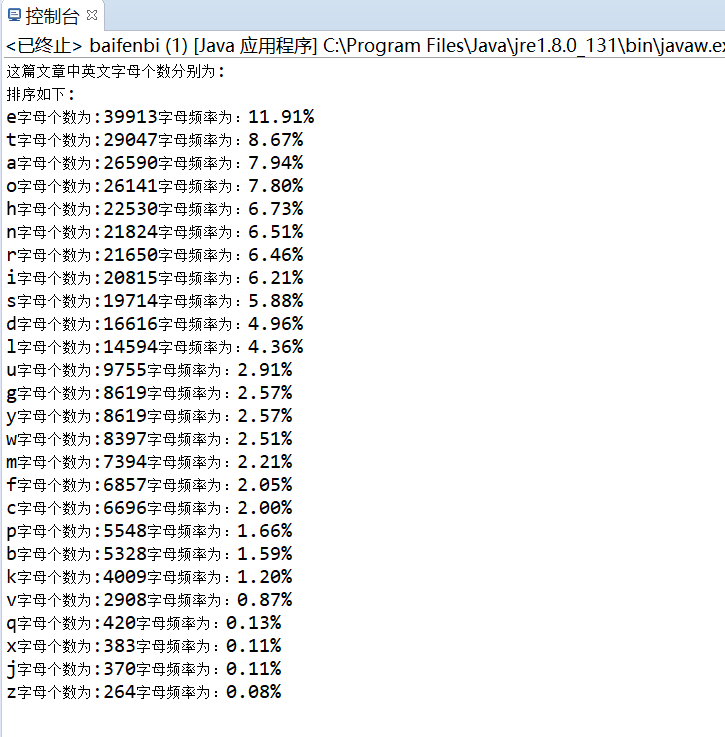
一.统计所给出文件中英文字母出现的频率(区分大小写),并且按着出现频率倒序输出
将文件用BufferedReader读取;
对每行进行读取在进行分割成单词;
对单词进行循环判断是否在A-Z,a-z之间,若在存储到数组里计数.
package li; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStreamReader; import java.text.DecimalFormat; import java.util.ArrayList; import java.util.List; public class baifenbi { public static void main(String[] args)throws IOException //IOException用来读写数据 { List<Integer> list=new ArrayList<>(); //定义一个integer类型的list变量 DecimalFormat df=new DecimalFormat("######0.00"); //格式化十进制数字 FileInputStream fip = new FileInputStream ("C:\\Users\\28681\\Desktop\\Harry Potter and the Sorcerer's Stone.txt"); //导入文件 InputStreamReader reader = new InputStreamReader(fip, "gbk"); //从字节流到字符流的桥接器 StringBuffer sb = new StringBuffer(); while (reader.ready()) { sb.append((char) reader.read()); } reader.close(); fip.close(); int i; String A=sb.toString(); String M="abcdefghijklmnopqrstuvwxyz"; String temp = ""; char NUM[]=new char[A.length()]; char Z[]=new char[26]; int X[]=new int[26]; int MAX=0; Z=M.toCharArray(); for(int k=0;k<26;k++) { X[k]=0; for(i=0;i<A.length();i++) { NUM[i]=A.charAt(i); if(Z[k]==NUM[i]||Z[k]==ch(NUM[i])) { X[k]++; } } } System.out.println("这篇文章中英文字母个数分别为:"); double sum=0; System.out.println("排序如下:"); for(i=0;i<25;i++) for(int k=0;k<25-i;k++) { if(X[k]<X[k+1]) { int temp2=X[k]; X[k]=X[k+1]; X[k+1]=temp2; char temp3=Z[k]; Z[k]=Z[k+1]; Z[k+1]=temp3; } } for(i=0;i<26;i++) { sum=sum+X[i]; } for(i=0;i<26;i++) { double jkl=(X[i])/sum*100; System.out.println(Z[i]+"字母个数为:"+X[i]+"字母频率为:"+df.format(jkl)+"%"); } } static char ch(char c) { if(!(c>=97&&c<=122)) c+=32; return c; } }
二、输出单个文件的前N个最常出现的英文单词
package com.wenjian;
import java.io.File;
import java.util.Scanner;
import java.io.FileNotFoundException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
public class nword {
public static <type> void main (String[] args) throws FileNotFoundException {
File file=new File("E:\\Harry Potter and the Sorcerer's Stone.txt");
if(!file.exists()){
System.out.println("未找到文件");
return;
}
Scanner in=new Scanner(System.in);
System.out.println("请输入前n个常用单词");
int n=in.nextInt();
Scanner scanner=new Scanner(file);
HashMap<String,Integer> hashMap=new HashMap<String,Integer>();
while(scanner.hasNextLine()) {
String line=scanner.nextLine();
String[] lineWords=line.split(" ");
Set<String> wordSet=hashMap.keySet();
for(int i=0;i<lineWords.length;i++) {
if(wordSet.contains(lineWords[i])) {//判断set集合里是否有该单词
Integer number=hashMap.get(lineWords[i]);//若有次数+1
number++;
hashMap.put(lineWords[i], number);
}
else {//没有就将其放入set里,次数为1
hashMap.put(lineWords[i], 1);
}
}
}
//计算总体单词数
int sum=0;
Iterator<String> it=hashMap.keySet().iterator();
while(it.hasNext()){
sum+=hashMap.get(it.next());
}
//输出前n个单词
while(n>0)
{
Iterator<String> iterator=hashMap.keySet().iterator();
int max=0;
String maxword=null;
while(iterator.hasNext()){
String word=iterator.next();
if(hashMap.get(word)>max) {
max=hashMap.get(word);
maxword=word;
}
}
hashMap.remove(maxword);
double ans=max*1.0/sum*100;
if(!maxword.equals("")) {
System.out.println(maxword+":"+max);
n--;
}
}
}
}