C语言博客作业--函数嵌套调用
一、实验作业
1.1 PTA题目
十进制转换二进制
设计思路
传入n
边界条件:n<=1
递归模式:n/2
每一轮的递归都输出n取余2
代码截图

调试问题
边界值设置成n==1,导致段错误
解决方法:改为n<=1,就能避免
1.2 学生成绩管理系统
1.2.1 画函数模块图,简要介绍函数功能。

1.2.2 截图展示你的工程文件,如:
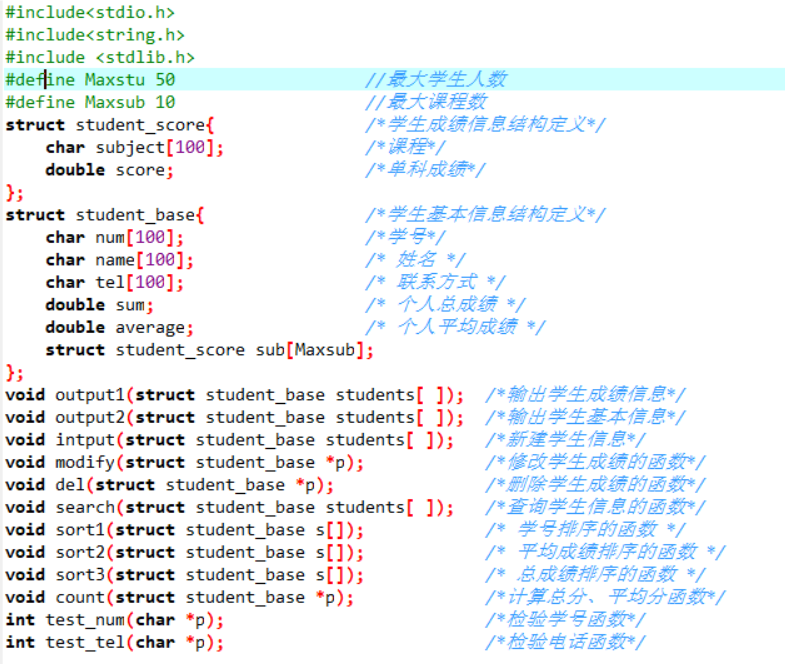
1.2.3 函数代码部分截图
本系统代码总行数:386
-
头文件
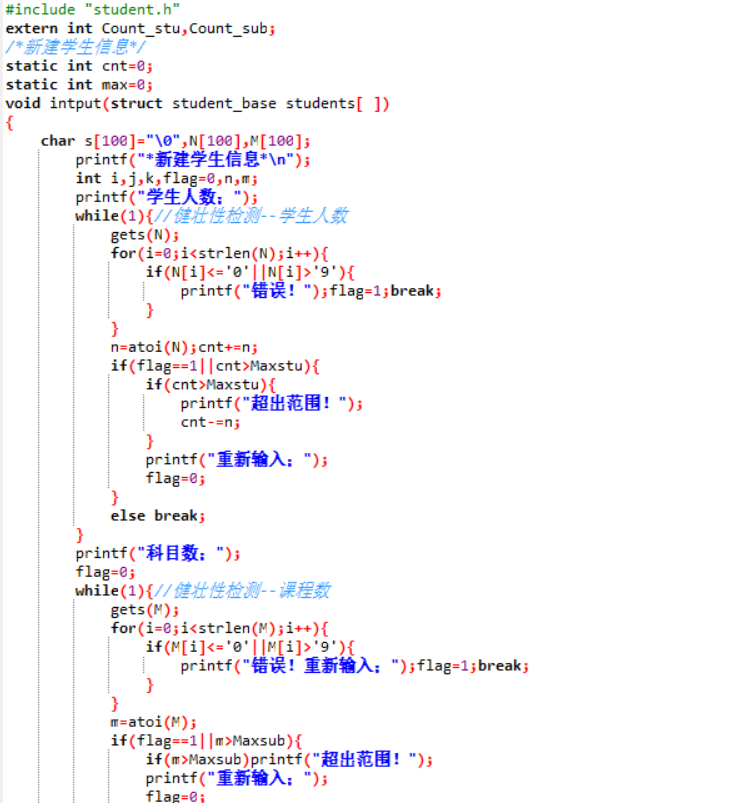
-
插入学生信息及学生成绩信息代码


-
删除学生成绩信息代码

-
总分排序代码

1.2.4 调试结果展示
菜单及功能实现
-
菜单及功能1(新增学生人数)

-
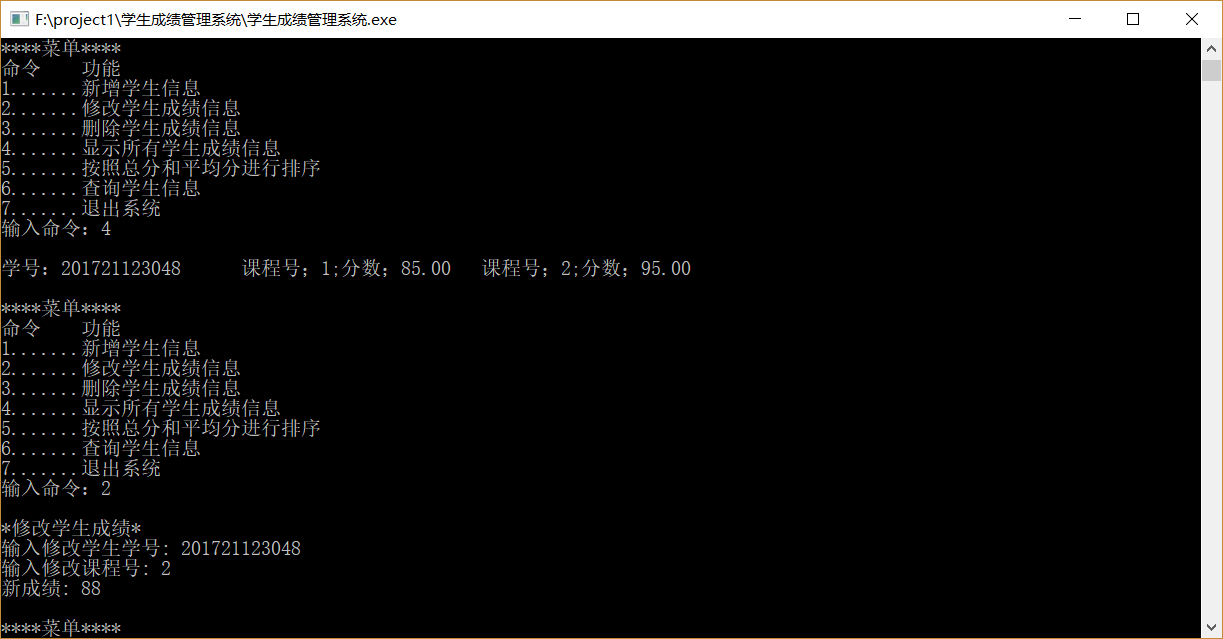
功能4(显示全部成绩信息)显示一下功能1操作结果
-
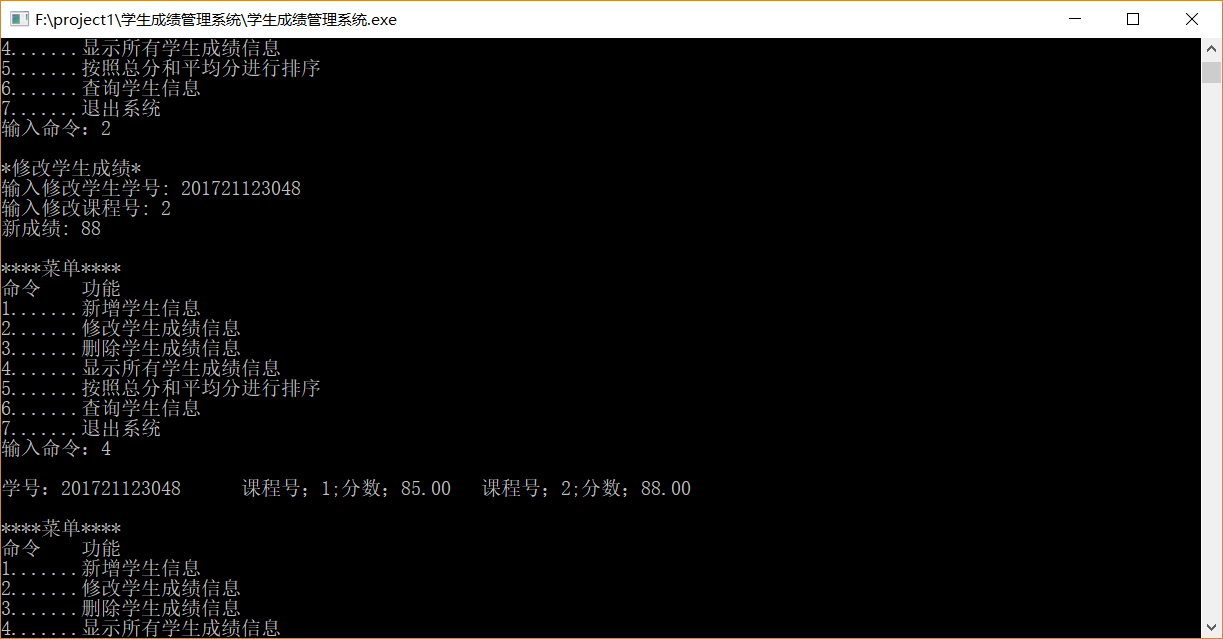
功能2(修改成绩)
-
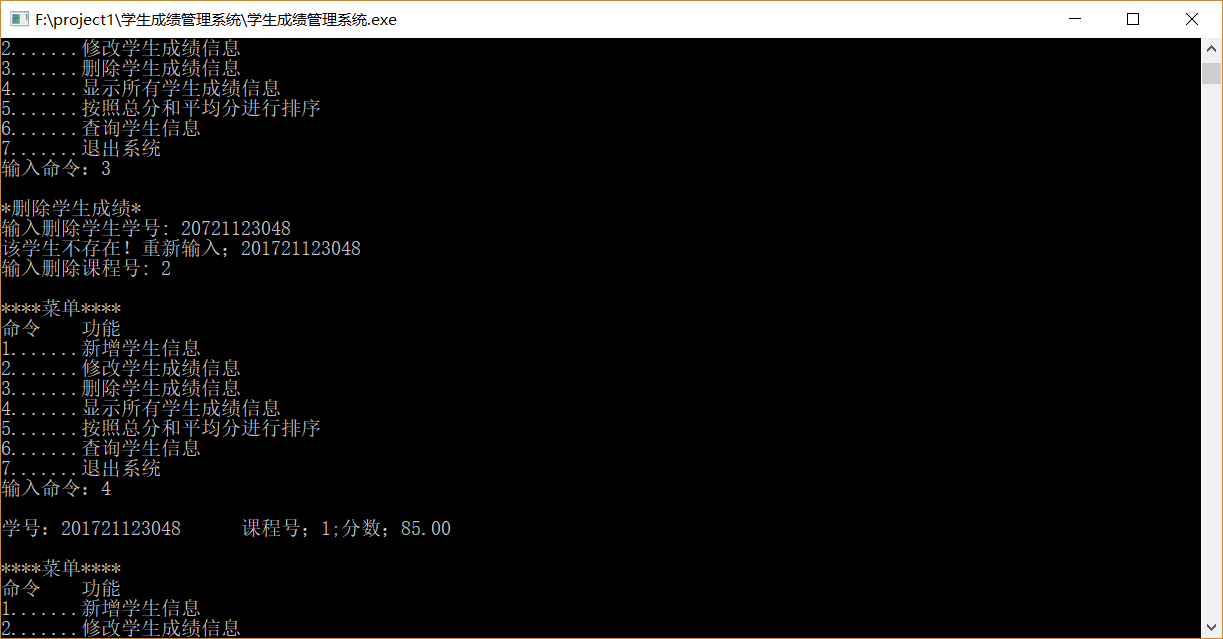
功能3(删除成绩)
-
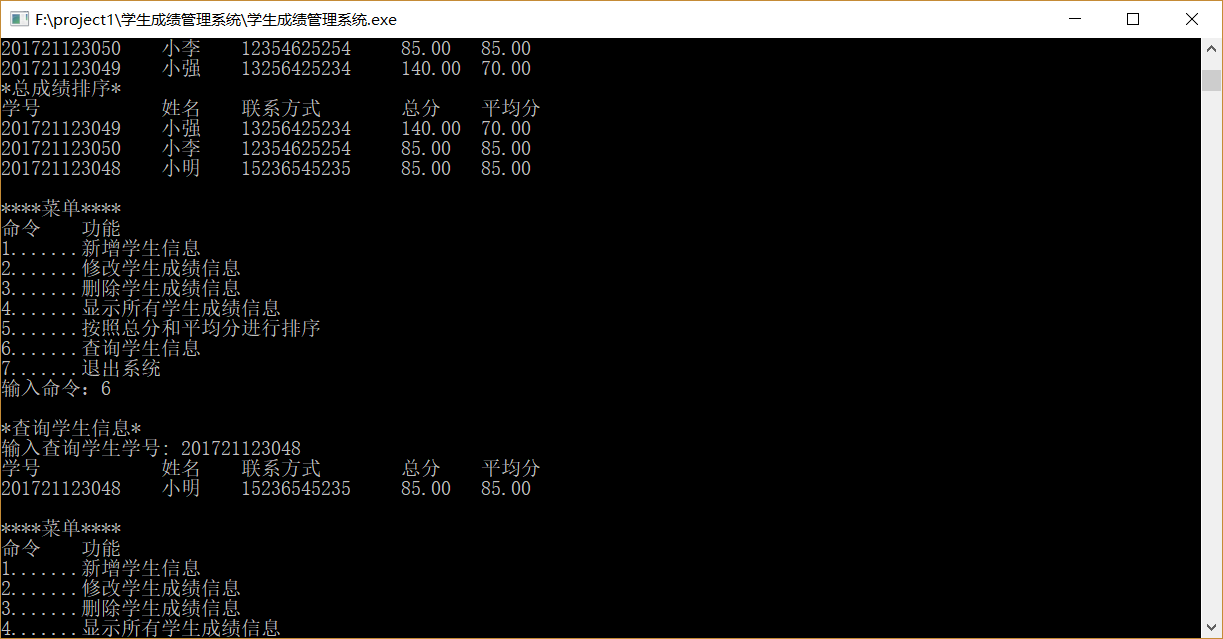
功能5(两种排序)新增了几组数据

-
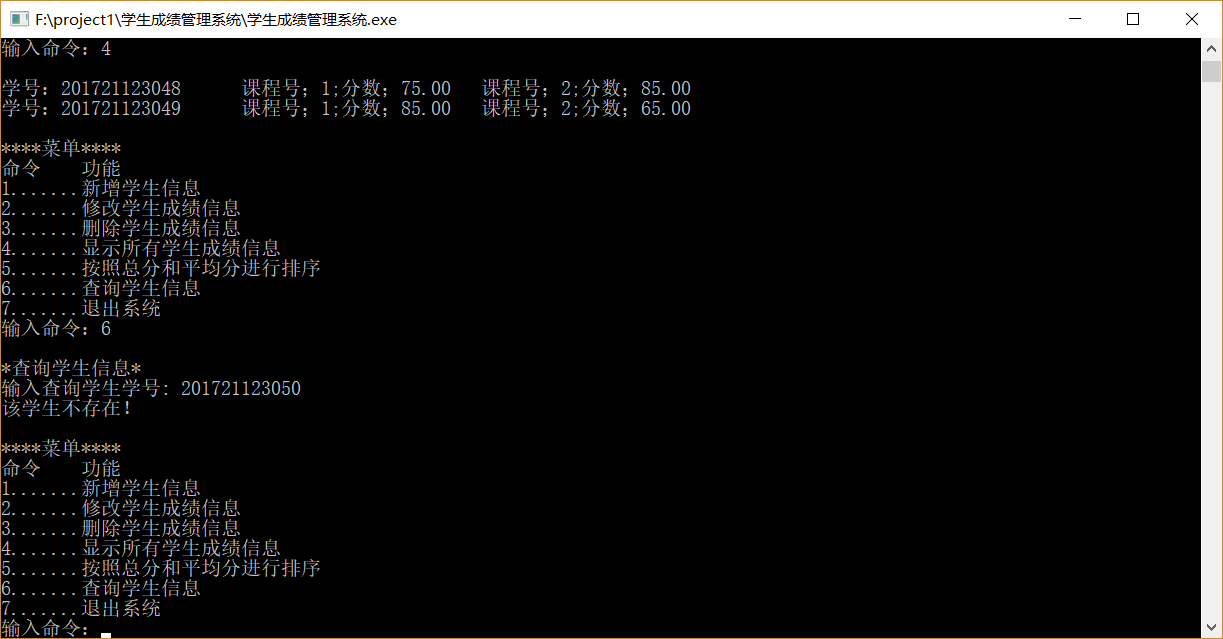
功能6(查询信息)
-
功能7(退出系统)

健壮性
-
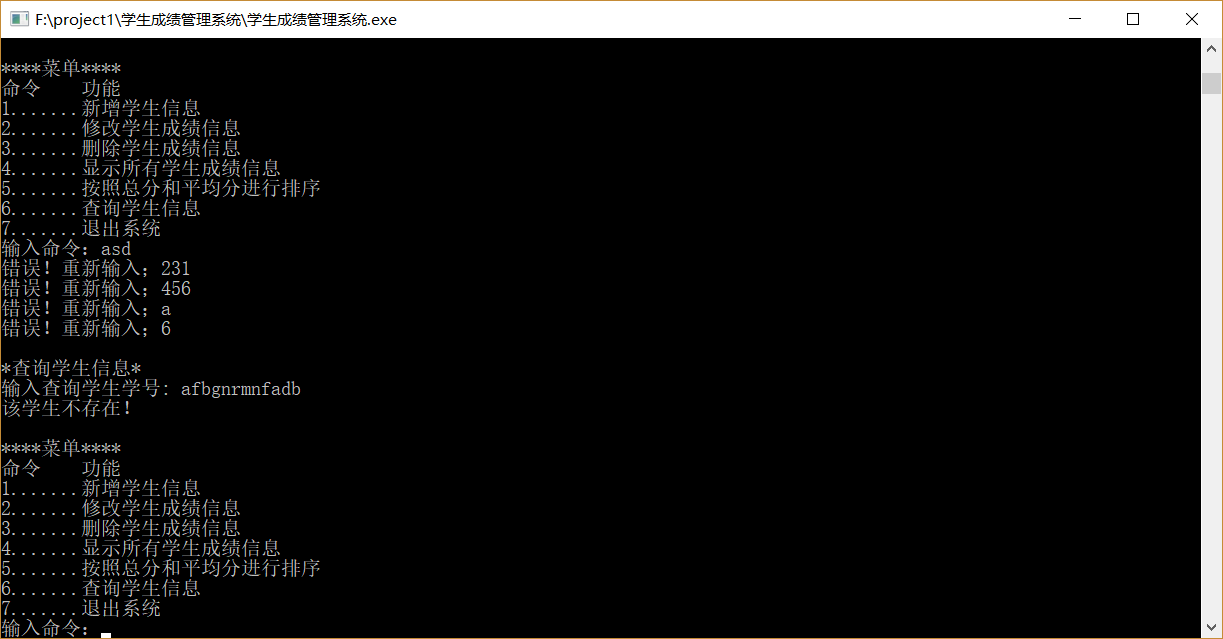
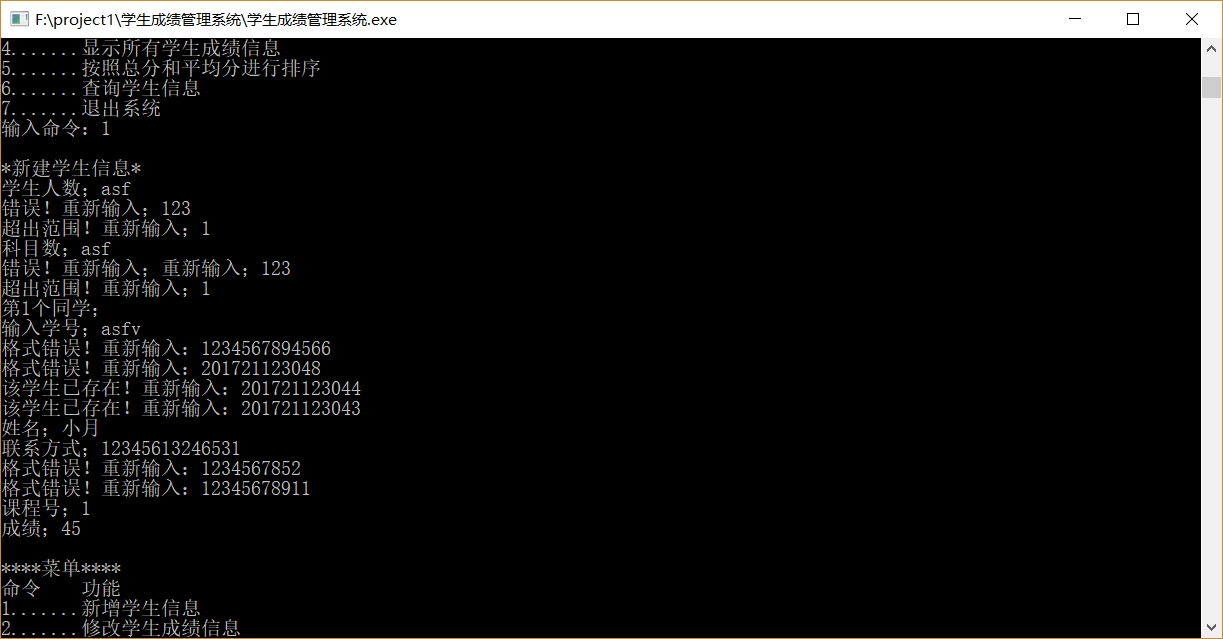
命令及学号非法输入
-
输入时学生人数越界(最多50,可调)、课程数越界(最多10,可调)、学号,电话非法输入、学号重复的情况
-
查询不到成绩
1.2.5 调试碰到问题及解决办法。
-
新增人数时已经输入的数据会被新的数据覆盖
解决方法:定义全局变量,所有函数共用,没输入一个数据时+1,新的数据在这个全局变量的数组上写入。 -
计算总分,平均分的问题
刚开始以为新增数据和修改数据时都要用到计算总分和平均分,于是打算把计算的过程写成函数,供他们调用,后来发现,新增和修改计算不太相同,不能用一台代码。还有就是计算平均分时,如果分母是0,计算结果会错误。
解决方法:函数count中只保留了计算输入时的代码,修改和删除后计算的代码则直接补到各自函数的后面。分母为0的情况就是补上了一句判断条件,当分母为0时,平均分直接等于0 -
调试健壮性的问题
输入命令的健壮性,一开始用%d吸收,但是输入字母或其他字符就会出现错误,改用%c吸收,万一有多余的字符则无法吸收
解决方法:%c吸收,加数组的吸收,而且用了gets,吸收彻底,在判断数组中是否吸收多余数据(这时为了保险,定义数组时要先赋予空字符串),及%c的正确性即可。
(除此之外还有许多问题,但是太多太杂,无法一一记录并罗列,当然程序写出后也还有一些潜在的问题还未发现)
二、截图本周题目集的PTA最后排名。

三、阅读代码
- 题目

- 代码
#include<stdio.h>
int N;
int s[31]; // 存放划分结果
int top = -1; // 数组指针
int count = 0; // 统计输出的次数
int sum = 0; // 拆分项累加和
void division (int i);
int main ()
{
scanf ("%d", &N);
division (1);
return 0;
}
void division (int i) {
if (sum == N) {
count ++;
printf("%d=", N);
int k;
for (k=0; k<top; k++) {
printf("%d+", s[k]);
}
if (count%4 == 0 || s[top] == N) {
printf("%d
", s[top]);
} else {
printf("%d;", s[top]);
}
return;
} // 输出部分
if (sum > N) {
return;
}
for (int j=i; j<=N; j++) {
s[++top] = j;
sum += j;
division (j);
sum -= j;
top --;
} // 算法主体
}
改代码用了深度优先处理的思想,简单说就是,不是去分解原来的数,而是从底层开始凑,直到凑到刚好等于给定的数,这种思考方法值得借鉴,有时从正向去分解可能很困难,这是可以试试逆向考虑。同时代码中连续定义的全局变量也给我的思路带来一点可能。
四、本周学习总结
1.总结本周学习内容。
1.宏定义:简单的替换,没有括号
格式:#define 宏名 字符串
用途:定义常量;带参数的宏来实现一些简单函数的功能
2.文件包含
格式:#include<文件名>或#include“文件名”
区别:#include<文件名>只会到系统文件夹中查找,不能用于自己所写的文件,#include“文件名”先到当前工作文件夹中查找,再到系统文件夹查找,一般用于自己写的头文件。
3.编译预处理
通过预编译生成程序,提高效率,均以#开头,常见预处理指令如#include、#define、#if····#else···#endif等
4.大程序构成
含主函数文件,头文件,及其他函数文件,分属不同模块,通过模块间交流实现大型功能。
模块间交流注意事项:
- 除头文件本身,其他文件都要加上包含该头文件。
- 头文件内部要包含全部函数原型定义和系统头文件,如标准输入输出。
- 其他模块引用主函数的全局变量时要加extern 变量名,说明它是外部变量。
5.指针进阶
设二维数组a【2】【3】
-
列指针:int *p;p=a;
* (p+i)表示离a【0】【0】第i个位置的元素 -
行指针:int (*p)【n】;p=a;
p+i表示a【i】;a【i】【j】=*(*(p+i)+j)=(*(p+i))【j】=p【i】【j】 -
指针数组:int *p【n】;int**p;p=pp;
p【i】是指针
2.罗列本周一些错题。

分析:*p[3]实际上是定义一个二级指针,而a[3]则定义了一个一级指针,所以a选项不同级指针不能赋值,b选项*p是一级指针,a[0]是元素不能赋值,c选项p是二级指针,&a[0]是一级指针不能赋值,所以d正确。
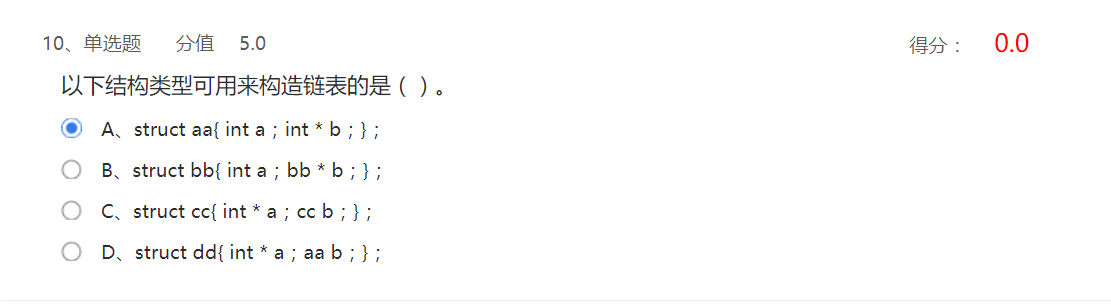
分析:必须有一个成员是指向结构的指针,只有b符合条件。