数组
数组是可以再内存中连续存储多个元素的结构,在内存中的分配也是连续的,数组中的元素通过数组下标进行访问,数组下标从0开始。
定义一个数组:
int[] data = new int[100];
优点:
1、按照索引查询元素速度快
2、按照索引遍历数组方便
缺点:
1、数组的大小固定后就无法扩容了
2、数组只能存储一种类型的数据
3、添加,删除的操作慢,因为要移动其他的元素。
适用场景:
频繁查询,对存储空间要求不大,很少增加和删除的情况。
对于指定下标的查找,时间复杂度为O(1);
通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);
对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)。
栈
后进先出(LIFO)
算法基本思想
可以用单链表实现。
适用场景:只关心上一次的操作,处理完上一次的操作,能在O(1)时间内查找到更前一次的操作。
eg:有效的括号
初始化 Stack stack=new Stack 判断是否为空 stack.empty() 取栈顶值(不出栈) stack.peek() 进栈 stack.push(Object); 出栈 stack.pop();
队列
先进先出(FIFO)
常用场景
广度优先搜索
双端队列
特点:双端队列和普通队列最大的不同在于,它允许我们在队列的头尾两端都能在O(1)的时间内进行数据的查看、添加和删除。
实现:与队列相似,我们可以利用一个双链表实现双端队列。
应用场景:
双端队列最常用的地方就是实现一个长度动态变化的窗口或者连续区间,而动态窗口这种数据结构在很多题目里都有运用。
https://www.cnblogs.com/lemon-flm/p/7877898.html
链表
链表是物理存储单元上非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,每个元素包含两个结点,一个是存储元素的数据域 (内存空间),另一个是指向下一个结点地址的指针域。根据指针的指向,链表能形成不同的结构,例如单链表,双向链表,循环链表等。
定义链表
优点:
链表是很常用的一种数据结构,不需要初始化容量,可以任意加减元素;
添加或者删除元素时只需要改变前后两个元素结点的指针域指向地址即可,所以添加,删除很快;
缺点:
因为含有大量的指针域,占用空间较大;
查找元素需要遍历链表来查找,非常耗时。
适用场景:
数据量较小,需要频繁增加,删除操作的场景
对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)。
1)利用快慢指针(有时候需要三个指针)
2)构建一个虚假的链表头
K个一组翻转链表
散列表
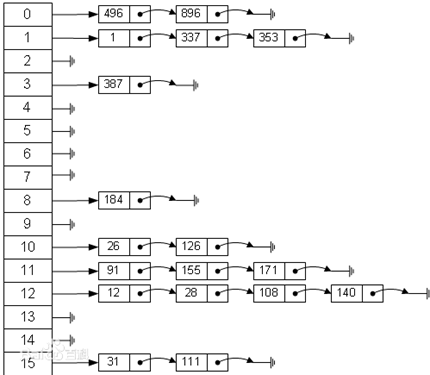
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
堆
堆是一种比较特殊的数据结构,可以被看做一棵树的数组对象,具有以下的性质:
堆中某个节点的值总是不大于或不小于其父节点的值;
堆总是一棵完全二叉树。
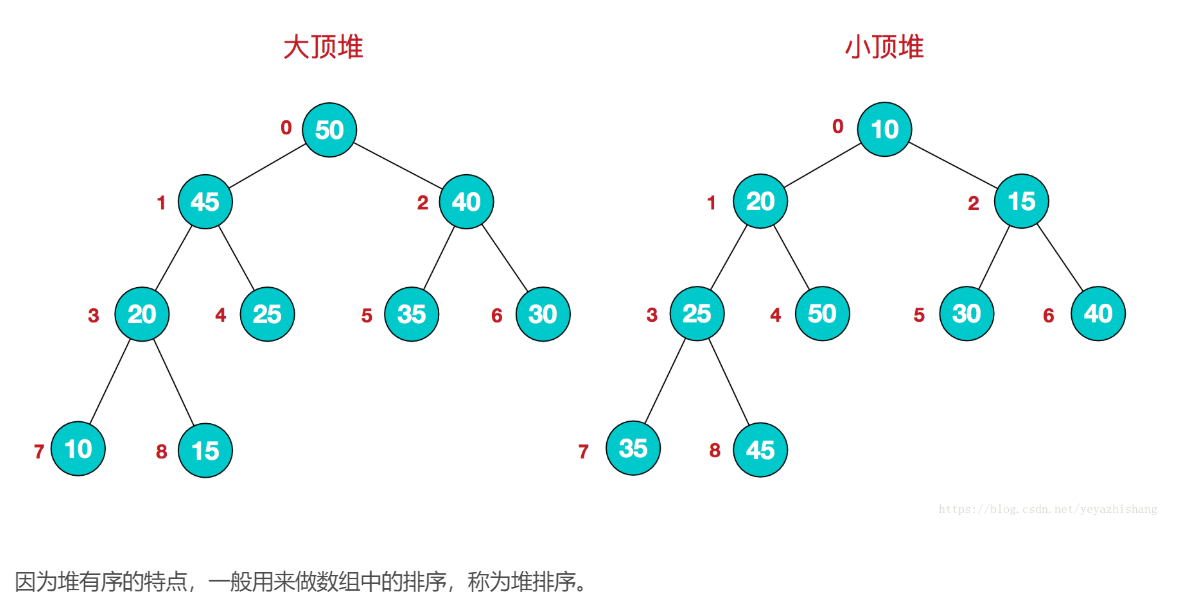
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
堆的定义如下:n个元素的序列{k1,k2,ki,…,kn}当且仅当满足下关系时,称之为堆。
(ki <= k2i,ki <= k2i+1)或者(ki >= k2i,ki >= k2i+1), (i = 1,2,3,4…n/2),满足前者的表达式的成为小顶堆,满足后者表达式的为大顶堆,这两者的结构图可以用完全二叉树排列出来,示例图如下:
图
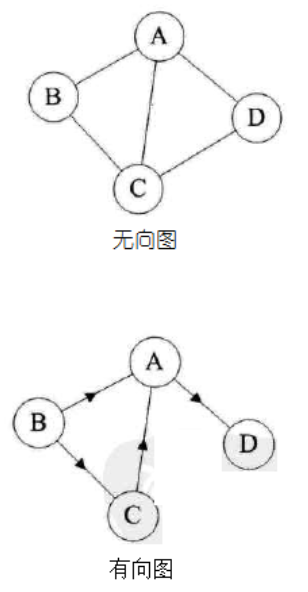
图是由结点的有穷集合V和边的集合E组成。其中,为了与树形结构加以区别,在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。
按照顶点指向的方向可分为无向图和有向图:
图是一种比较复杂的数据结构,在存储数据上有着比较复杂和高效的算法,分别有邻接矩阵 、邻接表、十字链表、邻接多重表、边集数组等存储结构,这里不做展开,读者有兴趣可以自己学习深入。
转自:https://blog.csdn.net/yeyazhishang/article/details/82353846