转发请注明原创地址:https://www.cnblogs.com/dongxiao-yang/p/10602799.html
某日晚高峰忽然集群某个大流量业务收到lag报警,查看客户端日志发现reblance一直无法成功,日志如下
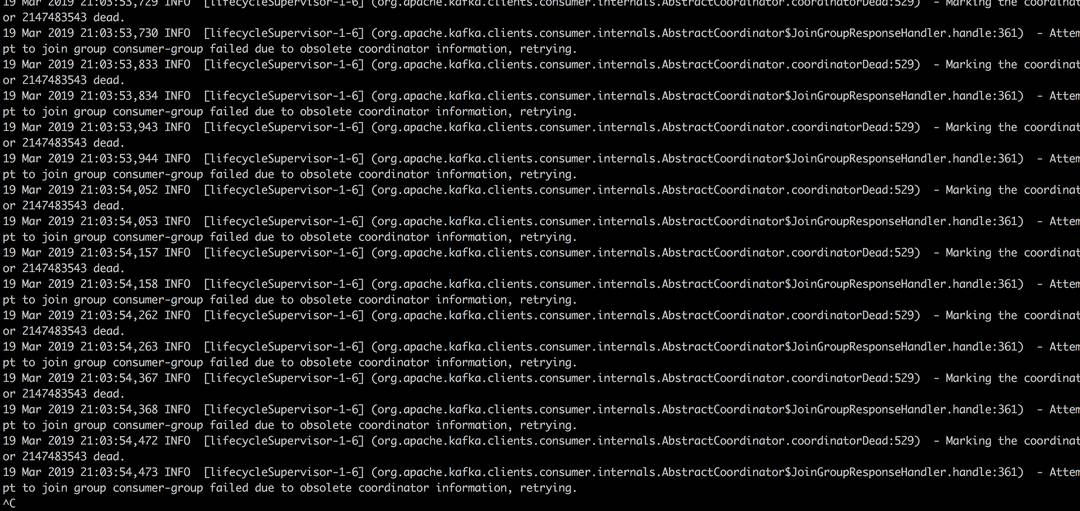
根据客户端日志显示consumer在尝试joingroup的过程中收到了服务端COORDINATOR状态不正常的信息,怀疑是服务端负责这个consumer-group的broker在coordinator元信息管理上出现了问题。
于是跑到对应的节点上看一下server日志,发现在一台刚才有过重启的服务节点上产生如下日志
Failed to append 363 tombstones to __consumer_offsets-38 for expired/deleted offsets and/or metadata for group consumer-group. (kafka.coordinator.GroupMetadataManager)
org.apache.kafka.common.errors.NotLeaderForPartitionException: Leader not local for partition __consumer_offsets-38 on broker 。
怀疑是这个服务重启的过程中__consumer_offset分区有部分数据或者文件有异常导致coordinator无法提供服务导致,停掉有问题节点后发现客户端reblance很快就成功了,于是怀疑问题节点产生了坏文件,后续删除对应分区可以重启成功服务,但是对应group的业务又开始报错
20 Mar 2019 15:31:32,000 INFO [PollableSourceRunner-KafkaSource-bl_app_event_detail_source] (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle:542) - Offset commit for group consumer-group failed due to NOT_COORDINATOR_FOR_GROUP, will find new coordinator and retry
20 Mar 2019 15:31:32,001 INFO [PollableSourceRunner-KafkaSource-bl_app_event_detail_source] (org.apache.kafka.clients.consumer.internals.AbstractCoordinator.coordinatorDead:529) - Marking the coordinator 2147483543 dead.
kafka 自从0.9以来摒弃了consumer把offset存在zk的做法而是都存到了__consumer_offsets这个系统topic里面,同时consumer端的reblance都是依靠server端的coordinator负责调度协调。至于每个group怎么选择对应broker节点是根据下面这个简单的hashcode对__consumer_offsets分区数取模的算法得出来的,
def partitionFor(groupId: String): Int = Utils.abs(groupId.hashCode) % groupMetadataTopicPartitionCount
所以看上去是重启节点拉起来后客户端发现对应的offset分区leader又活了,但是活过来的leader却告知客户端NOT_COORDINATOR_FOR_GROUP这个矛盾。但是明明有问题的offset文件已经被手动删除掉了,重新拉副本也成功了,为什么还是会有join group不成功的现象呢。
继续查看问题节点,发现问题节点在Loading group metadata for之类的日志的时候一直没有输出对应的问题group相关日志,初步判断broker重启过程中load group信息的时效出了问题。
def onLeadershipChange(updatedLeaders: Iterable[Partition], updatedFollowers: Iterable[Partition]) { // for each new leader or follower, call coordinator to handle consumer group migration. // this callback is invoked under the replica state change lock to ensure proper order of // leadership changes updatedLeaders.foreach { partition => if (partition.topic == GROUP_METADATA_TOPIC_NAME) groupCoordinator.handleGroupImmigration(partition.partitionId) else if (partition.topic == TRANSACTION_STATE_TOPIC_NAME) txnCoordinator.handleTxnImmigration(partition.partitionId, partition.getLeaderEpoch) }
如上述代码所示,kafka在offset分区重新被选举为leader的时候才会去加载对应的group信息,而且所有新leader是foreach单线程循环,如果其中有一个慢的剩下的group都会受到影响。查看问题节点果然除了被删掉的offset分区还有一个分区offset历史文件很多,多到500G的体量,这和offset这种只保存最新数据的场景明显是不符合的,这个大小会导致服务端加载offset信息长到无法接受的程度。
为了尽快回复offset元信息,把问题节点的offset partition全都重新分配到其他节点,在重分配的过程中发现新的副本会不断的删除同步过来的过期数据最后结束后整个分区的大小只有几十M,于是坚定了原来分区大小不正常的判断 。对于__consumer_offsets这种compact策略的topic,kafka内部是有一个专门的logcleaner线程负责日志的合并,但是刚开始出问题的节点经过了几次重启,原始的现场早已不存在,于是把整个集群每个服务挨个查了一遍,果然在另一台看似正常的机器上同样发现了一个很大的offset分区,jstack了一下,发现kafka-log-cleaner-thread这个线程已经没了!重启该服务后发现问题分区的日志也开始正常删除。可惜的是由于服务日志只保留了最近7天的,kafka-log-cleaner-thread的错误日志已经找不到了,这个有待后续复现确认。
回顾了一下处理问题过程中出现的其他现象,其实都是有提示的,像是关掉问题节点的时候server日志会报
WARN Map failed (kafka.utils.CoreUtils$)
java.io.IOException: Map failed
at sun.nio.ch.FileChannelImpl.map(FileChannelImpl.java:940)
at kafka.log.AbstractIndex$$anonfun$resize$1.apply(AbstractIndex.scala:111)
at kafka.log.AbstractIndex$$anonfun$resize$1.apply(AbstractIndex.scala:101)
以及kafka jvm第一次崩掉的hs_err_pid日志会提示内存不足
Native memory allocation (mmap) failed to map 65536 bytes for committing reserved memory
由于kafka使用的mmap方式映射了数据文件以及索引,这个mmap failed就已经提示了文件过多。
结论:kafka的offset数据每个group会根据hash取模的方式发到一个固定的_consumer_offsets分区中,_consumer_offsets分区的leader负责对应groupid的coordinator服务,_consumer_offsets
的删除是由kafka-log-cleaner-thread执行的,这个线程个数默认是1,如果线程崩掉了offset历史分区文件会一直无法删除,导致jvm崩掉并且服务恢复的时候group元信息长时间的无法加载导致reblacne报错。