一、序言
NoSQL是Not Only SQL的缩写,而不是Not SQL,指的是非关系型的数据库,它不一定遵循传统数据库的一些基本要求,比如说遵循SQL标准、ACID属性、表结构等等。相比传统数据库,叫它分布式数据管理系统更贴切,数据存储被简化更灵活,重点被放在了分布式数据管理上。
随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
二、大数据时代
随着互联网 web2.0 网站的兴起,非关系型的数据库成了一个极其热门的新领域,非关系数据库产品的发展非常迅速。而传统的关系数据库在应付 web2.0 网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题:
1、High performance - 对数据库高并发读写的需求
web2.0 网站要根据用户个性化信息来实时生成动态页面和提供动态信息,所以基本上无法使用动态页面静态化技术,因此数据库并发负载非常高,往往要达到每秒上万次读写请求。关系数据库应付上万次SQL查询还勉强顶得住,但是应付上万次SQL写数据请求,硬盘IO就已经无法承受了。其实对于普通的BBS网站,往往也存在对高并发写请求的需求。
2、Huge Storage - 对海量数据的高效率存储和访问的需求
对于大型的SNS网站,每天用户产生海量的用户动态,以国外的Friendfeed为例,一个月就达到了2.5亿条用户动态,对于关系数据库来说,在一张2.5亿条记录的表里面进行SQL查询,效率是极其低下乃至不可忍受的。
3、High Scalability && High Availability- 对数据库的高可扩展性和高可用性的需求
在基于web的架构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,你的数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移,为什么数据库不能通过不断的添加服务器节点来实现扩展呢?
三、关系数据库的瓶颈
1.数据结构化,数据的横向扩展能力底下。
(1)受业务规则影响,需求变动导致分库分表的维护复杂。
(2)系统数据访问层代码需要修改。
(3)Slave实时性的保障,对于实时性很高的场合可能需要做一些处理。
(4)高可用性问题,Master就是那个致命点,容易产生单点故障。所有的数据处理 都是由Master来进行分配处理,若Master出现故障,导致整个系统崩溃。
(5)MMM集群可以解决Master-Slave中的单个Master读写的致命缺陷,但是其 扩展性差,一次只能一个Master可以写入,只能解决有限数据量下的可用性。
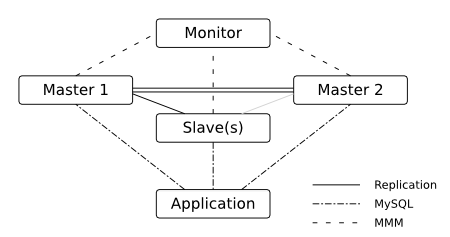
MMM集群方案
2.量数据的高效率存储和访问的需求满足能力低
(1)存储记录数量有限,横向可可扩展能力有限,纵向数据可承受能力也是有限的。
(2)对大数据的查询,SQL查询效率极低,在数据量达到一定的程度,查询时间会成 指数级别增长。
四、NoSQL的优势
1.易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。甚至有多种NoSQL之间的整合。
2.灵活的数据模型
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。
3.高可用
NoSQL在不太影响性能的情况,就可以方便的实现高可用的架构。比如Cassandra,HBase模型,通过复制模型也能实现高可用。
4.大数据量,高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。
五、NoSQL在大数据中的应用
1.NoSQL在hadoop中运用
在大数据处理系统的架构中,当前首选的就是由Apache基金会所开发hadoop,Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。下图为hadoop的构架图:
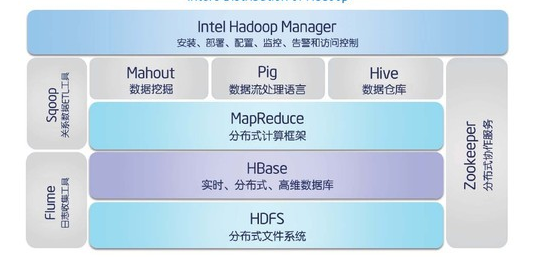
从hadoop的构架图中可以看出,它具有这种处理大数据的能力一方面来自自身的算法设计,另一方面就是来源于它的架构原理,在架构原理图中,可以清楚的看到NoSQL在数据读取中的作用,由此可以看出NoSQL在大数据处理中的优势。值得一提的是hadoop中使用的是Hbase这种NoSQL数据库,具有实时、分布式、高维等特性。
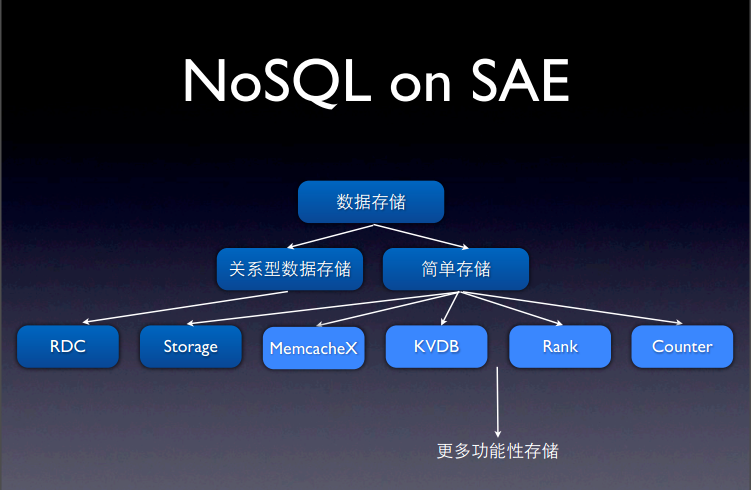
2.Sina App Engine(简称SAE)(新浪云计算平台)
是新浪研发中心于2009年8月开始内部开发,并在2009年11月3日正式推出第一个Alpha版本的国内首个公有云计算平台,SAE是新浪云计算战略的核心组成部分。下图是NoSQl数据库在SAE中的应用,其中KVDB在分布式key/value存储服务上起着重要的作用。
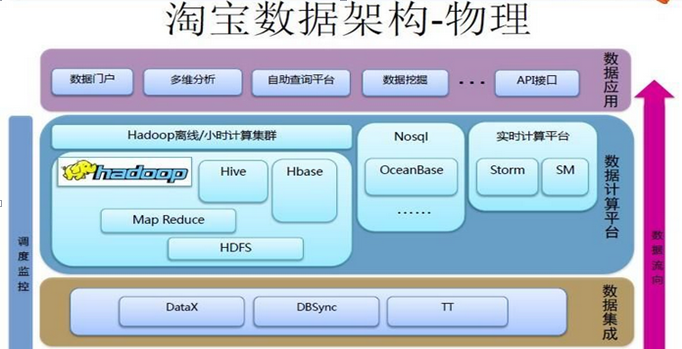
3.NoSQL在淘宝数据架构中的运用
淘宝每天能承受巨大的实时交易与交互数据,那它的背后是怎样设计与架构的呢?在淘宝的数据处理架构中使用了hadoop作为数据处理工具,采用NoSQl作为数据存储间质,从分利用NoSQl在大数据处理中的优势。下图为淘宝的数据架构图。
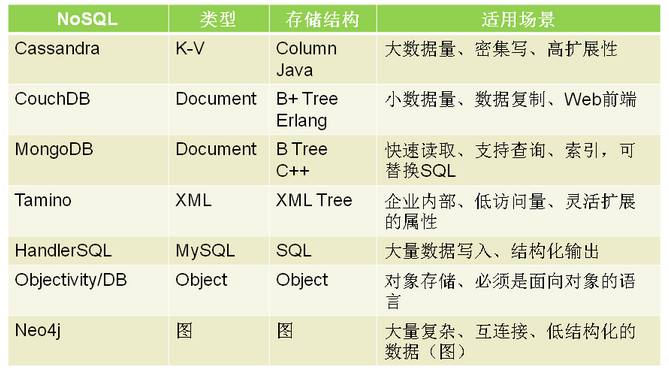
六、常用的NoSQL数据库
按照数据模型保存性质将当前NoSQL分为四种:
1.Key-value stores键值存储, 保存keys+BLOBs (二进制大对象Binary Large OBjects)
2.Table-oriented 面向表, 主要有Google的BigTable和Cassandra.
3.Document-oriented面向文本, 文本是一种类似XML文档,MongoDB 和 CouchDB
4.Graph-oriented 面向图论. 如Neo4J.