基于Python的文件、目录和路径操作,我们一般使用的是os.path模块。
pathlib是它的替代品,在os.path上的基础上进行了封装,实现了路径的对象化,api更加通俗,操作更便捷,更符编程的思维习惯。
pathlib模块提供了一些使用语义化表示文件系统路径的类,这些类适合多种操作系统。路径类被划分为纯路径(该路径提供了不带I/O的纯粹计算操作),以及具体路径(从纯路径中继承而来,但提供了I/O操作)。
首先我们看一下pathlib模块的组织结构,其核心是6个类,这6个类的基类是PurePath类,其它5个类都是从它派生出来的:
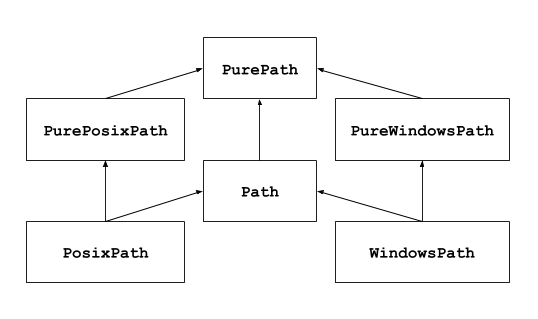
箭头连接的是有继承关系的两个类,以 PurePosixPath 和 PurePath 类为例,PurePosixPath 继承自 PurePath,即前者是后者的子类。
- PurePath 类:将路径看做是一个普通的字符串,它可以实现将多个指定的字符串拼接成适用于当前操作系统的路径格式,同时还可以判断任意两个路径是否相等。从英文名来理解,Pure是纯粹的意思,表示PurePath类纯粹只关心路径的操作,而不管真实文件系统中路径是否有效、文件是否存在、目录是否存在等现实问题。
- PurePosixPath 和 PureWindowsPath 是 PurePath 的子类,前者用于操作 UNIX(包括 Mac OS X)风格操作系统的路径,后者用于操作 Windows 操作系统的路径。我们都知道两种风格的操作系统在路径分隔符上有一定的区别。
- Path 类和以上 3 个类不同,在操作路径的同时,还能操作文件/目录,并和真实的文件系统交互,例如判断路径是否真实存在。
- PosixPath 和 WindowsPath 是 Path 的子类,分别用于操作 Unix(Mac OS X)风格的路径和 Windows 风格的路径。
PurePath、PurePosixPath 和 PureWindowsPath这三个纯路径类通常用在一些特殊的情况里,如:
-
如果你需要在Unix设备里操作Windows路径,或在Windiws设备里操作Unix路径。因为我们不能在Unix上实例化一个真正的Windows路径,但我们可以实例化一个纯Windows路径,假装我们在操作windows。
-
你想要确保你的代码只操作路径而不和操作系统真实交互。
科普:UNIX 类型的操作系统和 Windows 操作系统上,路径的格式是完全不同的,主要区别在于根路径和路径分隔符,UNIX 系统的根路径是斜杠(/),而 Windows 系统的根路径是盘符(C:);UNIX 系统路径使用的分隔符是正斜杠(/),而 Windows 使用的是反斜杠()。
一、PurePath类
PurePath 类(以及 PurePosixPath 类和 PureWindowsPath 类)都提供了大量的构造方法、实例方法以及类实例属性供我们使用。
在实例化 PurePath 类时,会自动适配操作系统。如果在 UNIX 或 Mac OS X 系统中,构造方法实际返回的是 PurePosixPath 对象;反之,如果在 Windows 系统上使用 PurePath 创建实例,构造方法返回的是 PureWindowsPath 对象。
例如,在 Windows 系统中执行如下语句:
from pathlib import PurePath
path = PurePath('file.txt')
print(type(path))
# <class 'pathlib.PureWindowsPath'>
PurePath 在创建对象时,也支持传入多个路径字符串,它们会被拼接成一个路径。例如:
from pathlib import PurePath
path = PurePath('https:','www.liujiangblog.com','django')
print(path)
# https:www.liujiangblog.comdjango
可以看到,由于运行环境为 Windows 擦奥做系统,因此输出的是 Windows 平台格式的路径。
如果想在 Windows 中创建 UNIX 风格的路径,就需要指定使用 PurePosixPath 类,反之亦然。例如:
from pathlib import PurePosixPath
path = PurePosixPath('https:','www.liujiangblog.com','django')
print(path)
# https:/www.liujiangblog.com/django
强调:在做纯路径操作的时候,其实玩弄的都是字符串,与本地文件系统没有任何实际关联,不做任何磁盘IO操作。PurePath构造的路径本质上是字符串,完全可以使用
str()将 其转换成字符串。
此外,如果在使用 PurePath 类的构造方法时,不传入任何字符串参数,则等相当于传入点.(当前路径)作为参数:
from pathlib import PurePath
path1 = PurePath()
path2 = PurePath('.')
print(path1 == path2)
# True
如果传入 PurePath 构造方法中的多个参数中,包含多个根路径,则只会有最后一个根路径及后面的子路径生效。例如:
from pathlib import PurePath
path = PurePath('C:/', 'D:/', 'file.txt')
print(path)
# D:file.txt
额外提醒,在Python中构造字符串的时候,一定要注意正/反斜杠在转义和不转义时的区别。以及r原生字符串的使用和不使用。千万不要写错了
如果传给 PurePath 构造方法的参数中包含有多余的斜杠或者.会直接被忽略,但..不会被忽略:
from pathlib import PurePath
path = PurePath('C:/./..file.txt')
print(path)
# C:..file.txt
PurePath 实例支持比较运算符,对于同种风格的路径,可以判断是否相等,也可以比较大小(实际上就是比较字符串的大小);对于不同风格的路径,只能判断是否相等(显然,不可能相等),但不能比较大小:
from pathlib import *
# Unix风格的路径区分大小写
print(PurePosixPath('/D/file.txt') == PurePosixPath('/d/file.txt'))
# Windows风格的路径不区分大小写
print(PureWindowsPath('D://file.txt') == PureWindowsPath('d://file.txt'))
# False
# True
下面列出PurePath实例常用的方法和属性:
| 实例属性和方法 | 功能描述 |
|---|---|
| PurePath.parts | 返回路径字符串中所包含的各部分。 |
| PurePath.drive | 返回路径字符串中的驱动器盘符。 |
| PurePath.root | 返回路径字符串中的根路径。 |
| PurePath.anchor | 返回路径字符串中的盘符和根路径。 |
| PurePath.parents | 返回当前路径的全部父路径。 |
| PurPath.parent | 返回当前路径的上一级路径,相当于 parents[0] 的返回值。 |
| PurePath.name | 返回当前路径中的文件名。 |
| PurePath.suffixes | 返回当前路径中的文件所有后缀名。 |
| PurePath.suffix | 返回当前路径中的文件后缀名。也就是 suffixes 属性列表的最后一个元素。 |
| PurePath.stem | 返回当前路径中的主文件名。 |
| PurePath.as_posix() | 将当前路径转换成 UNIX 风格的路径。 |
| PurePath.as_uri() | 将当前路径转换成 URL。只有绝对路径才能转换,否则将会引发 ValueError。 |
| PurePath.is_absolute() | 判断当前路径是否为绝对路径。 |
| PurePath.joinpath(*other) | 将多个路径连接在一起,作用类似于前面介绍的斜杠(/)连接符。 |
| PurePath.match(pattern) | 判断当前路径是否匹配指定通配符。 |
| PurePath.relative_to(*other) | 获取当前路径中去除基准路径之后的结果。 |
| PurePath.with_name(name) | 将当前路径中的文件名替换成新文件名。如果当前路径中没有文件名,则会引发 ValueError。 |
| PurePath.with_suffix(suffix) | 将当前路径中的文件后缀名替换成新的后缀名。如果当前路径中没有后缀名,则会添加新的后缀名。 |
二、Path类
更多的时候,我们都是直接使用Path类,而不是PurePath。
Path 是 PurePath 的子类, 除了支持 PurePath 提供的各种构造函数、属性及方法之外,还提供判断路径有效性的方法,甚至还可以判断该路径对应的是文件还是文件夹,如果是文件,还支持对文件进行读写等操作。
Path 有 2 个子类,分别为 PosixPath和 WindowsPath,这两个子类的作用显而易见,不再赘述。
基本使用
from pathlib import Path
# 创建实例
p = Path('a','b','c/d')
p = Path('/etc')
-------------------------------------------------------
p = Path()
# WindowsPath('.')
p.resolve() # 解析路径,不一定是真实路径
# WindowsPath('C:/Users/liujiangblog')
--------------------------------------------------
# 任何时候都返回当前的真实的绝对路径
p.cwd()
# WindowsPath('D:/work/2020/django3')
Path.cwd()
# WindowsPath('D:/work/2020/django3')
p.home()
# WindowsPath('C:/Users/liujiangblog')
Path.home()
# WindowsPath('C:/Users/liujiangblog')
目录操作
p = Path(r'd: est1122')
p.mkdir(exist_ok=True) # 创建文件目录(前提是tt目录存在, 否则会报错)
# 一般我会使用下面这种创建方法
p.mkdir(exist_ok=True, parents=True) # 递归创建文件目录
p.rmdir() #删除当前目录,但是该目录必须为空
p
# WindowsPath('d:/test/11/22') p依然存在
遍历目录
p = Path(r'd: est')
# WindowsPath('d:/test')
p.iterdir() # 相当于os.listdir
p.glob('*') # 相当于os.listdir, 但是可以添加匹配条件
p.rglob('*') # 相当于os.walk, 也可以添加匹配条件
创建文件
file = Path(r'd: est1122 est.py')
file.touch() # touch方法用于创建空文件,目录必须存在,否则无法创建
#Traceback (most recent call last):
# File "<input>", line 1, in <module>
# .....
#FileNotFoundError: [Errno 2] No such file or directory: 'd:\test\11\22\test.py'
p = Path(r'd: est1122')
p.mkdir(exist_ok=True,parents=True)
file.touch()
file.exists()
# True
file.rename('33.py') # 文件重命名或者移动
#Traceback (most recent call last):
# File "<pyshell#4>", line 1, in <module>
# file.rename('33.py')
# File "C:Program FilesPython38libpathlib.py", line 1353, in rename
# self._accessor.rename(self, target)
#PermissionError: [WinError 5] 拒绝访问。: 'd:\test\11\22\test.py' -> '33.py'
file.rename(r'd: est112233.py')
# WindowsPath('d:/test/11/22/33.py')
文件操作
p = Path(r'd: est t.txt.bk')
p.name # 获取文件名
# tt.txt.bk
p.stem # 获取文件名除后缀的部分
# tt.txt
p.suffix # 文件后缀
# .bk
p.suffixs # 文件的后缀们...
# ['.txt', '.bk']
p.parent # 相当于dirnanme
# WindowsPath('d:/test')
p.parents # 返回一个iterable, 包含所有父目录
# <WindowsPath.parents>
for i in p.parents:
print(i)
# d: est
# d:
p.parts # 将路径通过分隔符分割成一个元组
# ('d:\', 'test', 'tt.txt.bk')
p = Path('C:/Users/Administrator/Desktop/')
p.parent
# WindowsPath('C:/Users/Administrator')
p.parent.parent
# WindowsPath('C:/Users')
# 索引0是直接的父目录,索引越大越接近根目录
for x in p.parents: print(x)
# C:UsersAdministrator
# C:Users
# C:
# 更多技术文章请访问官网https://www.liujiangblog.com
# with_name(name)替换路径最后一部分并返回一个新路径
Path("/home/liujiangblog/test.py").with_name('python.txt')
# WindowsPath('/home/liujiangblog/python.txt')
# with_suffix(suffix)替换扩展名,返回新的路径,扩展名存在则不变
Path("/home/liujiangblog/test.py").with_suffix('.txt')
# WindowsPath('/home/liujiangblog/test.txt')
文件信息
p = Path(r'd: est t.txt')
p.stat() # 获取详细信息
# os.stat_result(st_mode=33206, st_ino=562949953579011, st_dev=3870140380, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1525254557, st_mtime=1525254557, st_ctime=1525254557)
p.stat().st_size # 文件大小
# 0
p.stat().st_ctime # 创建时间
# 1525254557.2090347
# 其他的信息也可以通过相同方式获取
p.stat().st_mtime # 修改时间
文件读写
open(mode='r', bufferiong=-1, encoding=None, errors=None, newline=None)
使用方法类似Python内置的open函数,返回一个文件对象。
p = Path('C:/Users/Administrator/Desktop/text.txt')
with p.open(encoding='utf-8') as f:
print(f.readline())
read_bytes():以'rb'模式读取文件,并返回bytes类型数据
write_bytes(data): 以'wb'方式将数据写入文件
p = Path('C:/Users/Administrator/Desktop/text.txt')
p.write_bytes(b'Binary file contents')
# 20
p.read_bytes()
# b'Binary file contents'
read_text(encoding=None, errors=None): 以'r'方式读取路径对应文件,返回文本
write_text(data, encoding=None, errors=None):以'w'方式写入字符串到路径对应文件
p = Path('C:/Users/Administrator/Desktop/text.txt')
p.write_text('Text file contents')
# 18
p.read_text()
# 'Text file contents'
判断操作
返回布尔值
- is_dir() :是否是目录
- is_file() :是否是普通文件
- is_symlink() :是否是软链接
- is_socket(): 是否是socket文件
- is_block_device(): 是否是块设备
- is_char_device(): 是否是字符设备
- is_absolute() :是否是绝对路径
p = Path(r'd: est')
p = Path(p, 'test.txt') # 字符串拼接
p.exists() # 判断文件是否存在
p.is_file() # 判断是否是文件
p.is_dir() # 判断是否是目录
路径拼接和分解
在pathlib中,通过拼接操作符/来拼接路径,主要有三种方式:
- Path对象 / Path对象
- Path对象 / 字符串
- 字符串 / Path对象
分解路径主要通过parts方法
p=Path()
p
# WindowsPath('.')
p = p / 'a'
p
# WindowsPath('a')
p = 'b' / p
p
# WindowsPath('b/a')
p2 = Path('c')
p = p2 / p
p
# WindowsPath('c/b/a')
p.parts
# ('c', 'b', 'a')
p.joinpath("c:","liujiangblog.com","jack") # 拼接的时候,前面部分被忽略了
# WindowsPath('c:liujiangblog.com/jack')
# 更多技术文章请访问官网https://www.liujiangblog.com
通配符
- glob(pattern): 通配给定的模式
- rglob(pattern) :通配给定的模式,并且递归搜索目录
返回值: 一个生成器
p=Path(r'd:vue_learn')
p.glob('*.html') # 匹配所有HTML文件,返回的是一个generator生成器
# <generator object Path.glob at 0x000002ECA2199F90>
list(p.glob('*.html'))
# [WindowsPath('d:/vue_learn/base.html'), WindowsPath('d:/vue_learn/components.html'), WindowsPath('d:/vue_learn/demo.html').........................
g = p.rglob('*.html') # 递归匹配
next(g)
# WindowsPath('d:/vue_learn/base.html')
next(g)
# WindowsPath('d:/vue_learn/components.html')
正则匹配
使用match方法进行模式匹配,成功则返回True
p = Path('C:/Users/Administrator/Desktop/text.txt')
p.match('*.txt')
# True
Path('C:/Users/Administrator/Desktop/text.txt').match('**/*.txt')
# True