1、基本操作模式
awk 'BEGIN{ print "start" } pattern{ commands } END{ print "end" }' file
一个awk脚本通常由:BEGIN语句块、能够使用模式匹配的通用语句块、END语句块3部分组成,这三个部分是可选的。任意一个部分都可以不出现在脚本中,脚本通常是被单引号或双引号中,例如:
awk 'BEGIN{ i=0 } { i++ } END{ print i }' filename awk "BEGIN{ i=0 } { i++ } END{ print i }" filename
2、工作原理:
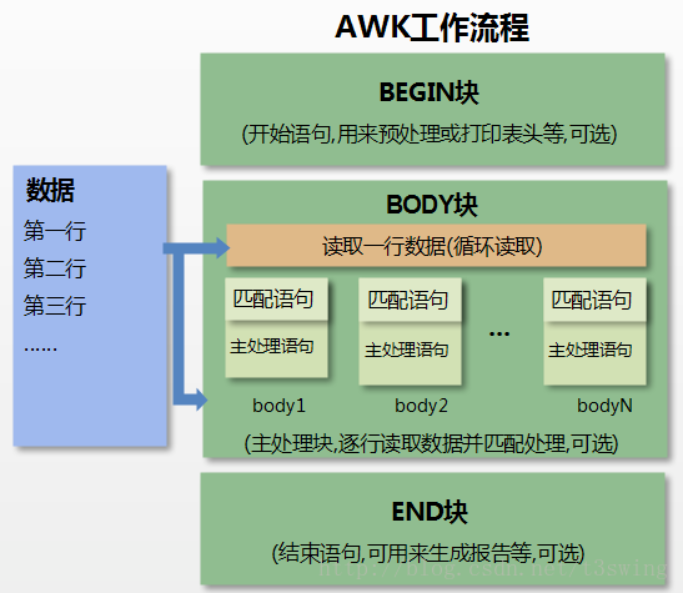
awk 'BEGIN{ commands } pattern{ commands } END{ commands }'
- 第一步:执行
BEGIN{ commands }语句块中的语句; - 第二步:从文件或标准输入(stdin)读取一行,然后执行
pattern{ commands }语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。 - 第三步:当读至输入流末尾时,执行
END{ commands }语句块。
BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中。
END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块。
pattern语句块中的通用命令是最重要的部分,它也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块。
实例:
echo -e "A line 1 A line 2" | awk 'BEGIN{ print "Start" } { print } END{ print "End" }'
当使用不带参数的print时,它就打印当前行,当print的参数是以逗号进行分隔时,打印时则以空格作为定界符。在awk的print语句块中双引号是被当作拼接符使用,例如:
echo | awk '{ var1="v1"; var2="v2"; var3="v3"; print var1,var2,var3; }' v1 v2 v3
双引号拼接使用:
echo | awk '{ var1="v1"; var2="v2"; var3="v3"; print var1"="var2"="var3; }' v1=v2=v3
{ }类似一个循环体,会对文件中的每一行进行迭代,通常变量初始化语句(如:i=0)以及打印文件头部的语句放入BEGIN语句块中,将打印的结果等语句放在END语句块中。
3、AWK的内置变量
说明:[A][N][P][G]表示第一个支持变量的工具,[A]=awk、[N]=nawk、[P]=POSIXawk、[G]=gawk
$n 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
$0 这个变量包含执行过程中当前行的文本内容。
[N] ARGC 命令行参数的数目。
[G] ARGIND 命令行中当前文件的位置(从0开始算)。
[N] ARGV 包含命令行参数的数组。
[G] CONVFMT 数字转换格式(默认值为%.6g)。
[P] ENVIRON 环境变量关联数组。
[N] ERRNO 最后一个系统错误的描述。
[G] FIELDWIDTHS 字段宽度列表(用空格键分隔)。
[A] FILENAME 当前输入文件的名。
[P] FNR 同NR,但相对于当前文件。
[A] FS 字段分隔符(默认是任何空格)。
[G] IGNORECASE 如果为真,则进行忽略大小写的匹配。
[A] NF 表示字段数,在执行过程中对应于当前的字段数。
[A] NR 表示记录数,在执行过程中对应于当前的行号。
[A] OFMT 数字的输出格式(默认值是%.6g)。
[A] OFS 输出字段分隔符(默认值是一个空格)。
[A] ORS 输出记录分隔符(默认值是一个换行符)。
[A] RS 记录分隔符(默认是一个换行符)。
[N] RSTART 由match函数所匹配的字符串的第一个位置。
[N] RLENGTH 由match函数所匹配的字符串的长度。
[N] SUBSEP 数组下标分隔符(默认值是34)。
实例:
echo -e "line1 f2 f3nline2 f4 f5nline3 f6 f7" | awk '{print "Line No:"NR", No of fields:"NF, "$0="$0, "$1="$1, "$2="$2, "$3="$3}' Line No:1, No of fields:3 $0=line1 f2 f3 $1=line1 $2=f2 $3=f3 Line No:2, No of fields:3 $0=line2 f4 f5 $1=line2 $2=f4 $3=f5 Line No:3, No of fields:3 $0=line3 f6 f7 $1=line3 $2=f6 $3=f7
使用print $NF可以打印出一行中的最后一个字段,使用$(NF-1)则是打印倒数第二个字段,其他以此类推:
echo -e "line1 f2 f3n line2 f4 f5" | awk '{print $NF}' f3 f5 echo -e "line1 f2 f3n line2 f4 f5" | awk '{print $(NF-1)}' f2 f4
打印每一行的第二和第三个字段:
awk '{ print $2,$3 }' filename
统计文件中的行数:
awk 'END{ print NR }' filename
以上命令只使用了END语句块,在读入每一行的时,awk会将NR更新为对应的行号,当到达最后一行NR的值就是最后一行的行号,所以END语句块中的NR就是文件的行数。
4、将外部变量值传递给awk
借助-v选项,可以将外部值(并非来自stdin)传递给awk:
VAR=10000 echo | awk -v VARIABLE=$VAR '{ print VARIABLE }'
5、awk处理gff
awk '{if($3=="gene"|| $3=="CDS"){print $0}else if($3=="mRNA"){split($9,a,";");print $1" "$2" "$3" "$4" "$5" "$6" "$7" "$8" "a[1]";"a[2]}else if($3=="exon"){split($9,b,";");print $1" "$2" "$3" "$4" "$5" "$6" "$7" "$8" "b[1]";"b[4]}}' lishu.stringtie.gff3 | awk '$3!="gene" && $3!="exon"' > lishu.filter.gff3
6、awk转置文件
awk BEGIN{RS=EOF}'{gsub(/ /," ");print}' species.list