温馨提示:整个 Kafka Client 专栏基于 kafka-2.3.0 版本。
@
1、KafkaProducer 概述
根据 KafkaProducer 类上的注释上来看 KafkaProducer 具有如下特征:
-
KafkaProducer 是线程安全的,可以被多个线程交叉使用。
-
KafkaProducer 内部包含一个缓存池,存放待发送消息,即 ProducerRecord 队列,与此同时会开启一个IO线程将 ProducerRecord 对象发送到 Kafka 集群。
-
KafkaProducer 的消息发送 API send 方法是异步,只负责将待发送消息 ProducerRecord 发送到缓存区中,立即返回,并返回一个结果凭证 Future。
-
acks
KafkaProducer 提供了一个核心参数 acks 用来定义消息“已提交”的条件(标准),就是 Broker 端向客户端承偌已提交的条件,可选值如下:- 0
表示生产者不关系该条消息在 broker 端的处理结果,只要调用 KafkaProducer 的 send 方法返回后即认为成功,显然这种方式是最不安全的,因为 Broker 端可能压根都没有收到该条消息或存储失败。 - all 或 -1
表示消息不仅需要 Leader 节点已存储该消息,并且要求其副本(准确的来说是 ISR 中的节点)全部存储才认为已提交,才向客户端返回提交成功。这是最严格的持久化保障,当然性能也最低。 - 1
表示消息只需要写入 Leader 节点后就可以向客户端返回提交成功。
- 0
-
retries
kafka 在生产端提供的另外一个核心属性,用来控制消息在发送失败后的重试次数,设置为 0 表示不重试,重试就有可能造成消息在发送端的重复。 -
batch.size
kafka 消息发送者为每一个分区维护一个未发送消息积压缓存区,其内存大小由batch.size指定,默认为 16K。
但如果缓存区中不足100条,但发送线程此时空闲,是需要等到缓存区中积满100条才能发送还是可以立即发送呢?默认是立即发送,即 batch.size 的作用其实是客户端一次发送到broker的最大消息数量。 -
linger.ms
为了提高 kafka 消息发送的高吞吐量,即控制在缓存区中未积满 batch.size 时来控制 消息发送线程的行为,是立即发送还是等待一定时间,如果linger.ms 设置为 0表示立即发送,如果设置为大于0,则消息发送线程会等待这个值后才会向broker发送。该参数者会增加响应时间,但有利于增加吞吐量。有点类似于 TCP 领域的 Nagle 算法。 -
buffer.memory
用于控制消息发送者缓存的总内存大小,如果超过该值,往缓存区中添加消息会被阻塞,具体会在下文的消息发送流程中详细介绍,阻塞的最大时间可通过参数 max.block.ms 设置,阻塞超过该值会抛出超时异常。 -
key.serializer
指定 key 的序列化处理器。 -
value.serializer
指定 消息体的序列化处理器。 -
enable.idempotence
从 kafka0.11版本开始,支持消息传递幂等,可以做到消息只会被传递一次,通过 enable.idempotence 为 true 来开启。如果该值设置为 true,其 retries 将设置为 Integer.MAX_VALUE,acks 将被设置为 all。为了确保消息发送幂等性,必须避免应用程序端的任何重试,并且如果消息发送API如果返回错误,应用端应该记录最后成功发送的消息,避免消息的重复发送。
从Kafka 0.11开始,kafka 也支持事务消息。
2、KafkaProducer 类图
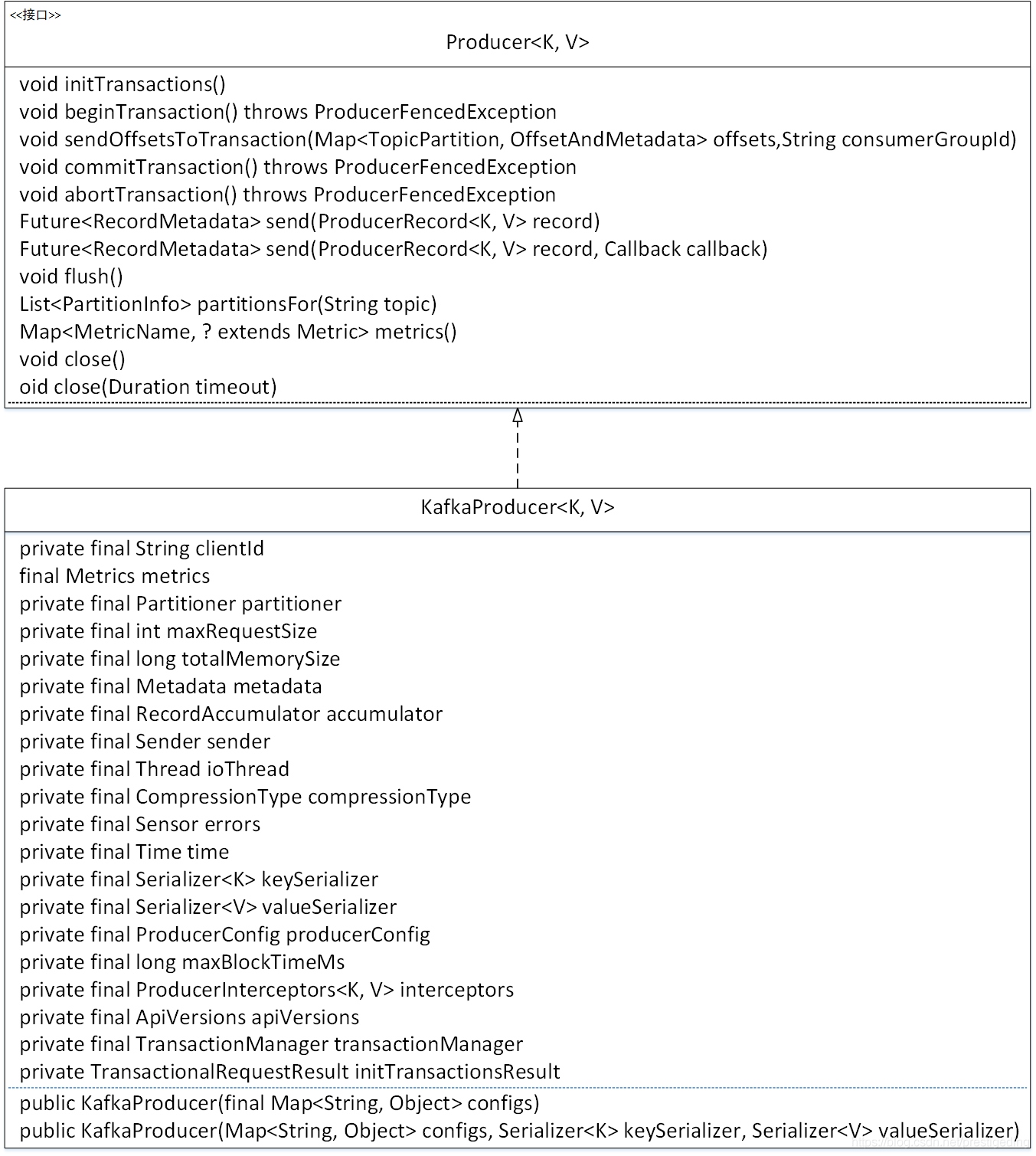
在 Kafka 中,生产者通过接口 Producer 定义,通过该接口的方法,我们基本可以得知 KafkaProducer 将具备如下基本能力:
- void initTransactions()
初始化事务,如果需要使用事务方法,该方法必须首先被调用。 - void beginTransaction()
开启事务。 - void sendOffsetsToTransaction(Map< TopicPartition, OffsetAndMetadata> offsets,String consumerGroupId)
向消费组提交当前事务中的消息偏移量,将在介绍 Kafka 事务相关文章中详细介绍。 - void commitTransaction()
提交事务。 - void abortTransaction()
回滚事务。 - Future< RecordMetadata> send(ProducerRecord<K, V> record)
消息发送,该方法默认为异步发送,如果要实现同步发送的效果,对返回结果调用 get 方法即可,该方法将在下篇文章中详细介绍。 - Future< RecordMetadata> send(ProducerRecord<K, V> record, Callback callback)
消息发送,支持回调。 - void flush()
忽略 linger.ms 的值,直接唤醒发送线程,将缓冲区中的消息全部发送到 broker。 - List< PartitionInfo> partitionsFor(String topic)
获取 topic 的路由信息(分区信息)。 - Map< MetricName, ? extends Metric> metrics()
获取由生产者收集的统计信息。 - void close()
关闭发送者。 - void close(Duration timeout)
定时关闭消息发送者。
上面的方法我们会根据需要在后续文章中进行详细的介绍。接下来我们看一下 KafkaProducer 的核心属性的含义。
- String clientId
客户端ID。在创建 KafkaProducer 时可通过 client.id 定义 clientId,如果未指定,则默认 producer- seq,seq 在进程内递增,强烈建议客户端显示指定 clientId。 - Metrics metrics
度量的相关存储容器,例如消息体大小、发送耗时等与监控相关的指标。 - Partitioner partitioner
分区负载均衡算法,通过参数 partitioner.class 指定。 - int maxRequestSize
调用 send 方法发送的最大请求大小,包括 key、消息体序列化后的消息总大小不能超过该值。通过参数 max.request.size 来设置。 - long totalMemorySize
生产者缓存所占内存的总大小,通过参数 buffer.memory 设置。 - Metadata metadata
元数据信息,例如 topic 的路由信息,由 KafkaProducer 自动更新。 - RecordAccumulator accumulator
消息记录累积器,将在消息发送部分详细介绍。 - Sender sender
用于封装消息发送的逻辑,即向 broker 发送消息的处理逻辑。 - Thread ioThread
用于消息发送的后台线程,一个独立的线程,内部使用 Sender 来向 broker 发送消息。 - CompressionType compressionType
压缩类型,默认不启用压缩,可通过参数 compression.type 配置。可选值:none、gzip、snappy、lz4、zstd。 - Sensor errors
错误信息收集器,当成一个 metrics,用来做监控的。 - Time time
用于获取系统时间或线程睡眠等。 - Serializer< K> keySerializer
用于对消息的 key 进行序列化。 - Serializer< V> valueSerializer
对消息体进行序列化。 - ProducerConfig producerConfig
生产者的配置信息。 - long maxBlockTimeMs
最大阻塞时间,当生产者使用的缓存已经达到规定值后,此时消息发送会阻塞,通过参数 max.block.ms 来设置最多等待多久。 - ProducerInterceptors<K, V> interceptors
生产者端的拦截器,在消息发送之前进行一些定制化处理。 - ApiVersions apiVersions
维护 api 版本的相关元信息,该类只能在 kafka 内部使用。 - TransactionManager transactionManager
kafka 消息事务管理器。 - TransactionalRequestResult initTransactionsResult
kafka 生产者事务上下文环境初始结果。
经过上面的梳理,详细读者朋友对 KafkaProducer 消息生产者有了一个大概的认识,下一篇会重点介绍消息发送流程。接下来我们以一个简单的示例结束本文的学习。
3、KafkaProducer 简单示例
package persistent.prestige.demo.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.Future;
public class KafkaProducerTest {
public static void main(String[] args){
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092,localhost:9082,localhost:9072,");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
try {
for (int i = 0; i < 100; i++) {
Future<RecordMetadata> future = producer.send(new ProducerRecord<String, String>("TOPIC_ORDER", Integer.toString(i), Integer.toString(i)));
RecordMetadata recordMetadata = future.get();
System.out.printf("offset:" + recordMetadata.offset());
}
} catch (Throwable e) {
e.printStackTrace();
} finally {
producer.close();
}
}
}
本文就介绍到这里,其主要的目的是了解Kafka 的 Producer,引出后续需要学习的内容,下一篇将重点讲述 Kafka 消息的发送流程,敬请关注。
如果本文对大家有所帮助的话,麻烦帮忙点个赞,谢谢。
作者介绍:
丁威,《RocketMQ技术内幕》作者,RocketMQ 社区布道师,公众号:中间件兴趣圈 维护者,目前已陆续发表源码分析Java集合、Java 并发包(JUC)、Netty、Mycat、Dubbo、RocketMQ、Mybatis等源码专栏。欢迎加入我的知识星球,构建一个高质量的技术交流社群。
