最近正在阅读CVPR2019的论文Deep High-Resolution Representation Learning for Human Pose Estimation。
无奈看论文中的Network instantiation部分太过简略,在网上也没有搜索到一个非常清晰的图示。
我阅读这篇论文的时候,觉得自己如果无法完全清晰地知晓网络结构,就始终有一种浮于表面的感觉,相当于只是学习了一个本文的idea。因此我先去学习了ResNet,再一边学pytorch一边阅读了https://github.com/leoxiaobin/deep-high-resolution-net.pytorch的开源代码(主要是lib/models/pose_resnet.py,网络参数参考的是lib/config/models.py),才算是有了一个比较清晰的认知。
我自己将网络结构手画了下来,首先是整体结构:

其次是对每一模块的详细图示:
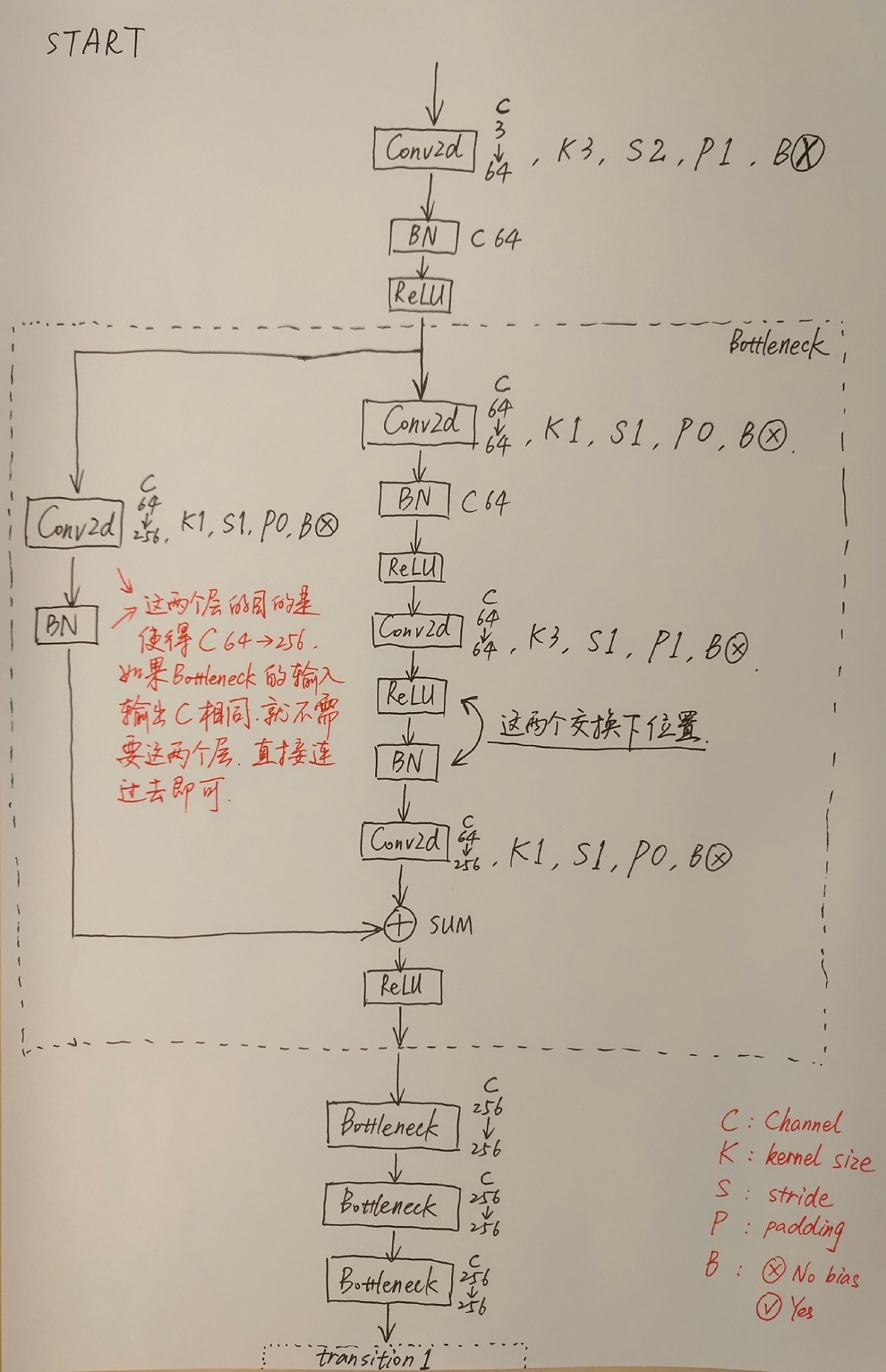
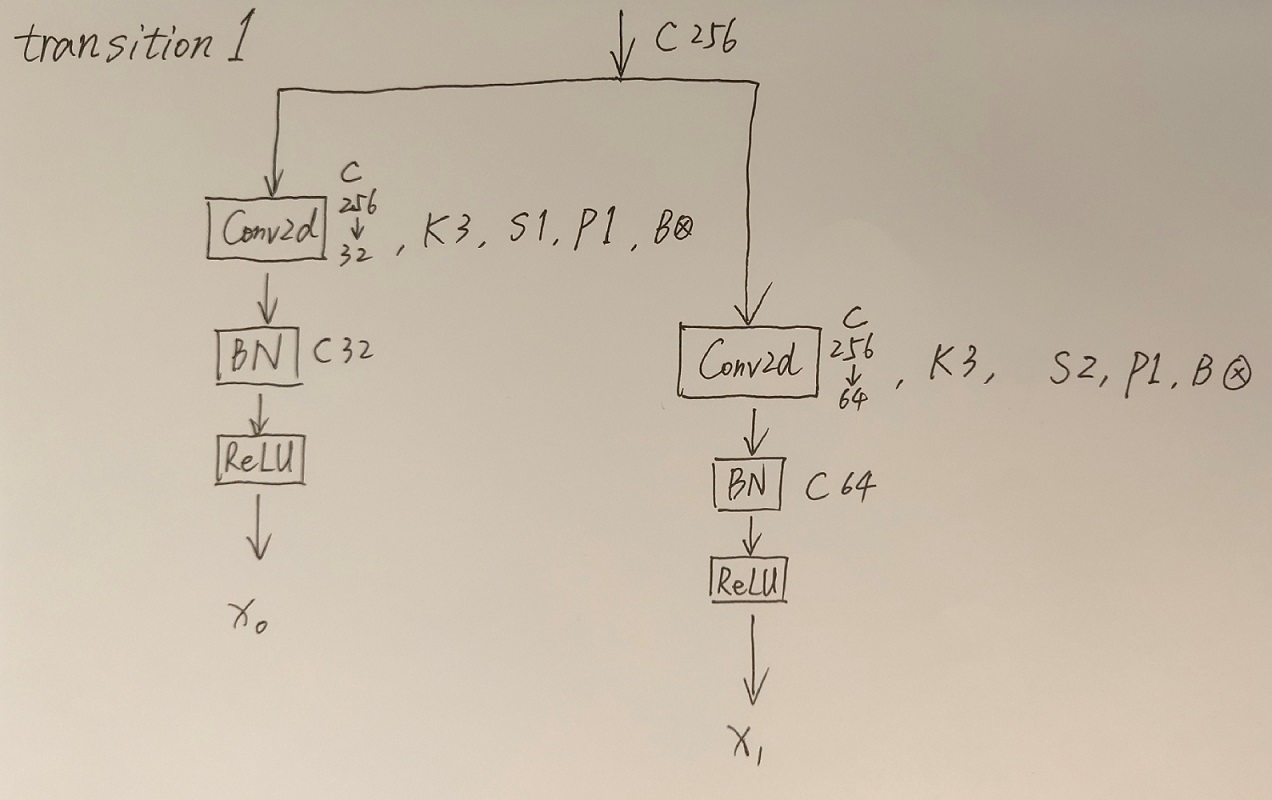
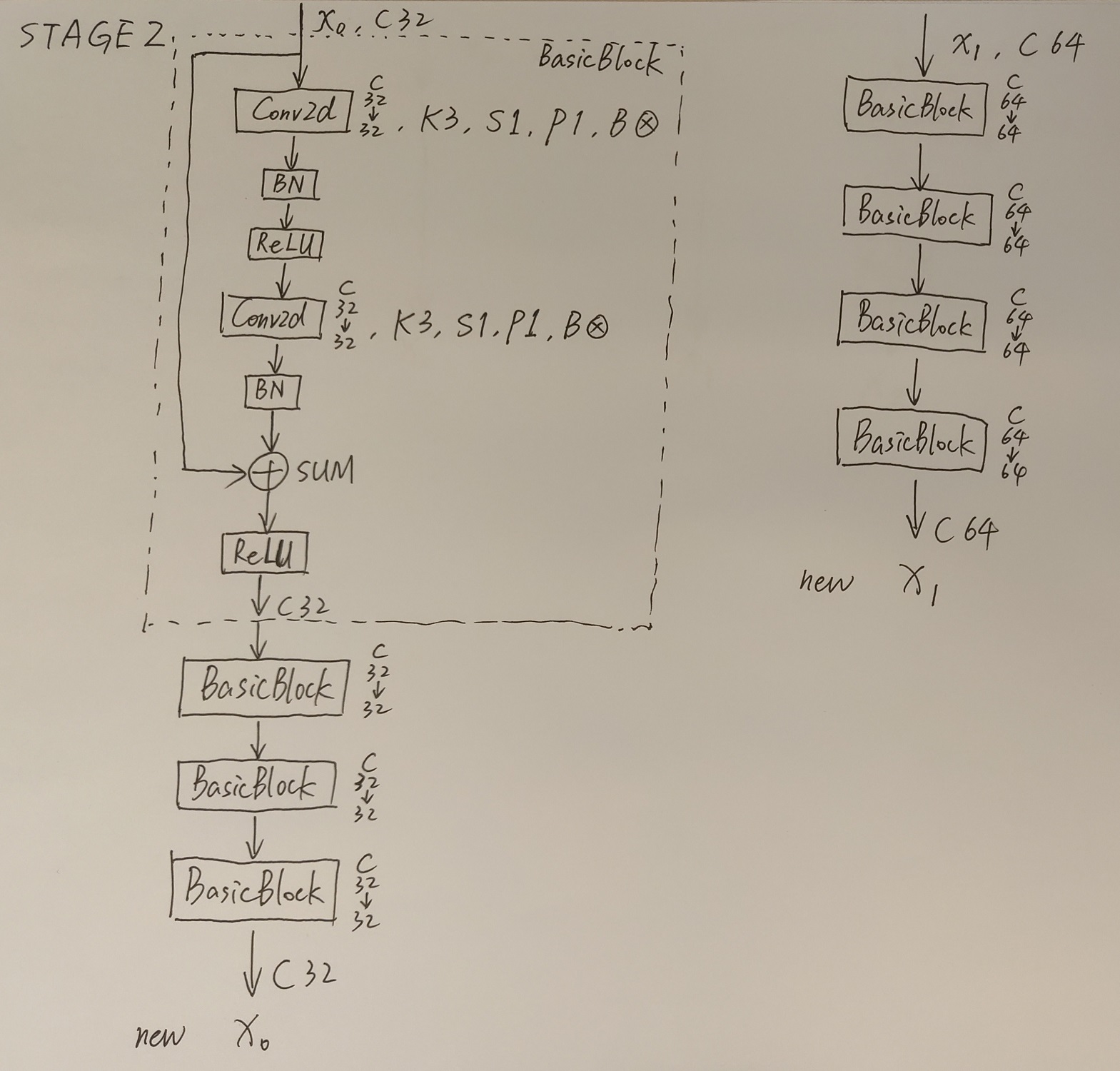


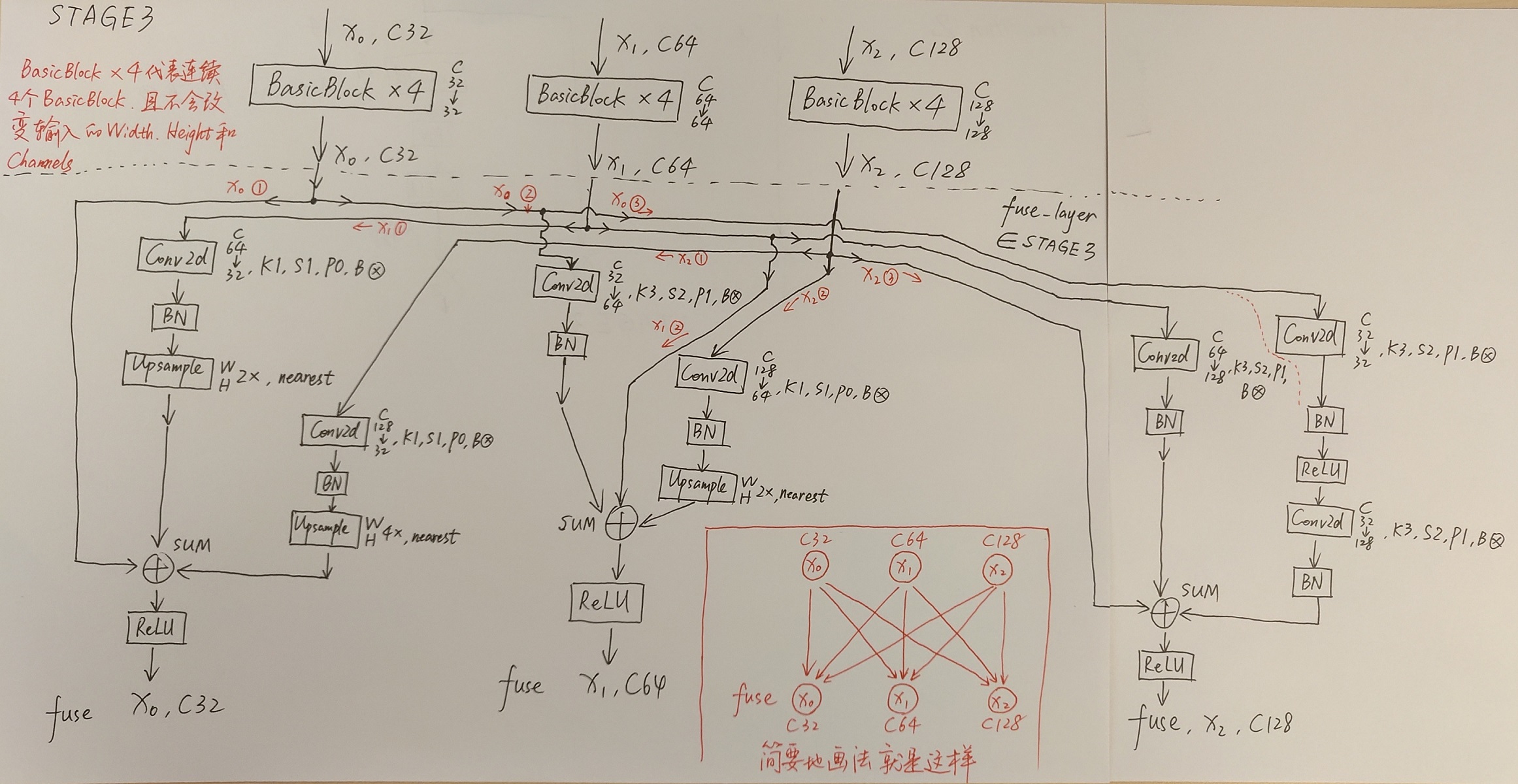
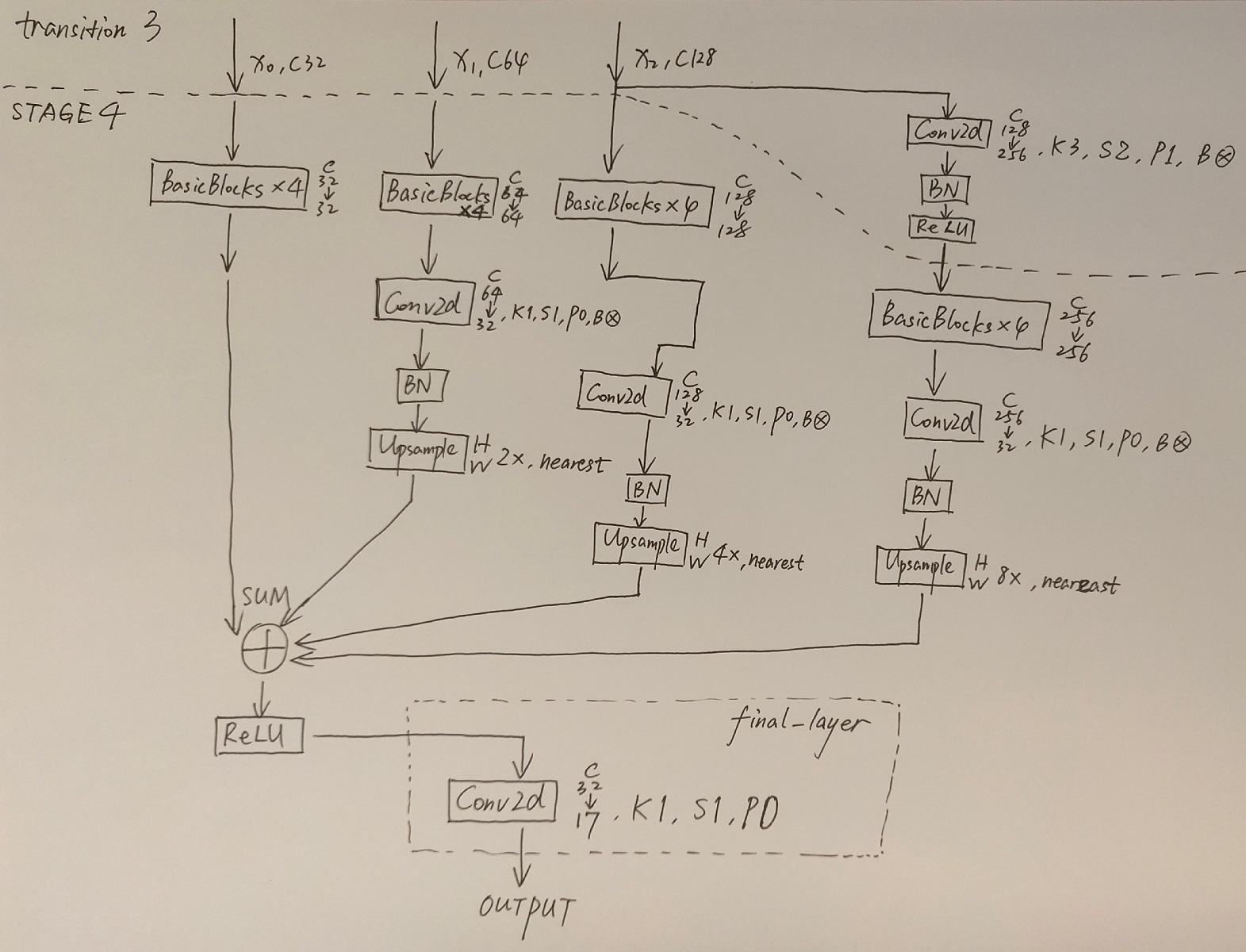
画完之后,我也和High-Resolution Representations for Labeling Pixels and Regions这篇论文中的Figure 1比对了一下,确认是对的上的。