加载部分HTML文本(即主资源)后便可以开始解析HTML元素(对输入字节流进行逐字扫描,识别HTML元素),最后生成DOM树,本文只讲HTML解析。
HTML解析部分时序图:

其中最为重要的过程是(1)startToken(2)nextToken(3)endToken(4)constructTreeFromHTMLToken,这里的4步是循环执行的,当输入字符结束时,则跳出循环。
HTMLTokenizer::nextToken则创建了token,然后可以根据token创建html元素,解析的整个过程就是一个状态机
HTML解析状态机:

初始状态为DataState,状态机结束后会返回一个HTMLToken对象,不同的结束方式(上图中有三个出口1、2、3)HTMLToken的类型也会不同。
class HTMLToken { enum Type { Uninitialized, DOCTYPE, StartTag, EndTag, Comment, Character, EndOfFile, }; } ;
对于1结束位置:Type=EndOfFile
对于2结束位置:Type=Character
对于3结束位置:解析注释-Type=Comment,解析文档类型-Type=DOCTYPE,解析标签(Type=StartTag/EndTag)
子状态机/解析注释:

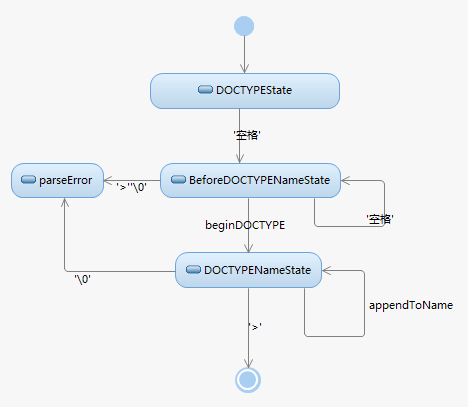
子状态机/解析文档类型:
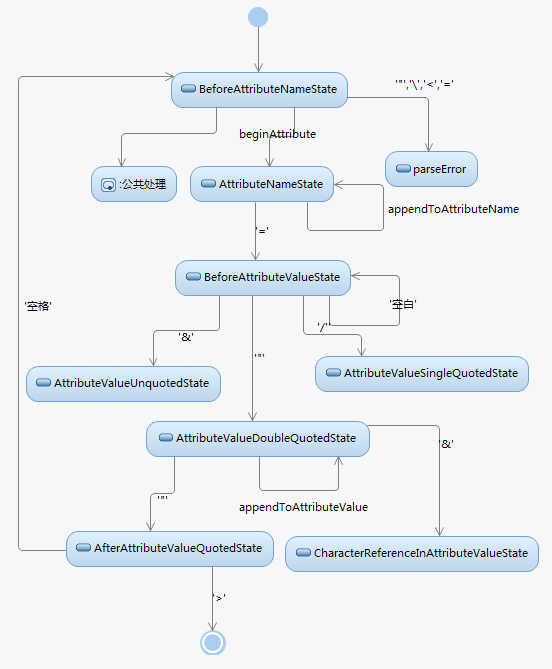
子状态机/解析标签名、属性名、属性值

最后以一个简单的HTML为例,描述解析过程:
<!Doctype html>
<!--comment-->
<html>
<body>
<p>First name:</p>
<input type="text"/>
</body>
</html>
1.解析文档类型
'<!Doctype html>',DataState状态迁移到TagOpenState状态
'<!Doctype html>',TagOpenState状态迁移到MarkupDeclarationOpenState状态
'<!Doctype html>',MarkupDeclarationOpenState状态迁移到DOCTYPEState状态
'<!Doctype html>',DOCTYPEState状态迁移到BeforeDOCTYPENameState状态
'<!Doctype html>',BeforeDOCTYPENameState状态迁移到DOCTYPENameState状态,并执行beginDOCTYPE
'<!Doctype html>',DOCTYPENameState状态迁移到DOCTYPENameState状态,并执行appendToName
'<!Doctype html>',结束
2、解析注释
'<!--comment-->',DataState状态迁移到TagOpenState状态
'<!--comment-->',TagOpenState状态迁移到MarkupDeclarationOpenState状态
'<!--comment-->',MarkupDeclarationOpenState状态迁移到CommentStartState状态
'<!--comment-->',CommentStartState状态迁移到CommentState状态,并执行appendToComment
'<!--comment-->',CommentState状态迁移到CommentState状态,并执行appendToComment
'<!--comment-->',CommentState状态迁移到CommentEndDashState状态
'<!--comment-->',CommentEndDashState状态迁移到CommentEndState状态
'<!--comment-->',结束
3、解释'html'元素
'<html>',DataState状态迁移到TagOpenState状态
'<html>',TagOpenState状态迁移到TagNameState状态,并执行beginStartTag
'<html>',TagNameState状态迁移到TagNameState状态,并执行appendToName
'<html>',结束
4、解释'body'和'p'元素,同3
6、解析'p'元素内容
'First name:</p>',DataState状态迁移到DataState状态,并执行bufferCharacter
'First name:</p>',DataState状态迁移到DataState状态,并执行bufferCharacter
'First name:</p>',判断bufferCharacter是否存在字符,存在则结束
7、解析'/p'元素
'</p>',DataState状态迁移到TagOpenState状态
'</p>',TagOpenState状态迁移到EndTagOpenState状态
'</p>',EndTagOpenState状态迁移到TagNameState状态,并执行beginEndTag
'</p>',结束
8、解析'input'元素
'<input type="text" />',DataState -> TagOpenState
'<input type="text" />',TagOpenState -> TagNameState,并执行beginStartTag
'<input type="text" />',TagNameState -> TagNameState,并执行appendToName
'<input type="text" />',TagNameState -> BeforeAttributeNameState
'<input type="text" />',BeforeAttributeNameState -> AttributeNameState,并执行beginAttribute
'<input type="text" />',AttributeNameState -> AttributeNameState,并执行appendToAttributeName
'<input type="text" />',AttributeNameState -> BeforeAttributeValueState
'<input type="text" />',BeforeAttributeValueState -> AttributeValueDoubleQuotedState
'<input type="text" />',BeforeAttributeValueState -> AttributeValueDoubleQuotedState,并执行appendToAttributeValue
'<input type="text" />',AttributeValueDoubleQuotedState -> AttributeValueDoubleQuotedState,并执行appendToAttributeValue
'<input type="text" />',AttributeValueDoubleQuotedState -> AfterAttributeValueQuotedState,并执行endAttribute
'<input type="text" />',AfterAttributeValueQuotedState-> BeforeAttributeNameState
'<input type="text" />',BeforeAttributeNameState-> SelfClosingStartTagState
'<input type="text" />',结束,并执行setSelfClosing
9、解析'/body'和'/html'元素,同7
参考文章: