最近需要处理过亿的数据,笔者在朋友的推荐下学习了ElasticSearch,看了网上很多博客也遇到了很多问题,所以笔者记录一下学习和使用ElasticSearch的过程。
ElasticSearch的概念网上很多,笔者就不在此多啰嗦了,直接进入实战。
一、环境配置(仅window用户)
1. ElasticSearch是基于Lucene构建的一个分布式搜索引擎,运行需要java环境,所以要先配置java环境,安装JDK,这里笔者使用的版本是 jdk1.8.0_144
2.我是window用户,初学ElasticSearch,很多配置以及安装各种插件还需要手动编译jar,比较复杂容易出错,
所以就直接使用elasticsearch的rtf版本(https://github.com/medcl/elasticsearch-rtf)
笔者在github上下载的rtf版本的es版本为Elasticsearch 5.1.1(网上很多文章因为版本不一样,所以一些配置和命令可能有误,这种坑笔者已经遇到很多次了)
2.1 启动

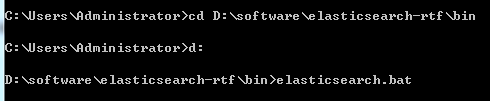
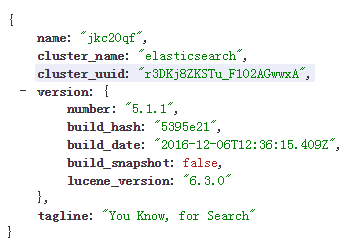
这个是笔者下载的ElasticSearch目录结构,在控制台执行elasticsearch.bat(如下图)
2.2 安装ElasticSearch Head插件
笔者在这里直接使用第二种简单的方式,安装成功了 浏览器上多来一个小图标 
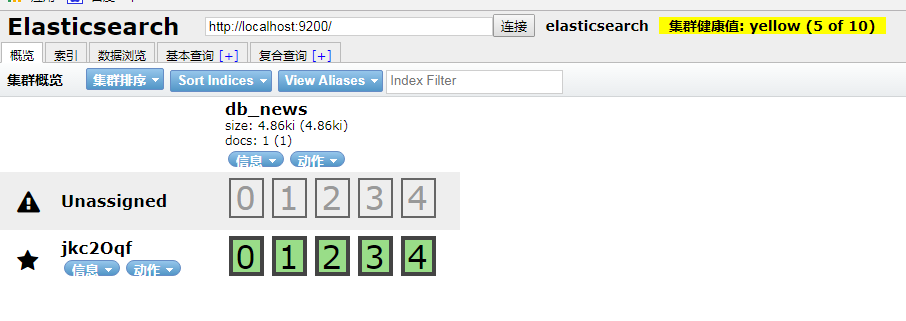
点击出现下图效果,ElasticSearch Head就能使用了
二、ElasticSearch CRUD
为了方便执行crud的操作,直接在浏览器上安装SENSE插件(如下图界面)
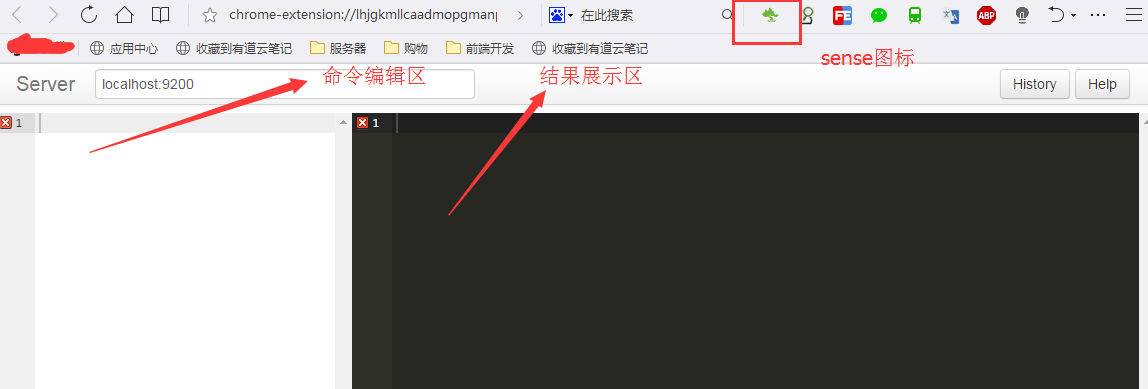
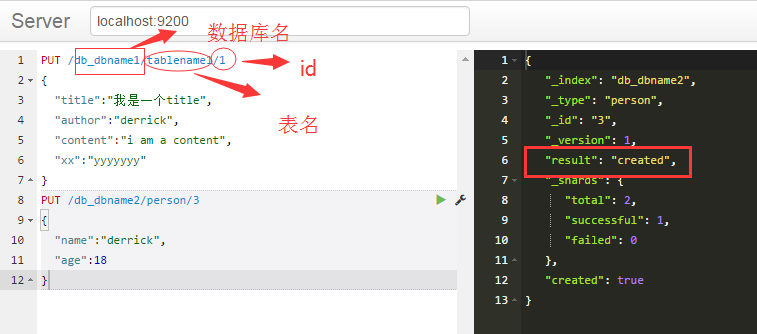
增加
PUT /db_dbname1/tablename1/1
{
"title":"我是一个title",
"author":"derrick",
"content":"i am a content",
"xx":"yyyyyyy"
}
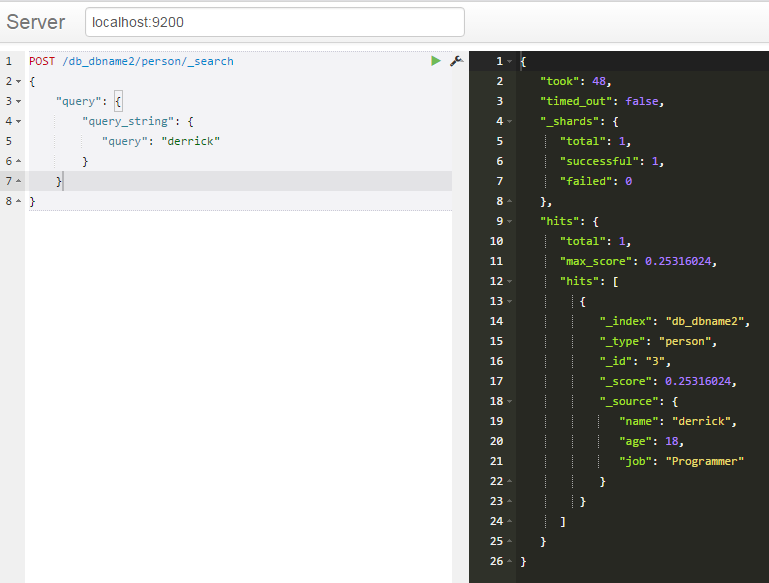
PUT /db_dbname2/person/3
{
"name":"derrick",
"age":18
}
 修改(
删除
修改(
删除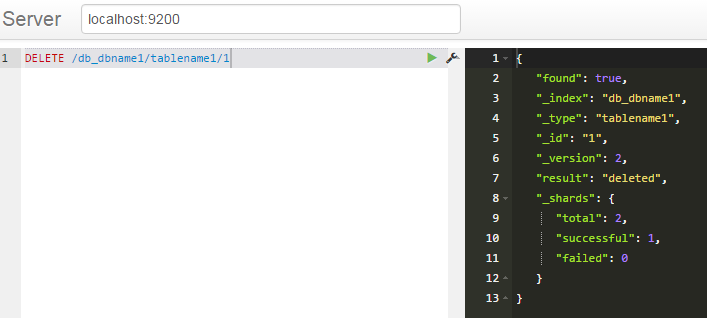 查询
查询
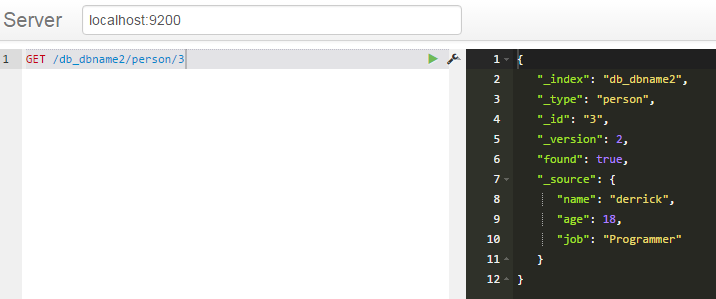
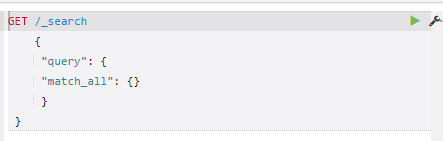
修改就是将id置为和存在的记录一致)
、、
根据id查询单条记录
查询所有库,所有表的文档
在指定库指定表中查找某个字段等于某个值的文档
三、中文分词
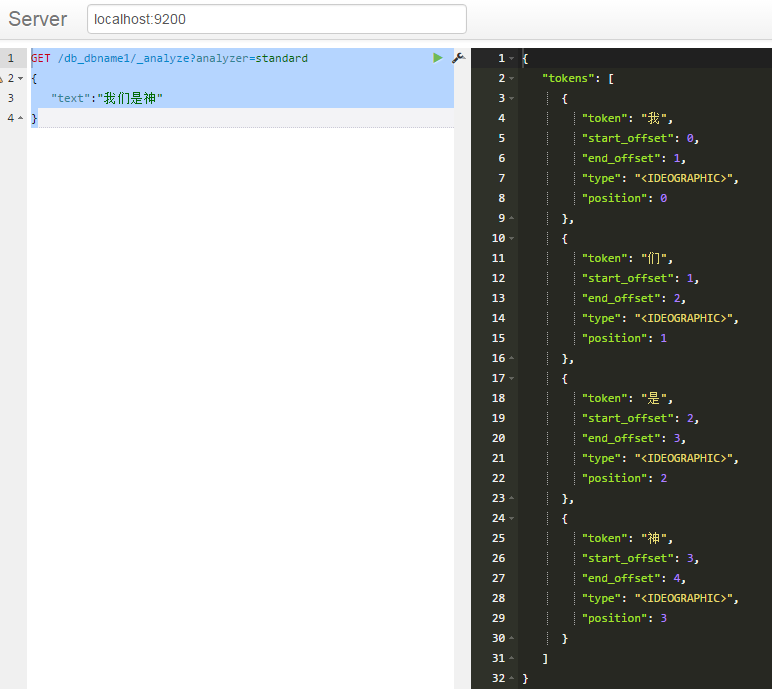
中文分词插件采用ik的,默认的是把每个汉字都拆成一个词,效果不好
代码如下:
默认标准分词
 、
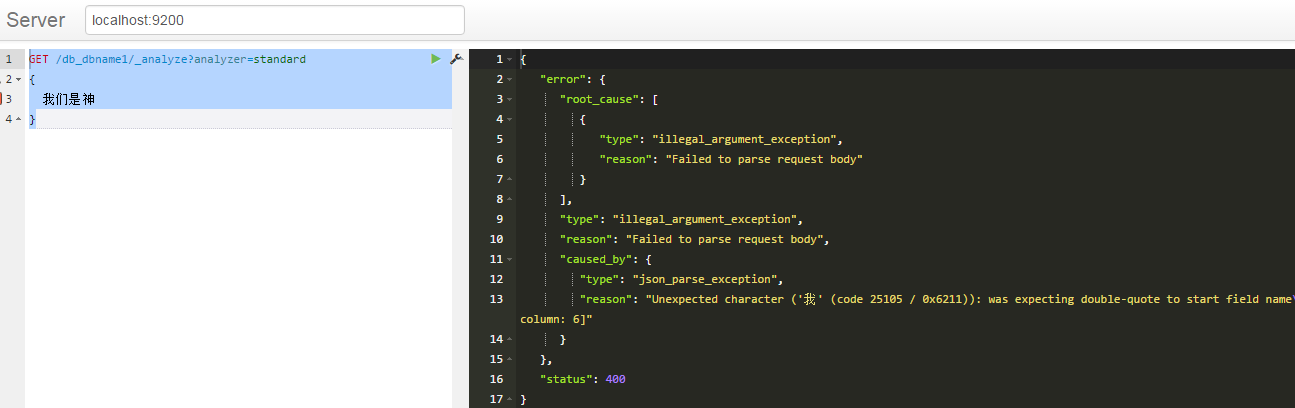
、注:有些人的文章里 直接是
GET /db_dbname1/_analyze?analyzer=standard
{
我们是神
}
在我用的这个版本里面,这样写是错误的
IK简单分词
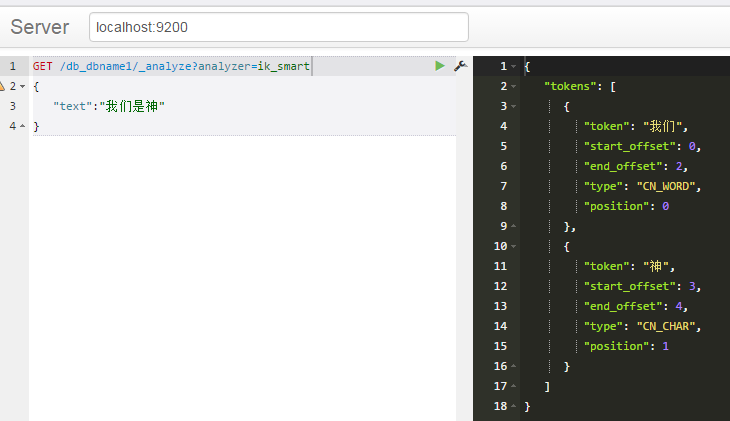
另外还有一个
GET /db_dbname1/_analyze?analyzer=ik_max_word
{
"text":"车身电气系统"
}
显然默认标准分词不是我们想要的分词,所以这里可以设置全局分词
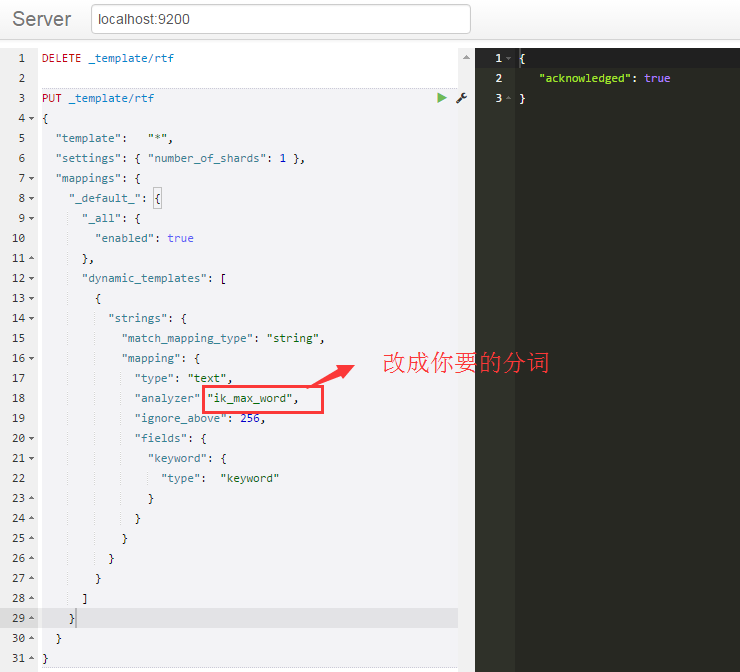
时间不早,今天先写到这