消息中间件模式分类
点对点
PTP点对点:使用queue作为通信载体
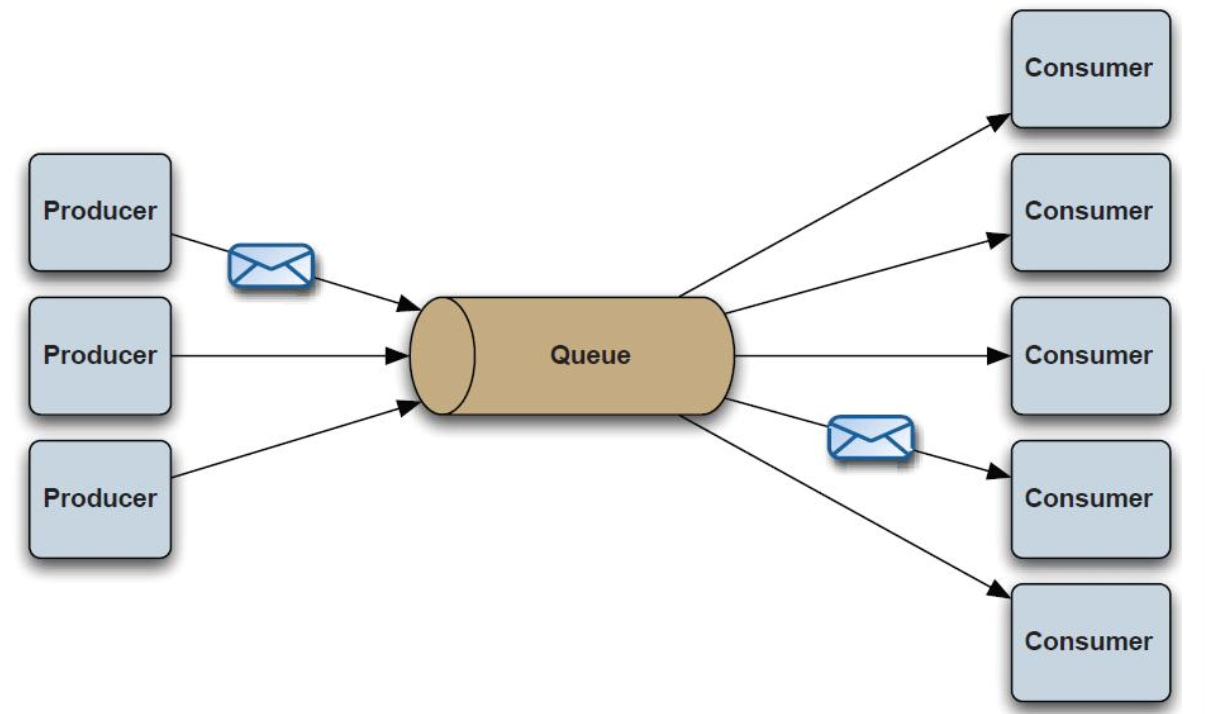
说明:
消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息。
消息被消费以后,queue中不再存储,所以消息消费者不可能消费到已经被消费的消息。 Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
发布/订阅
Pub/Sub发布订阅(广播):使用topic作为通信载体
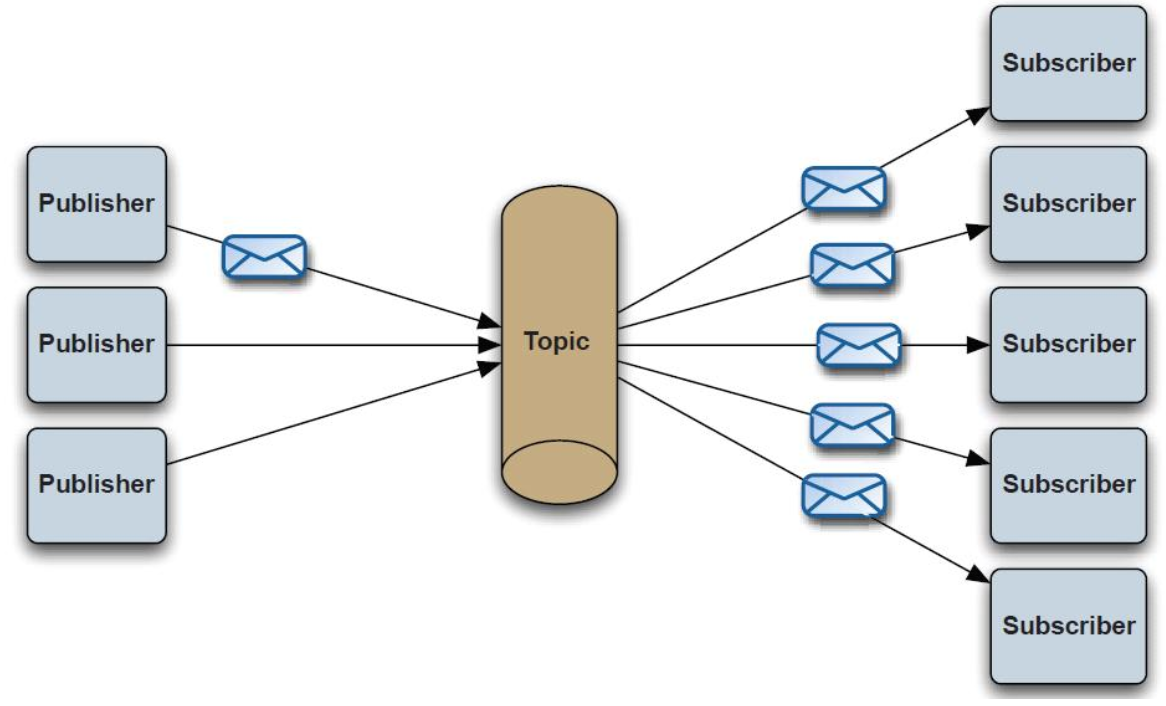
说明:
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
queue实现了负载均衡,将producer生产的消息发送到消息队列中,由多个消费者消费。但一个消息只能被一个消费者接受,当没有消费者可用时,这个消息会被保存直到有一个可用的消费者。
topic实现了发布和订阅,当你发布一个消息,所有订阅这个topic的服务都能得到这个消息,所以从1到N个订阅者都能得到一个消息的拷贝。
MQ 如何保证消息的顺序性?
RabbitMQ、Kafka
RocketMQ
经过https://www.cnblogs.com/xuwc/p/9034352.html 分析这样的模型就严格保证消息的顺序。
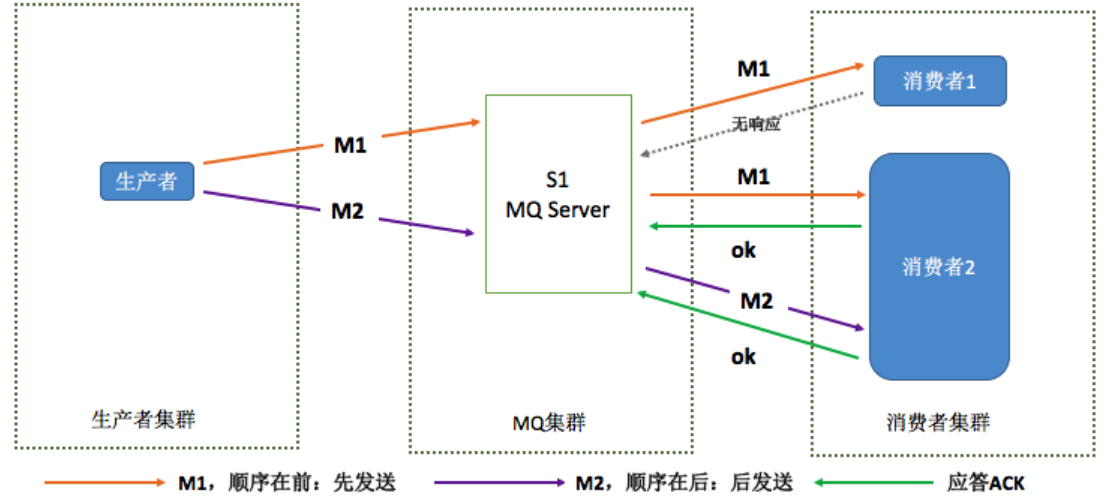
保证生产者 - MQServer - 消费者是一对一对一的关系
。。。
RocketMQ怎么实现发送顺序消息:
Producer端确保消息顺序唯一要做的事情就是将消息路由到特定的分区,在RocketMQ中,通过MessageQueueSelector来实现分区的选择。
一般消息是通过轮询所有队列来发送的(负载均衡策略),顺序消息可以根据业务,比如说订单号相同的消息发送到同一个队列。下面的示例中,OrderId相同的消息,会发送到同一个队列:
// RocketMQ默认提供了两种MessageQueueSelector实现:随机/Hash SendResult sendResult = producer.send(msg, new MessageQueueSelector() { @Override public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) { Integer id = (Integer) arg; int index = id % mqs.size(); return mqs.get(index); } }, orderId);
在获取到路由信息以后,会根据MessageQueueSelector实现的算法来选择一个队列,同一个OrderId获取到的队列是同一个队列。
private SendResult send() { // 获取topic路由信息 TopicPublishInfo topicPublishInfo = this.tryToFindTopicPublishInfo(msg.getTopic()); if (topicPublishInfo != null && topicPublishInfo.ok()) { MessageQueue mq = null; // 根据我们的算法,选择一个发送队列 // 这里的arg = orderId mq = selector.select(topicPublishInfo.getMessageQueueList(), msg, arg); if (mq != null) { return this.sendKernelImpl(msg, mq, communicationMode, sendCallback, timeout); } } }
Consumer端
RocketMQ消费端有两种类型:MQPullConsumer和MQPushConsumer。
MQPullConsumer由用户控制线程,主动从服务端获取消息,每次获取到的是一个MessageQueue中的消息。PullResult中的List msgFoundList自然和存储顺序一致,用户需要再拿到这批消息后自己保证消费的顺序。
PushConsumer,由用户注册MessageListener来消费消息,在客户端中需要保证调用MessageListener时消息的顺序性。RocketMQ中的实现如下:
...
RocketMQ 消息发送默认是会采用轮询的方式发送到不通的queue(分区)通过MessageQueueSelector来实现分区的选择,比如说订单号相同的消息 把订单号取了做了一个取模运算再丢到selector中,selector保证同一个模的都会投递到同一条queue。即: 相同订单号的--->有相同的模--->有相同的queue。
kafka 我们建了一个 topic,有三个 partition。生产者在写的时候,其实可以指定一个 key,比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。消费者从 partition 中取出来数据的时候,也一定是有顺序的。但消费者多个线程并发处理消息时,顺序可能就乱掉了。这时消费端写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
MQ消息避免重复消费
1)redis setNx()
2)jedis.Incr
3)数据库去重
MQ 消息堆积
RocketMQ
解决方案
请按照如下方法排查并解决问题:
-
登录消息队列 RocketMQ 控制台,选择资源报表 > 消息消费,查询历史消费记录。如果消息写入速度大于消息消费速度,调整业务代码或对消费者进行扩容。
-
在应用打印 Jstack 信息 jstack -l {pid} | grep ConsumeMessageThread。如果有消息阻塞现象,连续打印 5 次 Jstack 信息,确认消费线程卡在哪里,解决后可尝试重启应用观察消费是否恢复。
-
如果消息已经没有堆积,检查阈值是否设置过小导致消息堆积,单击监控报警,单击编辑,增大消息堆积的报警阈值。
结果验证
-
在应用打印 Jstack 信息 jstack -l {pid} | grep ConsumeMessageThread,无消费线程阻塞现象。
-
登录消息队列 RocketMQ 控制台,选择 Group 管理 > 消费者状态,消费 TPS 栏的值上升,堆积量栏的值下降。
RabbitMQ
- 增加消费者的处理能力,或减少发布频率
- 单纯升级硬件不是办法,只能起到一时的作用
- 考虑使用队列最大长度限制,RabbitMQ 3.1支持
- 给消息设置年龄,超时就丢弃
MQ如果防止消息丢失
自己设计MQ
-
首先 mq 得支持可伸缩性,就是需要的时候快速扩容,就可以增加吞吐量和容量,设计个分布式的系统呗,参照一下 kafka 的设计理念,broker -> topic -> partition,每个 partition 放一个机器,就存一部分数据。如果现在资源不够了,简单啊,给 topic 增加 partition,然后做数据迁移,增加机器,不就可以存放更多数据,提供更高的吞吐量了?
-
其次你得考虑一下这个 mq 的数据要不要落地磁盘吧?那肯定要了,落磁盘才能保证别进程挂了数据就丢了。那落磁盘的时候怎么落啊?顺序写,这样就没有磁盘随机读写的寻址开销,磁盘顺序读写的性能是很高的,这就是 kafka 的思路。
-
其次你考虑一下你的 mq 的可用性啊?这个事儿,具体参考之前可用性那个环节讲解的 kafka 的高可用保障机制。多副本 -> leader & follower -> broker 挂了重新选举 leader 即可对外服务。
-
能不能支持数据 0 丢失啊?可以的,参考我们之前说的那个 kafka 数据零丢失方案。