模块化是软件系统的属性,这个系统被分解为一组高内聚,低耦合的模块。理想状态下我们只需要完成自己部分的核心业务逻辑代码,其他方面的依赖可以通过直接加载被人已经写好模块进行使用即可。
一个模块化系统所必须的能力:
定义封装的模块。定义新模块对其他模块的依赖。可对其他模块的引入支持。
CommonJS
nodeJs出现后使用了CommonJS规范来解决JS的模块化问题。由于Node.js主要用于服务器的编程,加载的模块文件一般都已经存在本地硬盘,所以加载起来比较快,不用考虑异步加载的方式,所以CommonJS规范也是同步加载依赖模块,加载完后执行后面代码。但如果是浏览器环境,要从服务器加载模块,这是就必须采用异步模式。所以就有了 AMD CMD 解决方案。
AMD和CMD
AMD(Asynchromous Module Definition)是equireJS 在推广过程中对模块定义的规范化产出。CMD是SeaJS 在推广过程中对模块定义的规范化产出。RequireJs出自dojo加载器的作者James Burke,SeaJs出自国内前端大师玉伯。二者的区别,玉伯在12年如是说:
RequireJS 和 SeaJS 都是很不错的模块加载器,两者区别如下:
两者定位有差异。RequireJS 想成为浏览器端的模块加载器,同时也想成为 Rhino / Node 等环境的模块加载器。SeaJS 则专注于 Web 浏览器端,同时通过 Node 扩展的方式可以很方便跑在 Node 服务器端.
两者遵循的标准有差异。RequireJS 遵循的是 AMD(异步模块定义)规范,SeaJS 遵循的是 CMD (通用模块定义)规范。规范的不同,导致了两者 API 的不同。SeaJS 更简洁优雅,更贴近 CommonJS Modules/1.1 和 Node Modules 规范。
两者社区理念有差异。RequireJS 在尝试让第三方类库修改自身来支持 RequireJS,目前只有少数社区采纳。SeaJS 不强推,而采用自主封装的方式来“海纳百川”,目前已有较成熟的封装策略。
两者代码质量有差异。RequireJS 是没有明显的 bug,SeaJS 是明显没有 bug。
两者对调试等的支持有差异。SeaJS 通过插件,可以实现 Fiddler 中自动映射的功能,还可以实现自动 combo 等功能,非常方便便捷。RequireJS 无这方面的支持。
两者的插件机制有差异。RequireJS 采取的是在源码中预留接口的形式,源码中留有为插件而写的代码。SeaJS 采取的插件机制则与 Node 的方式一致:开放自身,让插件开发者可直接访问或修改,从而非常灵活,可以实现各种类型的插件。.
其中反对这么做的人的观点:
我个人感觉requirejs更科学,所有依赖的模块要先执行好。如果A模块依赖B。当执行A中的某个操doSomething()后,再去依赖执行B模块require('B');如果B模块出错了,doSomething的操作如何回滚? 很多语言中的import, include, useing都是先将导入的类或者模块执行好。如果被导入的模块都有问题,有错误,执行当前模块有何意义?
而依赖dependencies是工厂的原材料,在工厂进行生产的时候,是先把原材料一次性都在它自己的工厂里加工好,还是把原材料的工厂搬到当前的factory来什么时候需要,什么时候加工,哪个整体时间效率更高?
首先回答第一个问题。
第一个问题的题设并不完全正确,“依赖”和“执行”的概念比较模糊。编程语言执行通常分为两个阶段,编译(compilation)和运行(runtime)。对于静态语言(比如C/C++)来说,在编译时如果出现错误,那可能之前的编译都视为无效,的确会出现描述中需要回滚或者重新编译的问题。但对于动态语言或者脚本语言,大部分执行都处在运行时阶段或者解释器中:假设我使用Nodejs或者Python写了一段服务器运行脚本,在持续运行了一段时间之后因为某项需求要加载某个(依赖)模块,同时也因为这个模块导致服务端挂了——我认为这时并不存在回滚的问题。在加载依赖模块之前当前的模块的大部分功能已经成功运行了。
再回答第二个问题。
对于“工厂”和“原材料”的比喻不够恰当。难道依赖模块没有加载完毕当前模块就无法工作吗?requirejs的确是这样的,从上面的截图可以看出,依赖模块总是先于当前模块加载和执行完毕。但我们考虑一下基于CommonJS标准的Nodejs的语法,使用require函数加载依赖模块可以在页面的任何位置,可以只是在需要的时候。也就是说当前模块不必在依赖模块加载完毕后才执行。
你可能会问,为什么要拿AMD标准与CommonJS标准比较,而不是CMD标准?
玉伯在CommonJS 是什么这篇文章中已经告诉了我们CMD某种程度上遵循的就是CommonJS标准:
从上面可以看出,Sea.js 的初衷是为了让 CommonJS Modules/1.1 的模块能运行在浏览器端,但由于浏览器和服务器的实质差异,实际上这个梦无法完全达成,也没有必要去达成。
更好的一种方式是,Sea.js 专注于 Web 浏览器端,CommonJS 则专注于服务器端,但两者有共通的部分。对于需要在两端都可以跑的模块,可以 有便捷的方案来快速迁移。
CMD推崇依赖就近,可以把依赖写进你的代码中的任意一行,例:
define(function(require, exports, module) {var a = require('./a')a.doSomething()var b = require('./b')b.doSomething()})
代码在运行时,首先是不知道依赖的,需要遍历所有的require关键字,找出后面的依赖。具体做法是将function toString后,用正则匹配出require关键字后面的依赖。显然,这是一种牺牲性能来换取更多开发便利的方法。
而AMD是依赖前置的,换句话说,在解析和执行当前模块之前,模块作者必须指明当前模块所依赖的模块,表现在require函数的调用结构上为:
define(['./a','./b'],function(a,b){a.doSomething()b.doSomething()})
代码在一旦运行到此处,能立即知晓依赖。而无需遍历整个函数体找到它的依赖,因此性能有所提升,缺点就是开发者必须显式得指明依赖——这会使得开发工作量变大,比如:当你写到函数体内部几百上千行的时候,忽然发现需要增加一个依赖,你不得不回到函数顶端来将这个依赖添加进数组。
细心的读者可能发现,到目前位置我讨论的AMD和CMD的思想的关于依赖的部分,都只讨论的“硬依赖”,也就是执行前肯定需要的依赖,但是这不是全部的情况。有的时候情况是这样的:
// 函数体内:if(status){a.doSomething()}
在这个函数体内,可能依赖a,也可能不依赖a,我把这种可能的依赖成为“软依赖”。对于软依赖当然可以直接当硬依赖处理,但是这样不经济,因为依赖是不一定的,有可能加载了此处的依赖而实际上没有用上。
对于软依赖的处理,我推荐依赖前置+回调函数的实现形式。上面的例子简单表述如下:
// 函数体内:if(status){async(['a'],function(a){a.doSomething()})}
至此可以对由commonJS衍生出来的方案做出总结了。在浏览器端来设计模块加载机制,需要考虑依赖的问题。
我们先把依赖分为两种,“强依赖” —— 肯定需要 和“弱依赖” —— 可能需要。
对于强依赖,如果要性能优先,则考虑参照依赖前置的思想设计你的模块加载器;如果考虑开发成本优先,则考虑按照依赖就近的思想设计你的模块加载器。
对于弱依赖,只需要将弱依赖的部分改写到回调函数内即可。
无论AMD与CMD都要面临以下几个问题:
1、模块式如何注册的,define函数都做了什么?
2、他们是如何知道模块的依赖?
3、如何做到异步加载?尤其是seajs如何做到异步加载延迟执行的?
辩证法第一规律:事物之间具有有机联系。AMD与CMD都借鉴了CommonJs,宏观层面必有一致性,比如整体处理流程: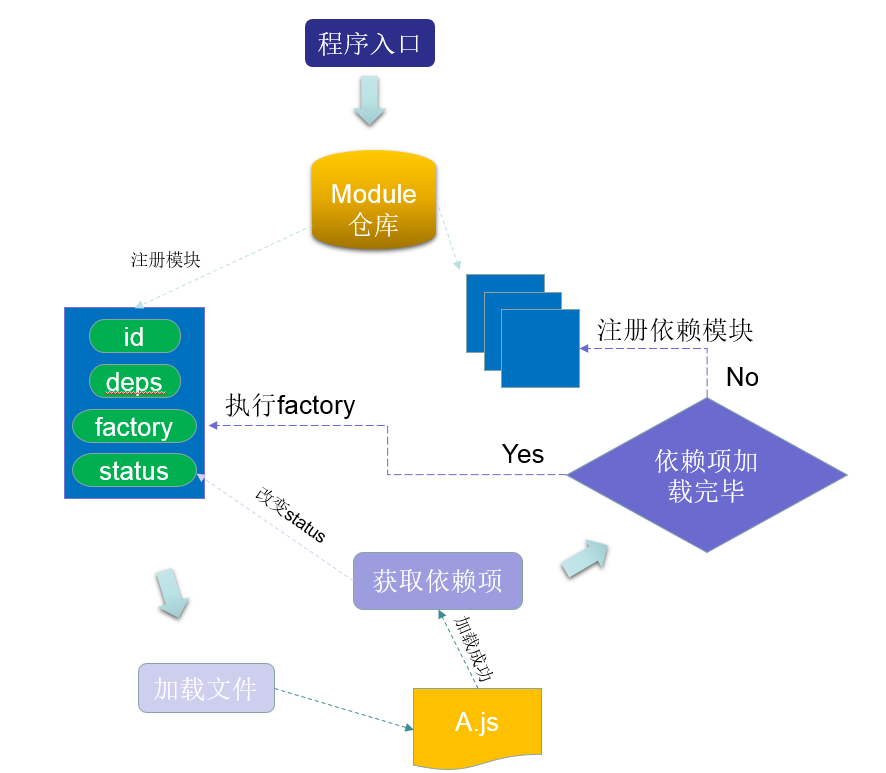
模块的加载解析到执行过程一共经历了6个步骤:
1、由入口进入程序
2、进入程序后首先要做的就是建立一个模块仓库(这是防止重复加载模块的关键),JavaScript原生的object对象最为适合,key代表模块Id,value代表各个模块,处理主模块
3、向模块仓库注册一模块,一个模块最少包含四个属性:id(唯一标识符)、deps(依赖项的id数组)、factory(模块自身代码)、status(模块的状态:未加载、已加载未执行、已执行等),放到代码中当然还是object最合适
4、模块即是JavaScript文件,使用无阻塞方式(动态创建script标签)加载模块
5、模块加载完毕后,获取依赖项(amd、cmd区别),改变模块status,由statuschange后,检测所有模块的依赖项。
由于requirejs与seajs遵循规范不同,requirejs在define函数中可以很容易获得当前模块依赖项。而seajs中不需要依赖声明,所以必须做一些特殊处理才能否获得依赖项。方法将factory作toString处理,然后用正则匹配出其中的依赖项,比如出现require(./a),则检测到需要依赖a模块。
6、如果模块的依赖项完全加载完毕(amd中需要执行完毕,cmd中只需要文件加载完毕,注意这时候的factory尚未执行,当使用require请求该模块时,factory才会执行,所以在性能上seajs逊于requirejs),执行主模块的factory函数;否则进入步骤3。
处理流程摘自:以代码爱好者角度来看AMD与CMD
写法举例
CommonJs
// 文件名: foo.jsdefine(['jquery', 'underscore'], function ($, _) {// 方法function a(){}; // 私有方法,因为没有被返回(见下面)function b(){}; // 公共方法,因为被返回了function c(){}; // 公共方法,因为被返回了// 暴露公共方法return {b: b,c: c}});```AMD```javascript// 文件名: foo.jsvar $ = require('jquery');var _ = require('underscore');// methodsfunction a(){}; // 私有方法,因为它没在module.exports中 (见下面)function b(){}; // 公共方法,因为它在module.exports中定义了function c(){}; // 公共方法,因为它在module.exports中定义了// 暴露公共方法module.exports = {b: b,c: c};
CMD
define(function (requie, exports, module) {//依赖可以就近书写var a = require('./a');a.test();...//软依赖if (status) {var b = requie('./b');b.test();}});
UMD
UMD是AMD和CommonJS的糅合,兼容了AMD和CommonJS,同时还支持老式的“全局”变量规范。
AMD 浏览器第一的原则发展 异步加载模块。CommonJS 模块以服务器第一原则发展,选择同步加载,它的模块无需包装(unwrapped modules)。这迫使人们又想出另一个更通用的模式UMD (Universal Module Definition)。希望解决跨平台的解决方案。UMD先判断是否支持Node.js的模块(exports)是否存在,存在则使用Node.js模块模式。
在判断是否支持AMD(define是否存在),存在则使用AMD方式加载模块。
(function (root, factory) {if (typeof define === 'function' && define.amd) {// AMDdefine(['jquery', 'underscore'], factory);} else if (typeof exports === 'object') {// Node, CommonJS之类的module.exports = factory(require('jquery'), require('underscore'));} else {// 浏览器全局变量(root 即 window)root.returnExports = factory(root.jQuery, root._);}}(this, function ($, _) {// 方法function a(){}; // 私有方法,因为它没被返回 (见下面)function b(){}; // 公共方法,因为被返回了function c(){}; // 公共方法,因为被返回了// 暴露公共方法return {b: b,c: c}}));
AMD、CMD、UMD 模块的写法
关于 CommonJS AMD CMD UMD
扩展阅读:
AMD规范文档
amdjs 的 require 接口文档
amdjs 的接口文档
RequireJS官网接口文档
模块系统
前端模块化开发的价值
前端模块化开发那点历史
CMD 模块定义规范
SeaJS API快速参考
从 CommonJS 到 Sea.js
RequireJS和AMD规范
CommonJS规范
Javascript模块化编程
Javascript模块化编程
知乎 AMD 和 CMD 的区别有哪些?
JavaScript模块化开发 - CommonJS规范
JavaScript模块化开发 - AMD规范
模块化设计
模块化