需求背景:
项目中需要定期执行任务A来做一些辅助的工作,A的执行需要在超时时间内完成,如果本次执行超时了,那就不对本次的执行结果进行处理(即放弃这次执行)。同时A又依赖B,C两个子任务的执行结果。B, C之间相互独立,可以并行的执行。但无论B,C哪一个执行失败或超时都会导致本次任务执行失败。
Groutine的并发控制:
go中对于groutine的并发控制有三种解决方案:
- 通过channel控制。
- 父groutine中声明无buffer的chan切片,向要开启的子groutine中传入切片中的一个chan
- 子groutine执行完成后向这个chan中写入数据(可以是和父groutine通信的也可以不是)
- 父groutine遍历所有chan并执行 <-chan 操作, 利用无buffer的channel只有读写同时准备好才能执行的特性进行控
- WaitGroup控制。
- 通过sync.Waitgroup, 每开启一个子groutine就执行 wg.Add(1), 子groutine内部执行wg.Done(), 父groutine通过wg.Wait()等待所有子协程
- Context控制。
- waitGroup和Context应该是Go中较为常用的两种并发控制。相较而言,context对于派生groutine有更强大的控制力,可以控制多级树状分布的groutine。
- 当然waitGroup的子groutine也可以再开启新的waitGroup并且等待多个孙groutine, 但是不如context的控制更加方便.
Context:
context包提供了四个方法创建不同类型的context
- WitchCancel()
- WithDeadline()
- WithTimeout()
- WithValue()
WithValue()主要用于通过context传递一些上下文消息,不在本次讨论中。WithTimeout和WithDeadLine几乎是一致的。但无论哪种,控制groutine都需要使用ctx.Done()方法. Done() 方法返回一个 "只读"的chan <-chan struct{}, 需要编写代码监听这个chan,一旦收到它的消息就说明这个context应当结束了,无论是到达了超时时间还是在某个地方主动cancel()了方法。
看看代码:
var ch1 chan int var ch2 chan int
// 任务A, 通过最外层的for来控制定期执行 func TestMe(t *testing.T) { ch1 = make(chan int, 0) ch2 = make(chan int, 0) count := 0 for { count ++ ctx, cancel := context.WithTimeout(context.Background(), time.Second * 2)
// 任务A的逻辑部分,开启子任务B, C。
// B,C通过ch1,ch2和A通信。
// 同时监听ctx.Done,如果超时了立即结束本次任务不继续执行 go func(ctx context.Context) { go g1(ctx, count) go g2(ctx, count) v1, v2 := -1, -1 for v1 == -1 || v2 == -1 { select { case <- ctx.Done(): cancel() fmt.Println("父级2超时退出,当前count值为", count, "当前时间:", time.Now()) return case v1 = <- ch1: case v2 = <- ch2: } } fmt.Println("正常执行完成退出, 开启下次循环,当前count值为:", count, "当前 v1: ", v1, "当前 v2: ", v2) }(ctx)
// 任务A监控ctx是否到达timeOUT,timeout就终止本次执行 select { case <- ctx.Done(): fmt.Println("父级1超时退出,当前count值为", count, "当前时间:", time.Now()) } time.Sleep(time.Second * 3) } }
// 改进后的任务B,即使计算出了结果,也不会再向ch1写数据了,不会造成脏数据 func g1 (ctx context.Context, num int) { fmt.Println("g1 num", num, "time", time.Now()) select { case <-ctx.Done(): fmt.Println("子级 g1关闭, 不向channel中写数据") return default: ch1 <- num } }
// 改进前的任务C func g2 (ctx context.Context, num int) { fmt.Println("g2 num", num, "time", time.Now()) ch2 <- num }
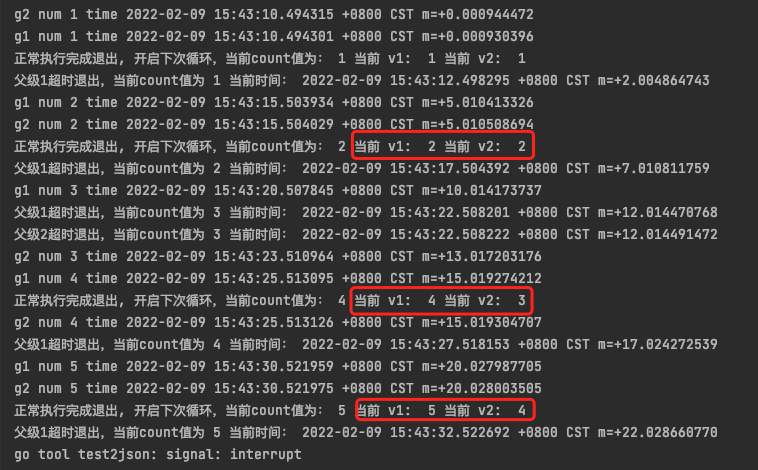
基于上述代码,子任务B, C的处理其实有一次较大的变动。一开始B,C都是类似于子任务C,即g2的这种写法。
这种写法在执行完成后就把自身的结果交给channel, 父groutine通过channel来读取数据,正常情况下也能工作。但异常情况下,如子任务B执行完成,子任务C(即g2)因为网络通信等原因执行了5s(超过context的最大时长), 就会出现比较严重的问题。到达超时时间后,A检测到了超时就自动结束了本次任务,但g2还在执行过程中。g2执行完成后向ch2写数据阻塞了(因为A已关闭,没有读取ch2的groutine)。下一个循环中A再次开启读取ch1与ch2, 实际上读取ch1是当次的结果,ch2是上次任务中g2返回的结果,导致两处依赖的数据源不一致。
模拟上述情况,将g2做了一些改动如下:
// 在第3次任务重等待3s, 使得它超时
func g2 (ctx context.Context, num int) { if num == 3 { time.Sleep(time.Second * 3) } fmt.Println("g2 num", num, "time", time.Now()) ch2 <- num }
实际上,如果想要通过context控制groutine, 一定要监控Done()方法。如g1所示。相同情况下A超时退出,C仍在执行。C执行完成后先检测Context是否已退出,如果已退出就不再向ch2中写入本次的数据了。(抛砖引玉了,也可能有更好的写法,希望大佬不吝赐教)
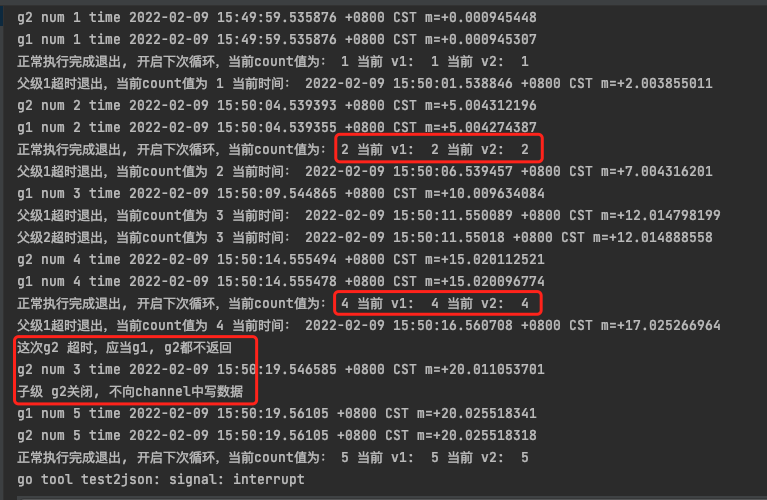
将g2改成和g1类似的写法后测试结果如下:
func g2 (ctx context.Context, num int) {
if num == 3 {
time.Sleep(time.Second * 10)
fmt.Println("这次g2 超时,应当g1, g2都不返回")
}
fmt.Println("g2 num", num, "time", time.Now())
select {
case <-ctx.Done():
fmt.Println("子级 g2关闭, 不向channel中写数据")
return
default:
ch2 <- num
}
}