RDD概念
Spark 的核心是建立在统一的抽象弹性分布式数据集(Resiliennt Distributed Datasets,RDD)之上的,这使得 Spark 的各个组件可以无缝地进行集成,能够在同一个应用程序中完成大数据的处理。
RDD是什么
RDD,全称 弹性分布式数据集 (Resilient Distributed DataSet)。它是一种有容错机制的特殊数据集合,可以分布在集群的结点上,以函数式操作集合的方式进行各种并行操作。
通俗点来讲,可以将 RDD 理解为一个分布式对象集合,本质上是一个只读的分区记录集合。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段。一个 RDD 的不同分区可以保存到集群中的不同结点上,从而可以在集群中的不同结点上进行并行计算。
RDD特点
RDD 具有容错机制,并且只读不能修改,可以执行确定的转换操作创建新的 RDD。具体来讲,RDD 具有以下几个属性。
- 只读:不能修改,只能通过转换操作生成新的 RDD。
- 分布式:可以分布在多台机器上进行并行处理。
- 弹性:计算过程中内存不够时它会和磁盘进行数据交换。
- 基于内存:可以全部或部分缓存在内存中,在多次计算间重用。
- 容错的:
RDD 实质上是一种更为通用的迭代并行计算框架,用户可以显示控制计算的中间结果,然后将其自由运用于之后的计算。
RDD 五大属性
Partition List:分片列表,记录RDD的分片,可以在创建 RDD的时候指定分区数目,也可以通过算子来生成新的RDD从而改变分区数目
Compute Function:为了实现容错,需要记录 RDD之间转换所执行的计算函数
RDD Dependencies :RDD之间的依赖关系,要在RDD中记录其上级RDD是谁,从而实现容错和计算
Partitioner:为了执行 Shuffled操作,必须要有一个函数用来计算数据应该发往哪个分区
Preferred Location:优先位置,为了实现数据本地性操作,从而移动计算而不是移动存储,需要记录每个 RDD分区最好应该放在什么位置
RDD代码入门
主要是一个RDD大入口,sparkContext,和三种创建RDD的方法 以及 三个RDD算子初步使用,map , flatMap , reduceByKey。
package rdd import org.apache.spark.{SparkConf, SparkContext} import org.junit.Test class Rdd { // SparkContext 创建 和 RDD 创建 @Test def sparkContext(): Unit ={ /* * 步骤 * 1、创建 SparkConf,配置基本信息 * 2、创建 SparkContext,利用上面的conf配置作为参数创建。 * */ val conf = new SparkConf().setMaster("local[6]").setAppName("spark_context") val sc = new SparkContext(conf) // sparkContext 作为 RDD 的大入口,具备许多功能,创建RDD,配置参数等。 // 使用完后,需要对SparkContext进行关闭 } // 可以将通用部分拿到方法外,类一加载就会执行,Scala的特点。 val conf = new SparkConf().setMaster("local[6]").setAppName("spark_context") val sc = new SparkContext(conf) /* * 三种创建RDD的方式 * - 从本地集合创建 * - 从文件创建 * - 从 一个 RDD 衍生一个新的 RDD * */ def rddCreate(): Unit ={ /* * 从本地集合创建 */ val seq = Seq(1, 2, 3) sc.parallelize(seq,2) // 第二个参数可选,分区数 sc.makeRDD(seq, 2) /* * 从文件创建 */ sc.textFile("") // 路径传入由两种方式 hdfs://bigdata1//... 或 file://... // 支持aws(亚马逊) 和 阿里云 :需要指定的 API } /* * 从 一个 RDD 衍生一个新的 RDD * 通过rdd的三个算子:map,flatMap,reduceByKey */ @Test def rddSuanzi(): Unit ={ /* * map:将集合里的每个元素进行操作,得到一个新集合 * */ // 1、创建RDD val map_rdd1 = sc.parallelize(Seq(1, 2, 3)) // 2、执行 map 操作 val map_rdd2 = map_rdd1.map(item => item * 10) // 接收到的参数,方法的返回值 // 3、获取结果 collect val result_map = map_rdd2.collect() // 打印得到结果 10 20 30 result_map.foreach(item => print(item + " ")) println() /* * flatMap:将集合每个数据进行操作,返回的是一个个数组,falt将其展开,得到一个新的大集合 * */ val flat_rdd1 = sc.parallelize(Seq("hello dongao", "hello zhangsan", "hello wangwu")) // split() 是得到一个数组,但flat自动将其展开 val flat_rdd2 = flat_rdd1.flatMap(item => item.split(" ")) val result_flat = flat_rdd2.collect() result_flat.foreach(item => print(item + " ")) println() /* * reduceByKey:先按照key分组,然后将每个组的value聚合起来 * */ val reduce_rdd1 = sc.parallelize(Seq("hello dongao", "hello zhangsan", "hello wangwu")) val reduce_rdd2 = reduce_rdd1.flatMap(item => item.split(" ")) // 将每个单词展开 .map(item => (item, 1)) // 将展开的每个单词,作为一个词频为 1的 元组。 .reduceByKey( (curr, agg) => curr + agg ) val result_reduce = reduce_rdd2.collect() result_reduce.foreach(item => print(item + " ")) // 停止sparkContext sc.stop() } }
其中,reduceByKey 的示例如下图:
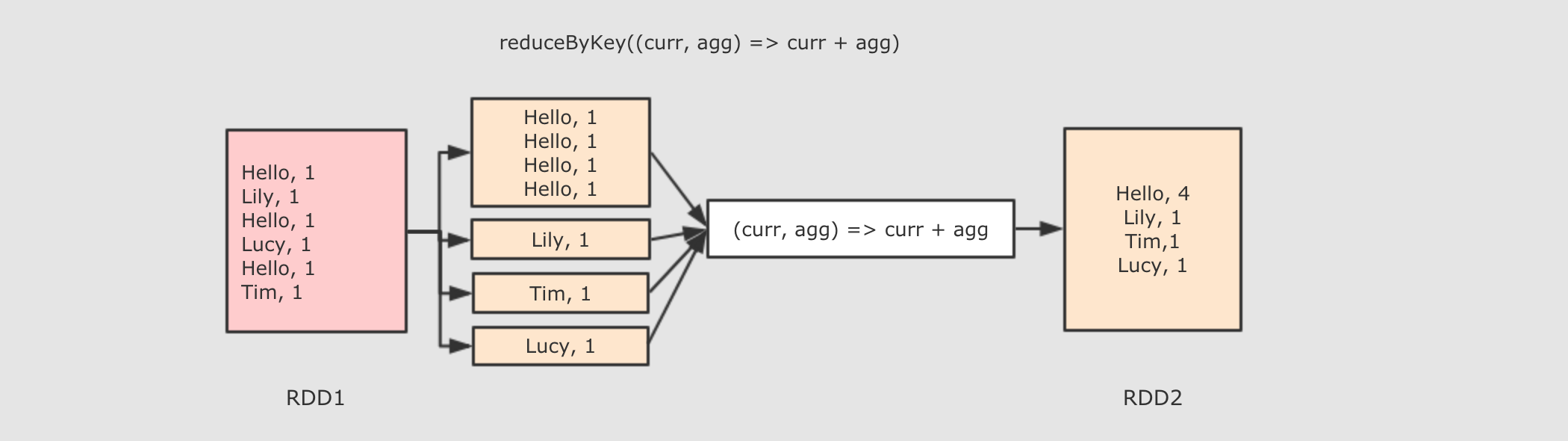
reduceByKey 算子作用:
首先按照 Key 分组, 接下来把整组的 Value 计算出一个聚合值, 这个操作非常类似于 MapReduce 中的 Reduce
参数
func → 执行数据处理的函数, 传入两个参数, 一个是当前值, 一个是局部汇总, 这个函数需要有一个输出, 输出就是这个 Key 的汇总结果,并进行更新
注意点
-
ReduceByKey 只能作用于 Key-Value 型数据, Key-Value 型数据在当前语境中特指 Tuple2
-
ReduceByKey 是一个需要 Shuffled 的操作
-
和其它的 Shuffled 相比, ReduceByKey是高效的, 因为类似 MapReduce 的, 在 Map 端有一个 Cominer, 这样 I/O 的数据便会减少
map, flatMap 和 reduceByKey 算子总结
-
map 和 flatMap 算子都是转换, 只是 flatMap 在转换过后会再执行展开, 所以 map 是一对一, flatMap 是一对多
-
reduceByKey 类似 MapReduce 中的 Reduce