本篇HDFS组件基于CDH5进行安装,安装过程:https://www.cnblogs.com/dmjx/p/10037066.html
角色分布
hdp02.yxdev.wx:HDFS server
hdp03.yxdev.wx:HDFS agent
hdp04.yxdev.wx:HDFS agent
相关路径
组件最后的安装目录:/opt/cloudera/parcels/CDH/etc/
webUI:http://hdp02.yxdev.wx:50070
传输端口:http://hdp02.yxdev.wx:9000
hdfs简介
hdfs是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件,并且是分布式的,由很多服务器联合起来实现其功能,集群中的服务器各自负责角色
重要特征
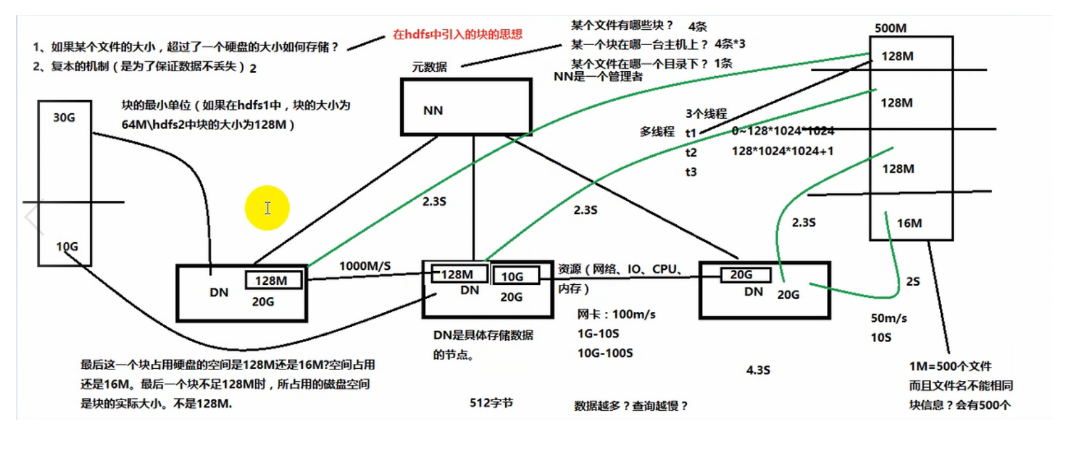
1. HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
2. HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
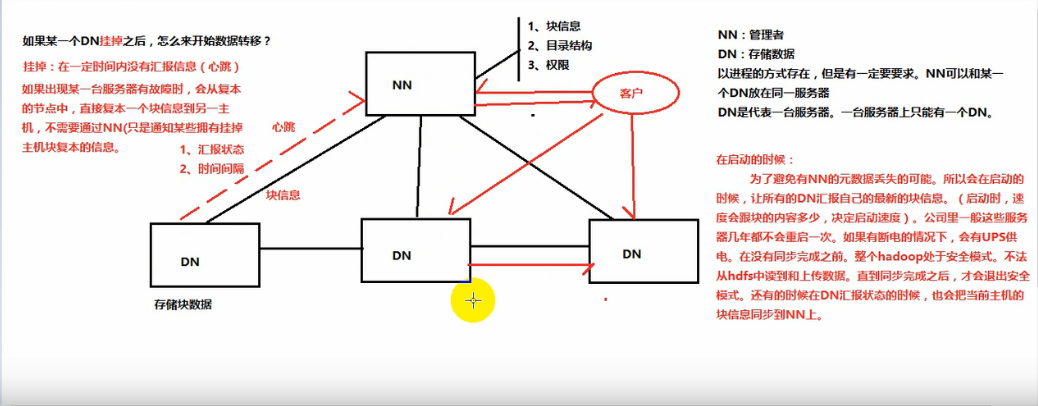
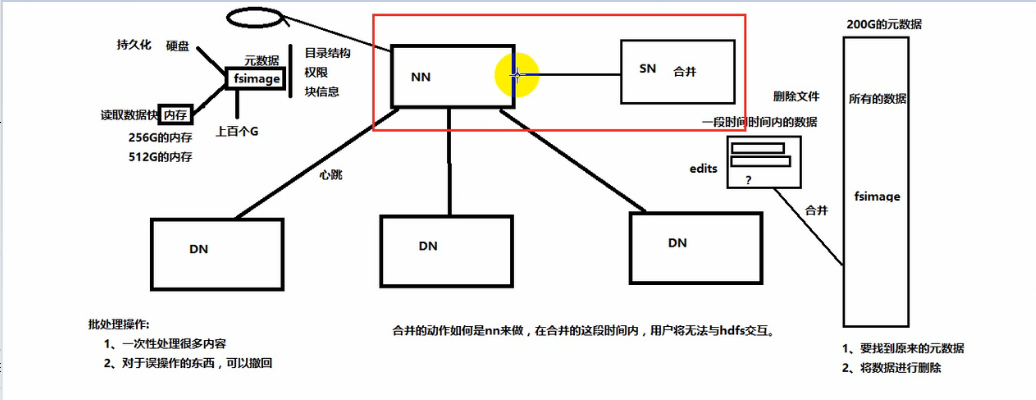
3. 目录结构及文件分块信息(元数据)的管理由namenode节点承担——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
4. 文件的各个block的存储管理由datanode节点承担---- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
5. HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
hdfs相关概念
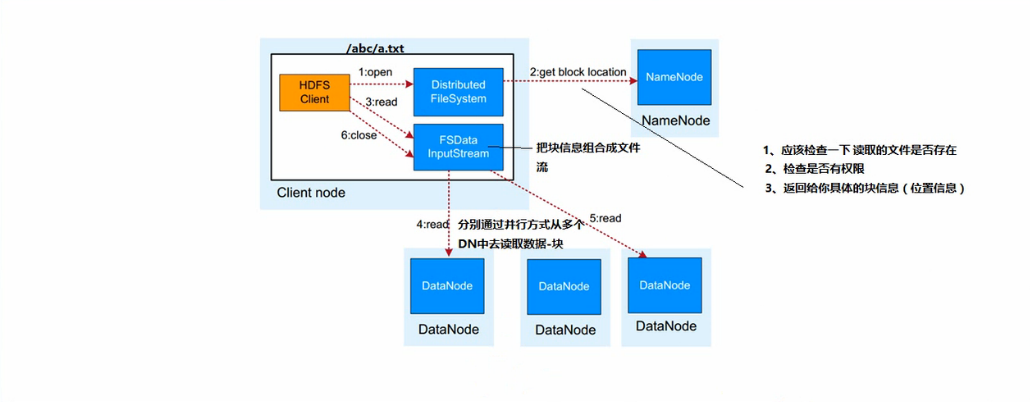
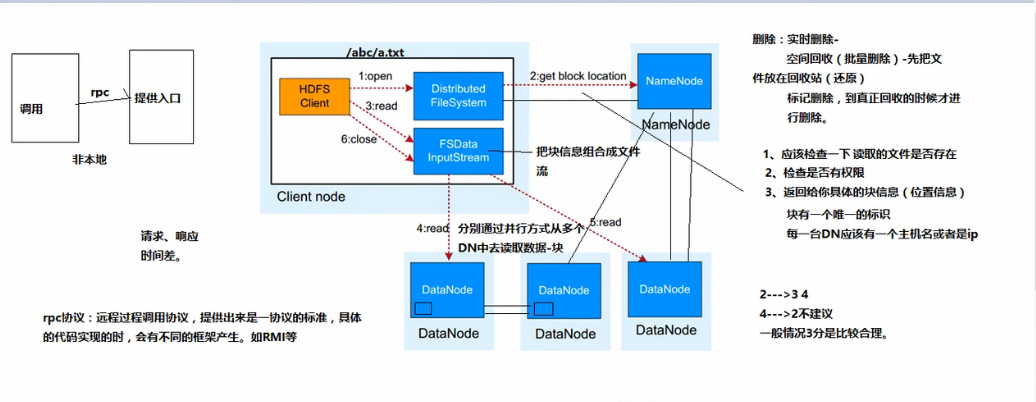
hdfs数据读取流程:
1. 业务应用调用HDFS Client提供API的打开文件
2. HDFS Client联系NameNode,获得文件信息(数据块、DataNode位置信息)
3. 业务应用调用read API读取文件
4. HDFS Client根据从NameNode获取到的信息,联系DataNode,获取相应为数据块。(Client采用就近原则读取数据)
5. HDFS Client会与多个DataNode通讯获取数据块
6. 读取完成后,业务调用close关闭连接
图(1)
图(2)
HDFS设计架构及设计要点说明
统一的文件系统名字空间(元数据):hdfs对外仅呈现一个统一的文件系统
同意的通讯协议:统一采用RPC方式通信,NameNode被动接收Client,DataNode的RPC请求
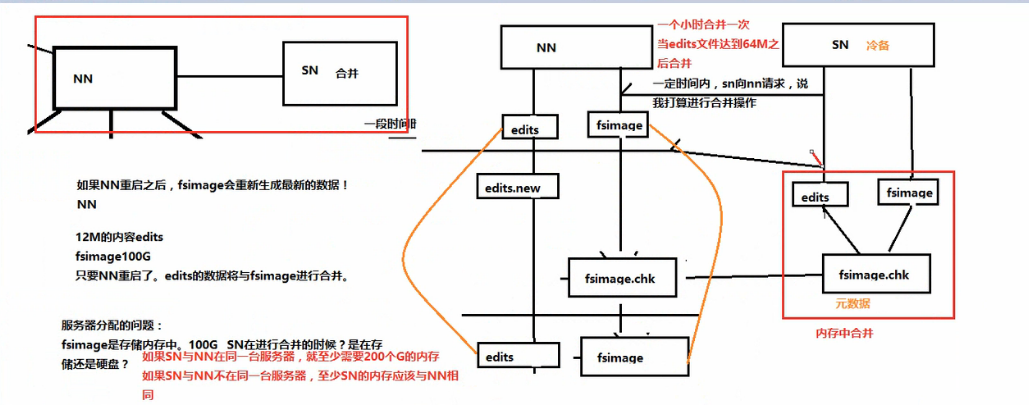
空间回收机制:支持回收站机制,以及副本数的动态设置机制
数据组织:数据存储以数据块为单位,存储在操作系统的文件系统上
访问方式:提供JAVA API,HTTP,SHELL方式访问HDFS数据。

重启hdfs遇到的坑
格式化数据,最好别瞎动:hdfs namenode -format
由于我本次是使用cloudera安装,所以起停都需要再网页操作
但是重启的时候会出现未完全杀死namenode
ps aux | grep namenode
或者不小心改变了/dfs/nn/...的属组,需要改回去
当重启了namenode后,VERSION文件中的clusterID数值会跟着改变,在重启datanode的时候需要将对应的次数值进行改动(改成一样的)