引言
对于一个大型的互联网应用,海量数据的存储和访问成为了系统设计的瓶颈问题,对于系统的稳定性和扩展性造成了极大的问题。通过数据切分来提高网站性能,横向扩展数据层已经成为架构研发人员首选的方式。
•水平切分数据库:可以降低单台机器的负载,同时最大限度的降低了宕机造成的损失;
•负载均衡策略:可以降低单台机器的访问负载,降低宕机的可能性;
•集群方案:解决了数据库宕机带来的单点数据库不能访问的问题;
•读写分离策略:最大限度了提高了应用中读取数据的速度和并发量;
问题描述
1、单个表数据量越大,读写锁,插入操作重新建立索引效率越低。
2、单个库数据量太大(一个数据库数据量到1T-2T就是极限)
3、单个数据库服务器压力过大
4、读写速度遇到瓶颈(并发量几百)
解决问题的思路:根据自己的实际情况,当单表过大的时候进行分表,数据库过大的时候进行分库,高并发的情况考虑读写分离和集群。
数据拆分的方式有:分区、分表、分库
•分区
•就是把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的
•分表
•就是把一张表按一定的规则分解成N个具有独立存储空间的实体表。系统读写时需要根据定义好的规则得到对应的字表明,然后操作它。
•分库
一旦分表,一个库中的表会越来越多
将整个数据库比作图书馆,一张表就是一本书。当要在一本书中查找某项内容时,如果不分章节,查找的效率将会下降。而同理,在数据库中就是分区。
分区
什么时候考虑使用分区?
•一张表的查询速度已经慢到影响使用的时候。
•sql经过优化
•数据量大
•表中的数据是分段的
•对数据的操作往往只涉及一部分数据,而不是所有的数据
分区解决的问题
•主要可以提升查询效率
分表
什么时候考虑分表?
•一张表的查询速度已经慢到影响使用的时候。
•sql经过优化
•数据量大
•当频繁插入或者联合查询时,速度变慢
分表解决的问题
•分表后,单表的并发能力提高了,磁盘I/O性能也提高了,写操作效率提高了
•查询一次的时间短了
•数据分布在不同的文件,磁盘I/O性能提高
•读写锁影响的数据量变小
•插入数据库需要重新建立索引的数据减少
分区和分表的区别与联系
•分区和分表的目的都是减少数据库的负担,提高表的增删改查效率。
•分区只是一张表中的数据的存储位置发生改变,分表是将一张表分成多张表。
•当访问量大,且表数据比较大时,两种方式可以互相配合使用。
•当访问量不大,但表数据比较多时,可以只进行分区。
常见分区分表的规则策略(类似)
•Range(范围)
•Hash(哈希)
•按照时间拆分
•Hash之后按照分表个数取模
•在认证库中保存数据库配置,就是建立一个DB,这个DB单独保存user_id到DB的映射关系
分库
什么时候考虑使用分库?
•单台DB的存储空间不够
•随着查询量的增加单台数据库服务器已经没办法支撑
分库解决的问题
•其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题。
垂直拆分
•将系统中不存在关联关系或者需要join的表可以放在不同的数据库不同的服务器中。
•按照业务垂直划分。比如:可以按照业务分为资金、会员、订单三个数据库。
•需要解决的问题:跨数据库的事务、jion查询等问题。
水平拆分
•例如,大部分的站点。数据都是和用户有关,那么可以根据用户,将数据按照用户水平拆分。
•按照规则划分,一般水平分库是在垂直分库之后的。比如每天处理的订单数量是海量的,可以按照一定的规则水平划分。需要解决的问题:数据路由、组装。
读写分离
•对于时效性不高的数据,可以通过读写分离缓解数据库压力。需要解决的问题:在业务上区分哪些业务上是允许一定时间延迟的,以及数据同步问题。
思路:
垂直分库-->水平分库-->读写分离
数据拆分以后面临的问题
问题
•事务的支持,分库分表,就变成了分布式事务、
分库分表后,就成了分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价; 如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
•join时跨库,跨表的问题
•分库分表,读写分离使用了分布式,分布式为了保证强一致性,必然带来延迟,导致性能降低,系统的复杂度变高。
分库分表后表之间的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表, 结果原本一次查询能够完成的业务,可能需要多次查询才能完成。 粗略的解决方法: 全局表:基础数据,所有库都拷贝一份。 字段冗余:这样有些字段就不用join去查询了。 系统层组装:分别查询出所有,然后组装起来,较复杂。
常用的解决方案:
•对于不同的方式之间没有严格的界限,特点不同,侧重点不同。需要根据实际情况,结合每种方式的特点来进行处理。
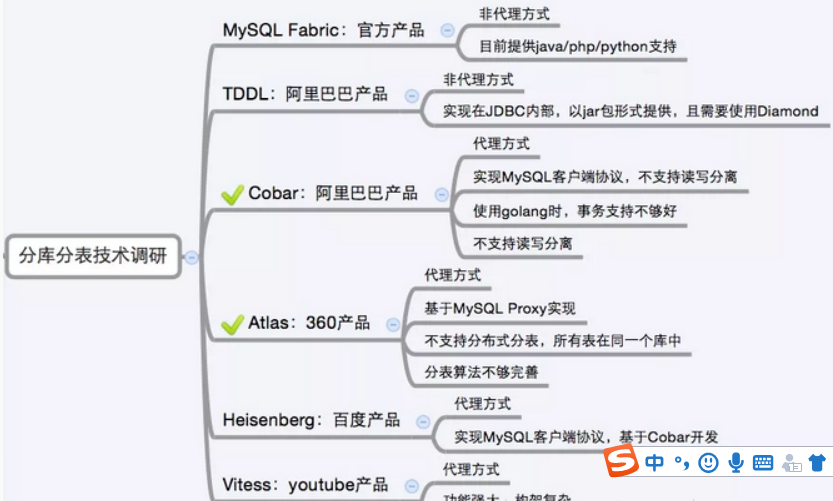
•选用第三方的数据库中间件(Atlas,Mycat,TDDL,DRDS),同时业务系统需要配合数据存储的升级。
数据存储的演进
单库单表
•单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到。
单库多表
•随着用户数量的增加,user表的数据量会越来越大,当数据量达到一定程度的时候对user表的查询会渐渐的变慢,从而影响整个DB的性能。如果使用mysql, 还有一个更严重的问题是,当需要添加一列的时候,mysql会锁表,期间所有的读写操作只能等待。
•可以通过某种方式将user进行水平的切分,产生两个表结构完全一样的user_0000,user_0001等表,user_0000 + user_0001 + …的数据刚好是一份完整的数据。
多库多表
随着数据量增加也许单台DB的存储空间不够,随着查询量的增加单台数据库服务器已经没办法支撑。这个时候可以再对数据库进行水平拆分。
总结
总的来说,优先考虑分区。当分区不能满足需求时,开始考虑分表,合理的分表对效率的提升会优于分区。
垂直分库-->水平分库-->读写分离
实操
1、单库多表
单库多表是对数据的水平拆分,多张表的表结构完全相同,数据按照不同的规则进行拆分,存储到对于的数据表中。

这是我安装数据的年份进行拆分的数据表,数据存储的时候根据数据的年份存到对于的表中,我们的查询业务也都是按照年份进行,一般没有跨年份的数据查询,这样就避免了多表查询后数据的合并。
2、多库单表
完全相同的数据库,安装不同规则存储各自的数据,下面是我的spring boot多数据源配置:
#更多数据源
custom.datasource.names=jiangsu,anhui,shandong,hubei,hunan,fujian
custom.datasource.jiangsu.type=com.zaxxer.hikari.HikariDataSource
custom.datasource.jiangsu.driverClassName=com.mysql.jdbc.Driver
custom.datasource.jiangsu.url=jdbc:mysql://127.0.0.1:3306/nda_jiangsu?useUnicode=yes&characterEncoding=UTF-8
custom.datasource.jiangsu.username=root
custom.datasource.jiangsu.password=
custom.datasource.anhui.type=com.zaxxer.hikari.HikariDataSource
custom.datasource.anhui.driverClassName=com.mysql.jdbc.Driver
custom.datasource.anhui.url=jdbc:mysql://127.0.0.1:3306/nda_anhui?useUnicode=yes&characterEncoding=UTF-8
custom.datasource.anhui.username=root
custom.datasource.anhui.password=
custom.datasource.shandong.type=com.zaxxer.hikari.HikariDataSource
custom.datasource.shandong.driverClassName=com.mysql.jdbc.Driver
custom.datasource.shandong.url=jdbc:mysql://127.0.0.1:3306/nda_shandong?useUnicode=yes&characterEncoding=UTF-8
custom.datasource.shandong.username=root
custom.datasource.shandong.password=
custom.datasource.hubei.type=com.zaxxer.hikari.HikariDataSource
custom.datasource.hubei.driverClassName=com.mysql.jdbc.Driver
custom.datasource.hubei.url=jdbc:mysql://127.0.0.1:3306/nda_hubei?useUnicode=yes&characterEncoding=UTF-8
custom.datasource.hubei.username=root
custom.datasource.hubei.password=
custom.datasource.hunan.type=com.zaxxer.hikari.HikariDataSource
custom.datasource.hunan.driverClassName=com.mysql.jdbc.Driver
custom.datasource.hunan.url=jdbc:mysql://127.0.0.1:3306/nda_hunan?useUnicode=yes&characterEncoding=UTF-8
custom.datasource.hunan.username=root
custom.datasource.hunan.password=
custom.datasource.fujian.type=com.zaxxer.hikari.HikariDataSource
custom.datasource.fujian.driverClassName=com.mysql.jdbc.Driver
custom.datasource.fujian.url=jdbc:mysql://127.0.0.1:3306/nda_fujian?useUnicode=yes&characterEncoding=UTF-8
custom.datasource.fujian.username=root
custom.datasource.fujian.password=
这是按照省进行数据拆分,保证各个省的数据完整性
在相关业务操作的时候,根据用户所在的省份查询对应的数据库:
DynamicDataSourceContextHolder.setDataSourceType(provincename);
3、多库多表
在介绍多库多表的时候,给大家介绍一个轻量级分库分表工具,sharding-jdbc,这是当当网自己实现的基本JDBC的数据库多库多表解决方案。可以让你在写业务代码的时候完全按照单库单表进行,多库多表的问题有sharding-jdbc帮你解决,需要自己实现分库分表规则接口,配置分库分表规则。
pom.xml配置

实现分库规则接口
public class DemoDatabaseShardingAlgorithm implements PreciseShardingAlgorithm{ @Override
public String doSharding(Collectioncollection, PreciseShardingValue preciseShardingValue) {
for (String each : collection) {
System.out.println(each+"=="+preciseShardingValue.getValue());
if (each.endsWith(Long.parseLong(preciseShardingValue.getValue().toString()) % 2+"")) {
return each;
}
}
throw new IllegalArgumentException();
}
}
实现分表规则接口
public class DemoTableShardingAlgorithm implements PreciseShardingAlgorithm{
@Override
public String doSharding(Collectioncollection, PreciseShardingValue preciseShardingValue) {
for (String each : collection) {
System.out.println(each+"=2="+preciseShardingValue.getValue());
if (each.endsWith(Long.parseLong(preciseShardingValue.getValue().toString()) % 2+"")) {
return each;
}
}
throw new IllegalArgumentException();
}
}
调用规则
@Bean(name = "shardingDataSource")
DataSource getShardingDataSource() throws SQLException {
ShardingRuleConfiguration shardingRuleConfig;
shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(getUserTableRuleConfiguration());
shardingRuleConfig.getBindingTableGroups().add("user_info");
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_id", DemoDatabaseShardingAlgorithm.class.getName()));
shardingRuleConfig.setDefaultTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_id", DemoTableShardingAlgorithm.class.getName()));
return new ShardingDataSource(shardingRuleConfig.build(createDataSourceMap()));
}
这样完成以后,业务代码就可以完全按照单表就行书写,Sharding-JDBC会自动帮你实现分库分表的数据库插入,以及查询时候的多表数据合并。
Sharding-JDBC 采用在 JDBC 协议层扩展分库分表,是一个以 jar 形式提供服务的轻量级组件,其核心思路是小而美地完成最核心的事情。
Sharding-JDBC 还提供了读写分离的能力,用于减轻写库的压力。
此外,Sharding-JDBC 可以用在 JPA 场景中,如 JPA、Hibernate、Mybatis,Spring JDBC Template 等任何 Java 的 ORM 框架。
不过目前Sharding-JDBC仅支持mysql数据库
然后还有一个第三方插件mycat也可以实现分库分表的数据插入和查询,不过mycat是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成一个 MySQL 数据库,而 Sharding-JDBC 是基于 JDBC 接口的扩展,是以 jar 包的形式提供轻量级服务的。
在使用中将mycat查询启动,它自己就成为了一个虚拟数据库,而业务程序是连接的mycat的虚拟数据库的,然后mycat连接实际数据库实现数据的分库分表。
分库分表方案产品介绍
目前市面上的分库分表中间件相对较多,其中基于代理方式的有MySQL Proxy和Amoeba, 基于Hibernate框架的是Hibernate Shards,基于jdbc的有当当sharding-jdbc, 基于mybatis的类似maven插件式的有蘑菇街的蘑菇街TSharding, 通过重写spring的ibatis template类的Cobar Client。
还有一些大公司的开源产品: