Redis如何做持久化的?
bgsave做镜像全量持久化,aof做增量持久化。
因为bgsave会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要aof来配合使用。
在redis实例重启时,会使用bgsave持久化文件重新构建内存,再使用aof重放近期的操作指令来实现完整恢复重启之前的状态。
对方追问那如果突然机器掉电会怎样?取决于aof日志sync属性的配置,如果不要求性能,在每条写指令时都sync一下磁盘,就不会丢失数据。
但是在高性能的要求下每次都sync是不现实的,一般都使用定时sync,比如1s1次,这个时候最多就会丢失1s的数据。
对方追问bgsave的原理是什么?你给出两个词汇就可以了,fork和cow。
fork是指redis通过创建子进程来进行bgsave操作,cow指的是copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
https://www.cnblogs.com/linkworld/p/7808818.html
如何保证redis中存放的都是热点数据
缓存击穿
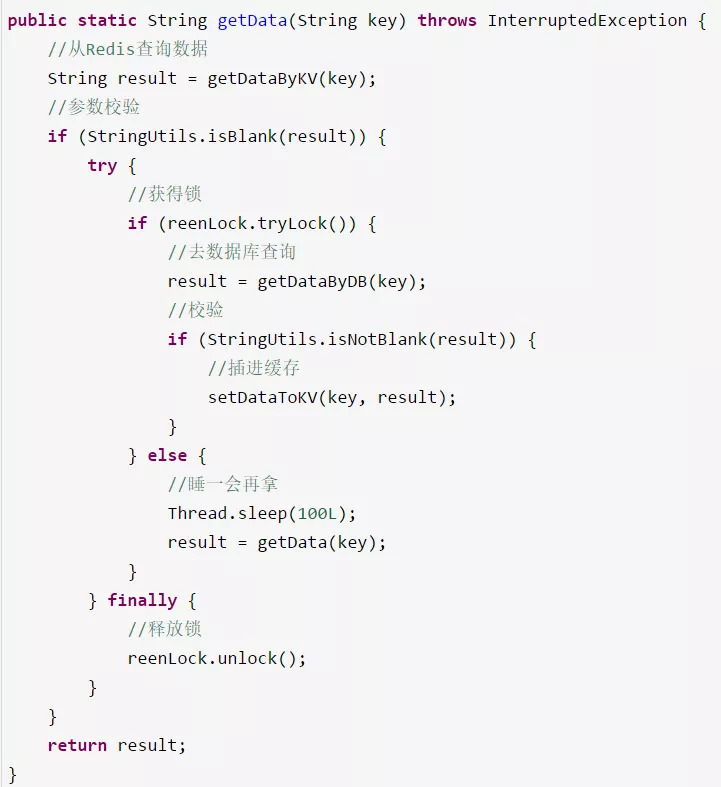
指的是热点key在某个特殊的场景时间内恰好失效了,恰好有大量并发请求过来了,造成DB压力。
解决办法
设置热点数据永不过期,或者加上互斥锁就搞定了。
与缓存雪崩的解决方法类似: 用加锁或者队列的方式保证缓存的单线程(进程)写,在加锁方法内先从缓存中再获取一次,没有再查DB写入缓存。
还有一种比较好用的(针对缓存雪崩与缓存击穿):
当获取到数据后,校验数据内部的标记时间,判定是否快超时了,如果是,异步发起一个线程(控制好并发)去主动更新该缓存。这种方式会导致一定时间内,有些请求获取缓存会拿到过期的值,看业务是否能接受而定。其实,大多数情况下这种爆款很难对数据库服务器造成压垮性的压力。达到这个级别的公司没有几家的。所以,务实主义的小编,对主打商品都是早早的做好了准备,让缓存永不过期。即便某些商品自己发酵成了爆款,也是直接设为永不过期就好了。
缓存穿透
指查询缓存不存在的数据值,这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透。
解决方法
1.缓存穿透我会在接口层增加校验,比如用户鉴权,参数做校验,不合法的校验直接return。
2 缓存层缓存空值。
–缓存太多空值,占用更多空间。(优化:给个空值过期时间) 如果从数据库查询的对象为空,也放入缓存,只是设定的缓存过期时间较短,比如设置为60。
–存储层更新代码了,缓存层还是空值。(优化:后台设置时主动删除空值,并缓存把值进去)
3 将数据库中所有的查询条件,放到布隆过滤器中。当一个查询请求来临的时候,先经过布隆过滤器进行检查,如果请求存在这个条件中,那么继续执行,如果不在,直接丢弃。
Redis里还有一个高级用法布隆过滤器(Bloom Filter)这个也能很好的预防缓存穿透的发生,就是利用高效的数据结构和算法快速判断出你这个Key是否在数据库中存在,不存在你return就好了,存在你就去查DB刷新KV再return。
缓存雪崩
指的是大量缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。
小编在做电商项目的时候,一般是采取不同分类商品,缓存不同周期。在同一分类中的商品,加上一个随机因子。这样能尽可能分散缓存过期时间,而且,热门类目的商品缓存时间长一些,冷门类目的商品缓存时间短一些,也能节省缓存服务的资源。

redis和数据库的数据一致性
假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来?
https://www.jianshu.com/p/be15dc89a3e8
参考:
http://www.luyixian.cn/news_show_36921.aspx
https://blog.csdn.net/fanrenxiang/article/details/80542580