分页抓取博客园新闻,先从列表里分析下一页按钮
相关代码:


# -*- coding: utf-8 -*- import scrapy from cnblogs.items import ArticleItem class BlogsSpider(scrapy.Spider): name = 'blogs' allowed_domains = ['news.cnblogs.com'] start_urls = ['https://news.cnblogs.com/'] def parse(self, response): articleList=response.css('.content') for item in articleList: # 由于详情页里浏览次数是js动态加载的,无法获取,这里需要传递过去 viewcount = item.css('.view::text').extract_first()[:-3].strip() detailurl = item.css('.news_entry a::attr(href)').extract_first() detailurl = response.urljoin(detailurl) yield scrapy.Request(url=detailurl, callback=self.parse_detail, meta={"viewcount": viewcount}) #获取下一页标签 text=response.css('#sideleft > div.pager > a:last-child::text').extract_first().strip() if text=='Next >': next = response.css('#sideleft > div.pager > a:last-child::attr(href)').extract_first() url=response.urljoin(next) yield scrapy.Request(url=url,callback=self.parse) ##解析详情页内容 def parse_detail(self, response): article=ArticleItem() article['linkurl']=response.url article['title']=response.css('#news_title a::text').extract_first() article['img'] = response.css('#news_content img::attr(src)').extract_first("default.png") article['source'] = response.css('.news_poster ::text').extract_first().strip() article['releasetime'] = response.css('.time::text').extract_first()[3:].strip() article['viewcount']= response.meta["viewcount"] article['content']=response.css('#news_body').extract_first("") yield article
写入数据库,先在setting.py页面配置mongo连接数据信息
ROBOTSTXT_OBEY = True MONGODB_HOST='localhost' MONGO_PORT=27017 MONGO_DBNAME='cnblogs' MONGO_DOCNAME='article'
修改pipelines.py页面,相关代码
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymongo from scrapy.conf import settings from cnblogs.items import ArticleItem class CnblogsPipeline(object): #初始化信息 def __init__(self): host = settings['MONGODB_HOST'] port = settings['MONGO_PORT'] db_name = settings['MONGO_DBNAME'] client = pymongo.MongoClient(host=host, port=port) db = client[db_name] self.post=db[settings['MONGO_DOCNAME']] ##获取值进行入库 def process_item(self, item, spider): article=dict(item) self.post.insert(article) return item
__init__函数里,获取配置文件里的mongo连接信息,连接mongo库
process_item函数里获取blogs.py里parse里yield返回的每一行,然后将数据入库
最后需要在setting取消注释pipelines.py页面运行的注释,不修改(pipelines.py页面代码可能无法正常调用)
ITEM_PIPELINES = { 'cnblogs.pipelines.CnblogsPipeline': 300, }
最后在Terminal终端运行命令:scrapy crawl blogs
启用后便会开始进行抓取,结束后打开mongo客户端工具:库和表名创建的都是setting.py里配置的

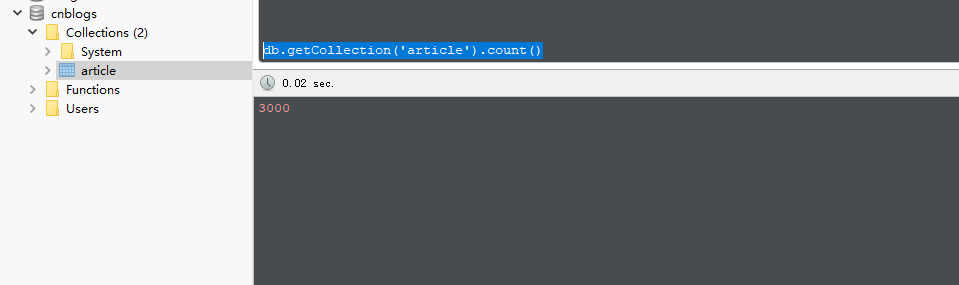
到此,3000条文章资讯数据一条不差的下载下来了