core 的2~3倍。
3、具体为设置spark.default.parallelism
SparkConf conf = new SparkConf().set("spark.default.parallelism", "500")
二、RDD持久化
在spark作业中若是同一个RDD在后面重复使用,需要进行持久化操作。因为
在默认情况下,多次对一个RDD执行算子,去获取不同的RDD,都会对这个RDD以及之前的父RDD全部重新计算一遍。所以是十分浪费资源的,所以这种情况是绝对要避免的。
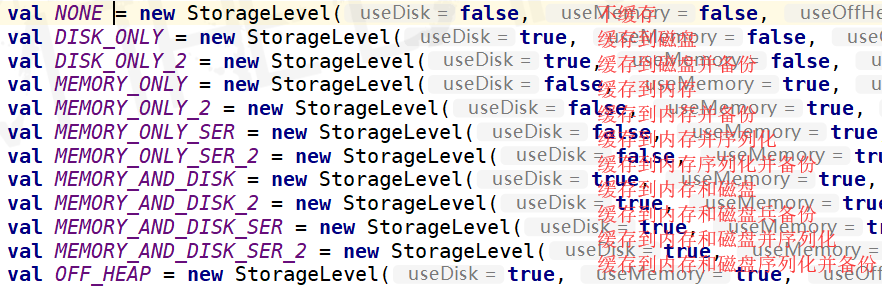
缓存级别如上。
三、广播变量
把每个task都要用到的常量,通过广播变量,发送到每个节点上面,这样的话,每个节点都会存在一个通用的常量,若是不广播的话,会造成每个task上面都会存在这个常量,造成资源的浪费。
四、Kryo序列化

通过以上配置,来配置spark作业的序列化方式。


五、调节本地化等待时间

Spark调优--JVM优化