1. 基本(基础)查询
1.1. 基本查询语法
基本查询是指最基本的select语句。
【语法】

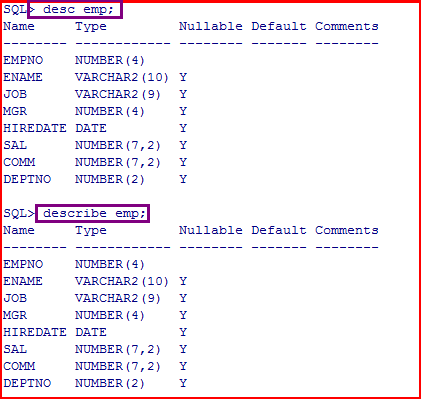
【知识点】如何使用工具进行查询
在plsql developer中打开查询窗口(执行sql语句):
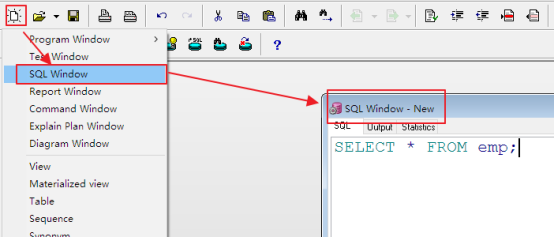
执行语句的操作:
选中要执行的语句,点击执行按钮或者按快捷键F8,下方会显示查询的结果。

显示下一页记录和显示剩余的所有页的记录:

注:如果想学习工具的详情使用,可参阅文档《plsql developer中文手册.pdf》
1.2. 选择列
【语法】
选择全部列:

选择特定列:

【知识点】
两种语法效率是不同的,哪种效率高?
结论和原因:如果select * 会全字段扫描,效率低,因此,尽量用指定的字段。
1.3. 别名
别名涉及到列的别名和表的别名。需要注意引号和用法。
【示例】
--别名 --列的别名 SELECT ename AS 姓名, job AS 工作 FROM emp; --省略了双引号 SELECT ename AS "姓 名", job AS "工作" FROM emp;--最标准的写法,在别名有空格的时候不能省略双引号 SELECT ename "姓 名", job "工作" FROM emp; --省略了as SELECT ename 姓名, job 工作 FROM emp;--省略as和双引号 --表的别名 SELECT * FROM emp t; --给表起别名不能加as;
SELECT ename,job FROM emp t ;--单表查询时给表起了别名也可以不使用,也可以使用t.ename,但不可以使用emp.ename
SELECT t.ename,t.job FROM emp t ;-- 表的别名引用字段 SELECT empQWERTYUIO.ename,empQWERTYUIO.job FROM empQWERTYUIO ;--使用表名去引用字段相对麻烦 SELECT emp.ename,emp.job FROM emp t ;(错误语句)--一旦给表起了别名, 那么就只能使用别名去引用字段,原本的表名不可用
【知识点】
1.引号的问题。别名最好使用双引号,也可以省略,而且还可以省略as。
2.表的别名一旦指定,列的引用中必须使用表的别名而不能使用表名。
1.4. 书写SQL的注意事项

注意:sql语句对大小写不敏感,但数据内容区分大小写;表名和表字段都不区分大小写
【示例】
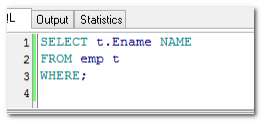
使用工具来格式化语句:
选中要格式化的语句,点击工具栏上的“美化”按钮,工具会自动将语句格式化:
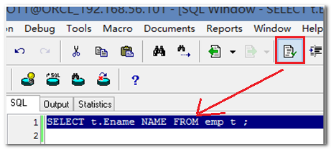
格式化美化功能非常适合比较长的、复杂的语句的格式化。
1.5. 字符串连接符||

【示例】
--需求1:查询出员工的名字,要求显示的员工名字前面加上“姓名:”的字符串,显示结果参考:姓名:scott SELECT '姓名:'|| ename 姓名 FROM emp; --需求2:将和员工的编号和员工的姓名都放在一个结果字段中显示。合成列 SELECT empno||' '||ename FROM emp;
提示:单引号代表的是字符串。
【知识点】
引号的问题。Oracle中如何选择单引号和双引号呢?基本上,只要是别名或不需要Oracle解析(运算)的字符串,用双引号,剩下的都用单引号(比如字符串)
1.6. 伪表-dual
mysql查询当前系统时间:SELECT SYSDATE();
但在Oracle中会报错:
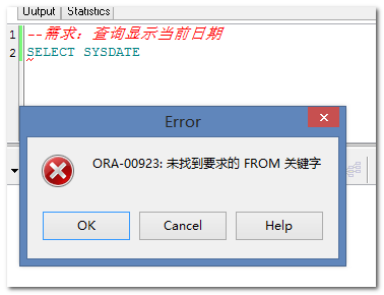
提示:sysdate代表系统时间函数。
报错原因:
Oracle和mysql的一个区别:
Oralce的查询语句必须是完整的,即必须满足语法select from
【示例】
需求:查询显示当前的日期: SELECT SYSDATE FROM dual;--sysdate代表当前日期的一个系统函数,dual是伪表,主要用来占位的,补充sql的。 SELECT 'a'||'b' FROM dual; SELECT 1+2 FROM dual;
DUAL 是一个‘伪表’(也称之为万能表),可以用来测试函数和表达式。也有人称之为万能表。使用的时候可以用来占个语法的位置,来补充完整的sql。
伪表也是一张表,只是做了一些特殊处理。我们来看看:
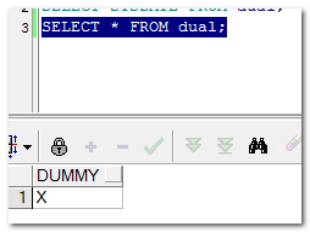
注意:大家不要手动来维护这张表,这个表是由Oracle自动维护的。
1.7. 空值运算问题

【示例】
--需求:查询所有员工的月薪(月薪=基本工资+奖金) SELECT ename, sal+comm 月薪 FROM emp;--原因:与null运算的结果都是null
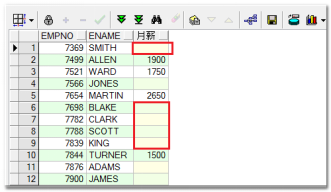
问题:
每个人都要基本薪资,但有的没有奖金(null),相加则没有月薪(null)
原因:和null进行运算的都是null。
如何解决呢?我们会在单行函数中这一章节中进行解决。
1.8. SQL语句和SQL*Plus命令
目标:了解什么是命令,什么是语句。
两者对比如下:

命令的关键字可以缩写,比如显示表结构的命令:

【关于工具窗口使用选择】
工具的命令行窗口下,既能执行命令,也能执行sql;但在sql窗口下只能运行sql,如果在sql窗口运行命令,会出现错误信息
【演示】
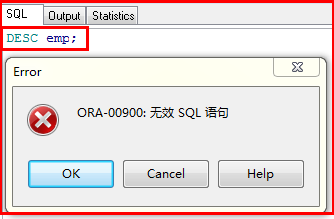
在可视化工具的sql窗口只能执行SQL语句,但不能执行命令,会报错
在可视化工具的命令窗口分别通过 完整命令、简写命令、SQL语句 显示emp表的结构:都成功
工具中的命令窗口的调用方法:

友情提示:
工具的命令窗口和sqlplus自带的命令窗口在有时候还是有少许区别的。后面会提到。
1.9. 导出报表-扩展-了解
报表是向上级报告情况的表格。简单的说:报表就是用表格、图表等格式来动态显示数据,可以用公式表示为:“报表 = 多样的格式 + 动态的数据”。
计算机提供的报表可以由数据库直接生成,也可以由专业的报表软件生成。
l 数据库软件:它们可以拥有动态变化的数据,但是这类软件一般只会提供,最简单的表格形式来显示数据。它们没有实现报表软件的"格式多样化"的特性。
l 报表软件:它们需要有专门的报表结构来动态的加载数据,同时也能够实现报表格式的多样化。(eclipse官方提供birt)
使用sqlplus导出报表,不太方便。

在没有专业的报表系统或报表工具的情况下,推荐直接使用SQLplus Developer工具进行简单报表的导出,导出步骤参考如下:
1. 执行期望的sql语句。
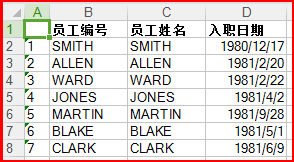
SELECT t.ename 员工编号, t.ename 员工姓名, t.hiredate 入职日期 FROM emp t;
2. 选中需要导出的报表数据(如果不选中就是导出所有的),在左侧的工具栏上点击右键,选择copy to excel...copy as xls
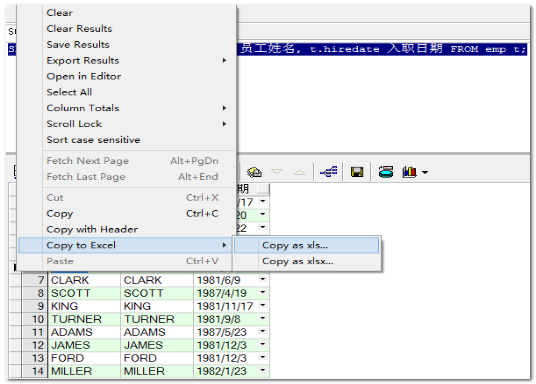
自动生成到execl表格:
提醒:
复杂的查询以及查询技巧主要是报表查询的时候要用的到!
2. 过滤子句where
2.1. 过滤语法
过滤就是使用where子句,将不满足条件的行过滤掉。

注意:
1.Where子句紧跟from子句。
2.where的过滤条件是对于每一行数据的。
2.2. 字符和日期


这里强调两个事情:
字符大小写的问题和默认日期格式的问题。
【示例】
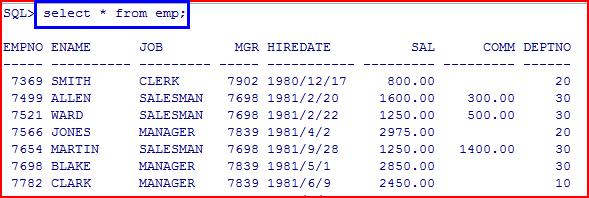
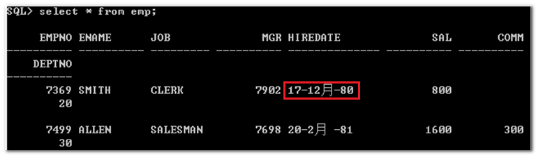
--需求1:查询关于KING这个人的记录。 SELECT * FROM emp WHERE ename='king';--错误 SELECT * FROM emp WHERE ename='KING';--正确,具体数据库的值是区分大小写。 --需求2:查询入职日期是1987/4/19的员工的信息 SELECT * FROM emp WHERE hiredate ='1987/4/19';--与数据库默认的日期格式不对应,导致无法将字符串隐式转换为日期 SELECT * FROM emp WHERE hiredate ='17-12月-80';--数据库默认的日期格式,字符串可以隐式转换为日期 --数据内容显示的1987/4/19格式是工具给你转的
【疑问】为什么可视化工具显示的不是默认值(和sqlplus显示的不一样)?
数据库真实存储日期的格式:
可视化工具显示的日期格式:

原因是工具自己将真实的数据库格式转成显示的日期格式!
注意:只是在显示上是这种格式,实际数据库存储的还是真实的格式
工具显示的日期格式配置如下:

【工具使用提示】
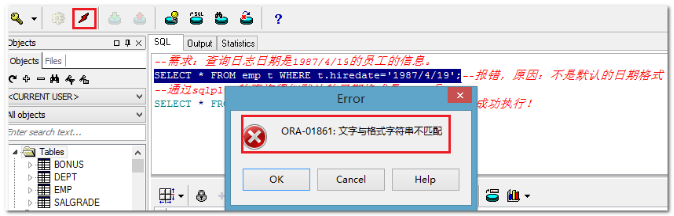
1.注意工具的错误提示方式:
2.异常会导致语句执行过程被卡住。见工具栏上的闪电图标。此时可以选择终止运行或排除异常后语句继续执行。
1.3. Escape-转义字符
准备测试数据。
添加一条ename的值为xiao_ming的测试数据,可以使用insert语句:
INSERT INTO emp(empno,ename) VALUES(1001,'xiao_ming'); commit;
注意:oracle默认手动提交,增删改之后需要手动提交事务,而查询则不需要
【回顾】通配符:

【示例】
--需求1:查询名称是带有”x”字符的员工的记录信息。 SELECT * FROM emp WHERE ename LIKE '%x%'; --需求2:查询员工名称中含有下划线(“_”)的员工. SELECT * FROM emp WHERE ename LIKE '%_%'; --为什么全查出来:sql的通配符%(任意多个字符) _(任意一个) SELECT * FROM emp WHERE ename LIKE '%\_%' ESCAPE ''; --用ESCAPE来声明一个转义字符,语句中,该转义字符之后的字符,都作为普通字符来处理。 SELECT * FROM emp WHERE ename LIKE '%|_%' ESCAPE '|'; --除了“/”,别的符号也可以,但建议使用“/” --需求3:查询姓名是4个字符的员工的信息。 SELECT * FROM emp WHERE ename LIKE '____'; /* 作用:假如你允许用户注册的时候带下划线,或者表单有个字段是备注,那么用户,在写备注的时候,可能会写下划线。 注册zhong_shi,此时,你想知道数据库中有多少人的用户名是带下划线的。 */ SELECT COUNT(*) FROM emp WHERE ename LIKE '%/_%' ESCAPE '/';
【工具的使用提示】:
对于某个关键字不确定单词的编写的时候,可以使用工具的自动提示功能。
当输入前几个字符,则工具会自动提示相关关键字的列表。如果不小心关闭了提示或者未出现提示,则可以通过在单词上按F6。
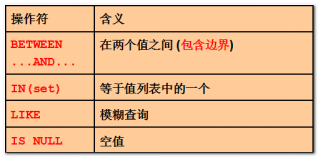
2.4. 条件运算符
常见的条件运算符如下:


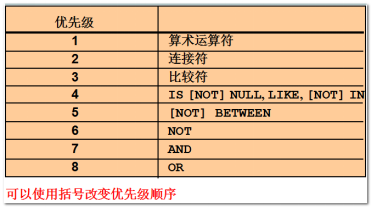
运算符的优先级:(括号最无敌 )
2.5. in和not in过滤时的空值问题
【示例】要求使用in和not in
--需求1:查询10号部门和20号部门的员工; SELECT * FROM emp WHERE deptno IN(10,20); --需求2:查询10号和20号以及没有部门的员工部门的员工; SELECT * FROM emp WHERE deptno IN(10,20,NULL); --失败 --分析:首先要明白in的原理是什么? --deptno = 10 OR deptno = 20 OR deptno IS NULL --或的关系 只要有一个结果的true 返回的就是true --解决方法: SELECT * FROM emp WHERE deptno IN(10,20) OR deptno IS null; --需求3:查询不是10号和20号以及没有部门的员工部门的员工; SELECT * FROM emp WHERE deptno NOT IN(10,20,NULL);--失败 -- deptno!=10 AND deptno!= 20 AND deptno IS NOT NULL -- 与的关系 ,只要有一个不满足 返回就是false SELECT * FROM emp WHERE deptno NOT IN(10,20) AND deptno IS NOT null;
2.6. 条件运算的优先级
思考:下面这条语句的两个条件的执行顺序是什么?(注:condition1和condition2是两个条件表达式)

答案:先执行2,再执行1。
原因是:where条件的解析顺序:从右到左
【知识点】
SQL优化:(where条件特别多的情况下,就有效果了)
对于and,应该尽量把假的放到右边。
对于or,应该尽量把真的放到右边。
3. 排序子句Order by
3.1. 排序语法

两个注意点:

3.2. 关键字作用范围
【示例】
--需求:查询所有员工信息,要求按照部门和员工号的倒序排序 SELECT * FROM emp ORDER BY deptno DESC ,empno DESC; --默认排序是升序,如果需要倒序排序的话,需要指定desc关键字
注意:如果多个字段都要排序,那么每个字段后面都要跟着排序方式,当然如果升序可以省略,但降序一定不可以;
3.3. 别名列号排序-了解
【示例】
--需求:查询所有员工信息,要求显示姓名和基本年薪(基本薪资*12),并且要求根据基本年薪正序排列。 --语句要求:分别使用别名、不使用别名、使用列号来排序 SELECT ename,sal*12 FROM emp ORDER BY sal *12 ASC; --asc可以省略 SELECT ename 姓名,sal*12 年薪 FROM emp ORDER BY 年薪 ASC; --根据别名排序 SELECT ename 姓名,sal*12 年薪 FROM emp ORDER BY 2 ASC; --根据列号:第二列
3.4. 空值排序显示的问题
【知识点】关键字nulls last的使用。
【示例】
--需求:根据基本薪资的年薪倒序序排列 SELECT ename,sal*12 FROM emp ORDER BY sal *12 DESC NULLS LAST; --排序列的空值放在最后
注意:效果是将sal为空的记录排在最后一行;
4. 单行函数
4.1. 函数的分类
Oracle的内置函数分为单行函数和多行函数(多行函数还称之为组函数、聚集函数等)。

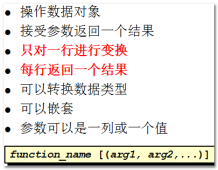
4.2. 单行函数的概念
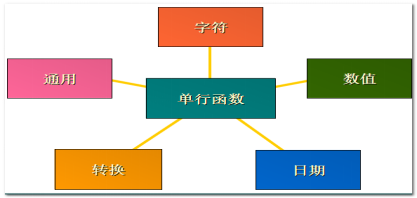
4.3. 单行函数的分类
4.4. 字符函数
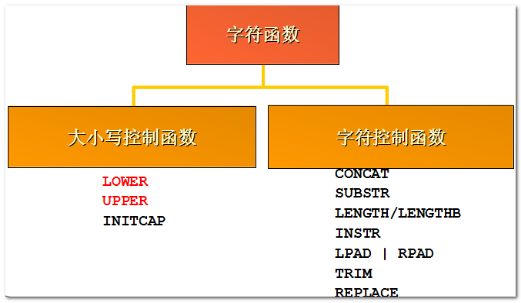
大小写控制函数
【示例】
--需求1:查询出KING的这个员工的信息。 SELECT * FROM emp WHERE ename ='king'; --没有查到数据 SELECT * FROM emp WHERE LOWER(ename) ='king'; --会将数据库的值转换成小写 SELECT * FROM emp WHERE ename =UPPER('KinG'); --不管用户输入的是大写还是小写,还是大小混合写 SELECT UPPER('KiNg') FROM dual; SELECT empno,INITCAP(ename) FROM emp --首字母大写
【讨论】:
上述的需求,到底是使用upper还是使用lower呢?一般根据需求来选择的。
如果将函数放到字段上,会每行的该字段都会转换,效率低一些。--sql优化
因此,一般情况下,建议将转换函数放到固定值上面(好处之一就是只需要转换一次,还有一个好处,就是你不知道用户到底输入的是大写还是小写还是混合写,更适应业务)。

字符控制函数:

【示例】
--需求1:替换字符串'abcd'中的’bc’为’ITCAST’,最终显示为’aITCASTd’ SELECT REPLACE ('abcd','bc','ITCAST') FROM dual; --需求2:去掉' Hello World '前后的空格 SELECT TRIM(' Hello World ') FROM dual; --需求3:去掉'Hello WorldH'前后的H字符(提示:使用from关键字) SELECT TRIM('H' FROM 'Hello WorldH') FROM dual;
【提示】:
Oracle的函数非常多,建议大家只记住这些常用的几个就基本够用了,其他的可以查阅手册:
4.5. 数字函数

【示例】
--需求:钱数:1385.56,分别根据不同场景进行处理显示不同结果: 买东西(抹零头:1385,1380)、发工资(发钱了:1386) SELECT TRUNC(1385.56) 买东西抹零头,TRUNC(1385.56,-1) 抹零头, ROUND(1385.56) 发钱, ROUND(1385.56,1) 发钱 FROM dual;

注意:如果没有第二个参数,默认为0;
【提示】:
Round和trunc函数,除了对数字起作用外,对于日期也是起作用的。(后面会提到)
4.6. 日期函数
【示例】
--问题:日期可以相减么?日期可以相加么? SELECT SYSDATE-SYSDATE FROM dual; --日期相减一般是为了计算两个日期之间间隔 SELECT SYSDATE+SYSDATE FROM dual; --日期相加没意义
常用函数(了解,用时查询)
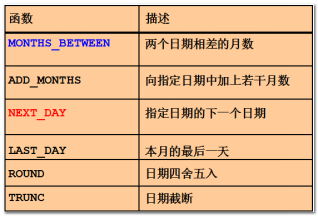
next_day(基础日期,星期几)
星期几,是从周日开始,分别数字为1,2,3。。。
【示例】
--需求1:计算员工的工龄(工龄:当前的日期和入职的日期的差),要求分别显示员工入职的天数、多少月、多少年。 SELECT ename, SYSDATE-hiredate 工龄天, (SYSDATE-hiredate)/30 工龄月不精确, months_between(SYSDATE,hiredate) 工龄月精确, TRUNC (months_between(SYSDATE,hiredate)/12) 工龄年精确 FROM emp; --需求2:查看当月最后一天的日期。 SELECT last_day(SYSDATE) FROM dual; --需求3:查看指定日期的下一个星期天或星期一的日期。(next_day(基础日期,星期几))-- 星期日是1,星期一2 SELECT next_day(SYSDATE,1) FROM dual; SELECT next_day(SYSDATE,2) FROM dual;
【扩展知识】
扩展:时间戳systimestamp关键字。
【示例】
查看当前系统默认精度的日期时间和更高精度的时间戳,要求显示结果如下:
SELECT SYSDATE,Systimestamp FROM dual;

4.7. 转换函数
数据类型转换分类:

隐式转换
【示例】
--需求:查询10号部门的信息,分别使用数字和字符串作为条件的值。 SELECT * FROM emp WHERE deptno=10; SELECT * FROM emp WHERE deptno='10';--字符串隐式转换为数字了 SELECT * FROM emp WHERE deptno='10q';--隐式转换的前提,是能转换才可以。
【工具的使用补充】在查询数据的时候,通过工具来快捷查看字段的数据类型:
隐式转换的条件:
Oracle可以自动的完成下列类型(三种)的转换:
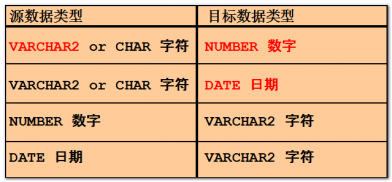
非法转换:
隐式转换的前提是:被转换的对象是可以转换的。下面的语句会报错:

显示转换(三个函数)
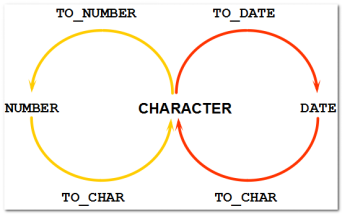
三个转换函数的语法:
将日期或数字转换成字符

将字符转换成日期

将字符转换成数字

【提示:记忆方式】:第一个参数都是要转换的目标(到底用哪个函数,跟目标有关系),第二个都是转换的格式。
【示例】
--需求1:显示今天的完整日期,结果参考:“2015-07-06 11:07:25”。 SELECT to_char(SYSDATE,'yyyy-MM-dd HH:mm:ss') FROM dual;--java的日期格式,和sql的不一样 SELECT to_char(SYSDATE,'yyyy-mm-dd hh24:mi:ss') FROM dual;--sql--24小时制 SELECT to_char(SYSDATE,'yyyy-mm-dd hh:mi:ss') FROM dual;--sql--12小时制 SELECT to_char(SYSDATE,'yyYy-Mm-Dd hH24:mi:ss') FROM dual;--格式不区分大小写 --需求2:显示今天是几号,不包含年月和时间,结果参考:“8日”。 SELECT to_char(SYSDATE,'dd')||'日' FROM dual;--字符串拼接方式 SELECT to_char(SYSDATE,'dd"日"') FROM dual;--格式中直接加入固定值 --需求3:显示当月最后一天是几号,结果参考:”30“。 SELECT to_char(last_day(SYSDATE),'dd') FROM dual; --需求4:xiaoming的入职日期是2015-03-15,由于其入职日期当时忘记录入,现在请将其插入到emp表中。 UPDATE emp SET hiredate =to_date('2015-03-15','yyyy-mm-dd') WHERE ename ='xiao_ming'; COMMIT; --需求5:查看2015年2月份最后一天是几号,结果参考“28“ SELECT last_day(to_date('201502','yyyymm')) FROM dual; SELECT to_date('201502','yyyymm') FROM dual;--日期的默认值,不指定日期,默认1号 2016-07-20: --需求1:显示今天的完整日期,结果参考:“2015-07-06 11:07:25”。 SELECT to_char(SYSDATE,'yyYy-mm-dD HH24:mi:ss') FROM dual; --oracle的日期格式和java不一样 --需求2:显示今天是几号,不包含年月和时间,结果参考:“8日”。 SELECT to_char(SYSDATE,'dd')||'日' FROM dual; --需求3:显示当月最后一天是几号,结果参考:”30“。 SELECT to_char(last_day(SYSDATE),'dd') FROM dual; --需求4:xiaoming的入职日期是2015-03-15,由于其入职日期当时忘记录入,现在请将其插入到emp表中。 UPDATE emp SET hiredate = to_date('2015-03-15','yyyy-mm-dd') WHERE ename = 'xiao_ming'; SELECT * FROM emp; COMMIT; --需求5:查看2015年2月份最后一天是几号,结果参考“28“ SELECT to_char(last_day(to_date('2015-02','yyyy-mm')),'dd') FROM dual; -- 不指定具体日期的话, 默认从1开始
【注意】和java不同,Oracle的日期格式对大小写不敏感。
【使用上的选择】
到底要用哪个函数,关键是传进来的目标的类型和最终需要的结果类型。
日期格式的常见元素:
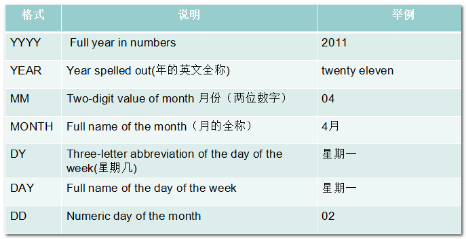
【示例】
需求:查看显示今天是星期几
SELECT to_char(SYSDATE,'day') FROM dual;
数字格式的常见元素:

提示:9代表任意数字,可以不存在。0代表数字,如果该位置不存在,则用0占位。
【示例】
--需求:查询员工的薪水,格式要求:两位小数,千位数分割,本地货币代码。 SELECT ename,sal,to_char(sal,'L99,999.00') FROM emp; SELECT ename,sal,to_char(sal,'L00,000.00') FROM emp;

4.8. 滤空函数(通用函数)
滤空函数也称为通用函数,其特点是:适用于任何数据类型,同时也适用于空值。
常见的滤空函数:

使用方法:
l nvl(a,c),当a为null的时候,返回c,否则,返回a本身。
l nvl2(a,b,c), 当a为null的时候,返回c,否则返回b—三元运算
其中,nvl2中的2是增强的意思,类似于varchar2。
l nullif(a,b),当a=b的时候,返回null,否则返回a
l coalesce(a,b,c,d),从左往右查找,当找到第一个不为null的值的时候,就显示这第一个有值的值。
【示例】
--需求:查询员工的月收入(基本薪资+奖金) SELECT ename,sal+nvl(comm,0) 月收入 FROM emp; SELECT ename ,NVL2(sal,sal,0)+nvl(comm,0) FROM emp;--为了小明 SELECT coalesce(NULL,NULL,1,2) FROM dual;--返回第一个不为空的值
4.9. 条件表达式
条件表达式的作用是:在SQL语句中使用判断的逻辑(类似于IF-THEN-ELSE)来呈现个性化的数据。
条件判断语句有两种:
CASE 表达式:SQL99的语法,类似Basic,比较繁琐
DECODE 函数:Oracle自己的语法,类似Java,比较简单
1.Decode函数
也可以理解为解码翻译函数。
语法:

语法解释:
decode (字段名,要翻译的原始值1,翻译后的值1,......,其他不满足翻译条件的默认值)
【示例】
--需求:要将工种job的英文转换为中文 SELECT ename,job, DECODE(job,'CLERK','职员','SALESMAN','销售人员','MANAGER','经理','其他工种') FROM emp;

业务场景补充:
比如人的性别:一般数据库存放的是:0和1,2,在直接出报表的时候,就需要转换显示。
SELECT NAME 姓名,DECODE(sex,1,'男',0,'女','凹凸曼') 性别 FROM TABLE;
2.Case子句
语法:

语法解释:
case 字段 when 要翻译的值 then 翻译的结果
when 要翻译的值 then 翻译的结果
......
else 默认的结果值
end
【示例】
SELECT * FROM emp; --需求:要将工种job转换为中文 SELECT t.ename, CASE job WHEN 'CLERK' THEN '办事员' WHEN 'SALESMAN' THEN '销售人员' ELSE '其他人员' END FROM emp t; --两种语法--第二种很复杂。。。。---虽然复杂但灵活 SELECT t.ename, CASE WHEN job='CLERK' THEN '办事员' WHEN job='SALESMAN' THEN '销售人员' ELSE '其他人员' END FROM emp t;
3.case子句增强
需求:查看公司员工的工资情况,要求显示员工的姓名、职位、工资、以及工资情况。如果是工资小于1000,则显示“工资过低”,
工资大于1000小于5000为“工资适中”,工资大于5000的,则显示“工资过高”:
SELECT ename,job,sal, CASE WHEN sal<1000 THEN '工资过低' WHEN sal BETWEEN 1000 AND 5000 THEN '工资适中' when sal IS NULL THEN '没工资酱油瓶' ELSE '工资太高' END FROM emp;
Decode和Case的使用选择:
在Oracle中,翻译值的这种条件判断,优先使用decode,因为简单明了,且Oracle有一定的优化;
更复杂的条件判断或者其他的关系型数据库,只能使用Case子句。
4.10. 嵌套函数

【示例】了解即可
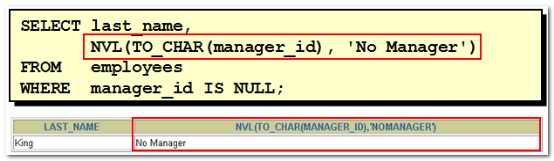
5. 多行函数
5.1. 多行函数的概念
多行函数也称之为分组函数、聚集函数。
简答的说就是把多行的值汇聚计算成一个值。
常见的分组函数:

【示例】

5.2. 空值问题
多行函数会自动滤空。
--需求:统计计算员工的平均奖金。(不同需求不同结果) SELECT AVG(comm) FROM emp;--统计的是有奖金的人的平均奖金 --相当于 SELECT SUM(comm)/COUNT(comm) FROM emp;--多行函数会自动滤空 --统计所有人的平均奖金 SELECT AVG(nvl(comm,0)) FROM emp;
AVG(comm)奖金为空的奖金不算,奖金为空的人数也不算
AVG(nvl(comm,0)),奖金为空的奖金算为0,奖金为空的人数算上
5.3. Count的使用注意点
count统计时可以使用不同的对象:*,column,1,不同的对象统计的方式和效率都不同。
--需求:统计员工的数量,要求使用count的多种统计方式,并分析原因。 SELECT COUNT(*) FROM emp;--效率最低,全表全字段扫描 SELECT COUNT(empno) FROM emp; --按照主键列来统计--效率也挺高,语法角度来说,不通用 SELECT COUNT(1) FROM emp; --统计的是字符是1的这一列,效率高(原因,这一列只有一个字符,运算的时候,数据流很小,而且是固定列) SELECT 1,ename FROM emp; SELECT COUNT(11111111111) FROM emp;--统计的参数不是列号,数字无所谓
5.4. 嵌套函数
distinct可用来过滤掉多余的重复记录只保留一条,但往往只用 它来返回不重复记录的条数,而不是用它来返回显示不重记录的所有值。
因此,一般和count配合使用,作为统计非空且不重复的记录数。
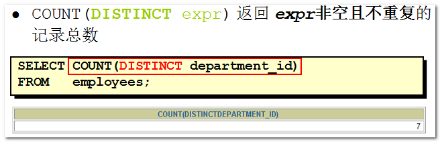
需求:--查看有几个部门,通过emp表 SELECT COUNT(DISTINCT(deptno)) FROM emp;
慢的原因是:
distinct只有用二重循环查询来解决,而这样对于一个数据量非常大的表来说,无疑是会直接影响到效率的。
5.5. 关于聚合函数的思考
下面的语句是否正确?
SELECT deptno,MAX(sal) FROM emp;
【分析】
因为聚合函数处理的是数据组,在本例中,MAX函数将整个EMP表看成一组,而deptno的数据没有进行任何分组,因此SELECT语句没有逻辑意义。
要想解决这个问题,需要对deptno进行分组。
[了解]:MAX()和MIN()函数不仅可以作用于数值型数据,也可以作用于字符串或是日期时间数据类型的数据。
补充字符串对比:

解决方案:
1. 日期直接存成日期格式(date)
2. 日期标准,2015-09-10
6. 分组子句
6.1. 分组数据的概念
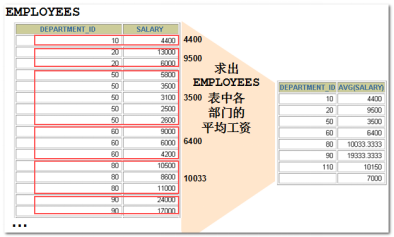
可以通过group by子句达到效果。
6.2. 分组子句的语法

作用:可以使用GROUP BY 子句将表中的数据分成若干组
6.3. 分组子句的要求
在SELECT 列表中所有未包含在组函数中的列都应该包含在 GROUP BY 子句中。
反之,包含在 GROUP BY 子句中的列不一定包含在SELECT 列表中
请判断下面的示例的语法是否正确:
3错,别的都对

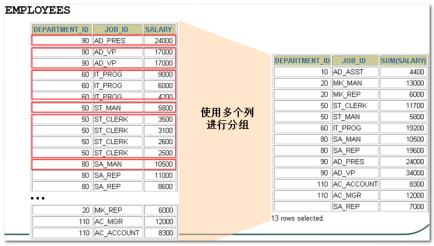
--需求1:查询显示各个部门的平均薪资情况,并且按照部门号从低到高排列。 SELECT deptno, AVG(sal) FROM emp GROUP BY deptno ORDER BY deptno; --需求2:查询显示各个部门的不同工种的平均薪资情况,并且按照部门号从低到高排列 SELECT deptno,job, AVG(sal) FROM emp GROUP BY deptno,job ORDER BY deptno;
7. 过滤分组(having)
为分组子句添加查询条件的
7.1. 过滤分组的概念
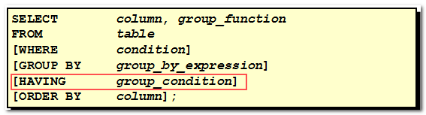
7.2. 过滤分组的语法
7.3. Where和having的选择
-
语法上的不同选择
1)是否能使用组函数的区别:
不能在 WHERE 子句中使用组函数(注意),即where子句不能完全代替having子句。
可以在 HAVING 子句中使用组函数。(having可以使用任何的条件写法)但必须要配合group by使用
--需求:查询平均工资大于2000的部门信息,要求显示部门号和平均工资 SELECT deptno, AVG(sal) FROM emp WHERE avg(sal)>2000 GROUP BY deptno; --错误,不能在 WHERE 子句中使用组函数 -- 只要条件中有分组函数的 一律使用 having SELECT deptno, AVG(sal) FROM emp GROUP BY deptno HAVING avg(sal)>2000;
非法使用组函数的错误提示:

2)HAVING子句不能离开GROUP BY子句单独使用,HAVING子句无法完全代替WHERE子句。
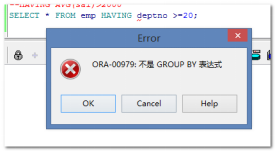
需求:查询所属部门号大于等于20的员工信息。(无法使用having子句) SELECT * FROM emp WHERE deptno >=20;--正确 SELECT * FROM emp HAVING deptno >=20;--错误
非法使用having的错误提示:
2.性能优化方面的选择—sql语句优化
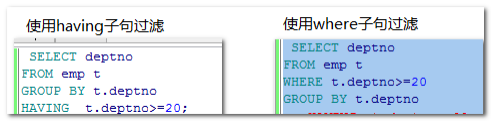
思考:下面两组语句哪个效率更高。
分析:
使用having子句过滤,是先分组,再过滤,注意:分组的时候是全表扫描的,效率较低。
使用where子句过滤,是先过滤再分组,注意:分组的时候仅需要扫描部分数据,效率较高。
【结论(如何选择)】:
从语法上看,两者选择简单归纳为,就是group by分组之后需要的条件中有组函数的,就必须得用having,其他都可以直接用where。
从性能上看,实际开发中,使用分组的时候尽量先加一个where的过滤条件。没有组函数的情况下,尽量选择where。