做过自动化测试的同学大概都selenium这个模块都比较熟悉,这是一个web端的自动化测试工具,可以模拟人的操作来进行网页自动化,那如何用它来做网络爬虫呢?其实利用requests+bs4就可以编写大多数的爬虫,但是,如果某些网站的请求URl是加密的(比如gmail),那可以通过模拟正常的人工操作来登录,获取页面的元素信息来爬取数据。
继续拿http://www.kingdee.com/news/tag/%E4%BA%91%E4%B9%8B%E5%AE%B6/这个网址,来爬区其中的信息

首先,编写进入改网址的自动化代码
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('http://www.kingdee.com/news/tag/%E4%BA%91%E4%B9%8B%E5%AE%B6/')
进入网址后有两种方法可以获取我们要的数据:
1.利用driver.page_source来获取整个页面的html代码,再用bs4来解析,这个方法可以参考我之前那篇文章
2.在该网页中编写javaScript代码,利用DOM对象来获取信息,方法是这个driver.execute_script(js代码),该方法比较简便,前提是你要了解javaScript
我们选择第二种(第一种已经在上一篇文章中介绍了),先来分析下网页,F12查看:
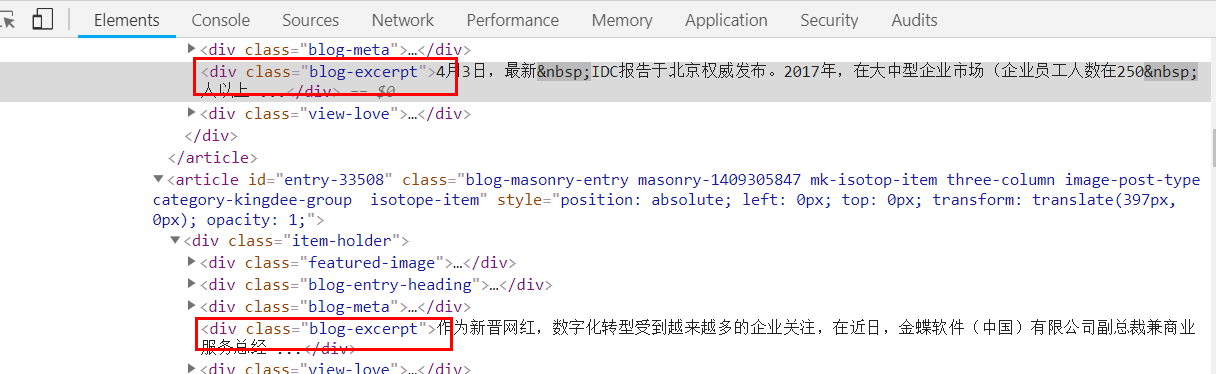
我们可以发现我们需要的内容都在div这个标签下,并且它的class为blog-excerpt,可以针对这个特性我们编写代码:
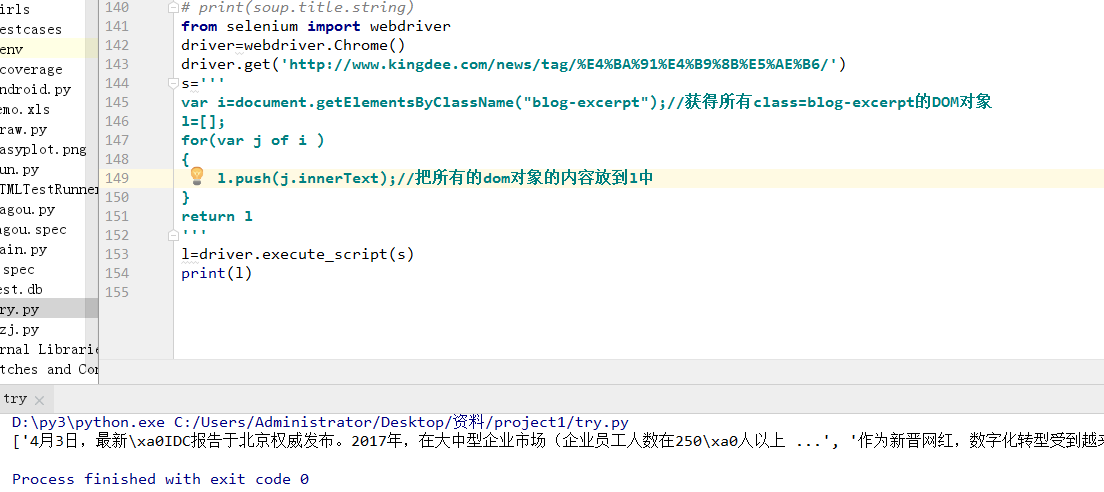
注意我们把需要返回的内容放在return之后,是不是比用bs去解析简单多了呢