

桔妹导读:滴滴导航是滴滴出行旗下基于丰富的交通大数据和领先的算法策略,面向网约车及自驾场景而打造的一款技术领先的地图产品。伴随着海量网约车司机每日8小时+的导航使用,产品积累了大量的反馈并持续优化打磨。在这个过程中,为了给用户带来更好的地图导航体验,团队一直在积极探索技术上的突破和实践,并取得了一定的成果。今天,我们将会对其中的MJO三维全景导航(行业唯一)、导航主辅路偏航识别及深度学习在端上抓路应用这三个技术点给大家展开讲解。
1. MJO三维全景导航
▍1.1 应用背景
对于绝大多数驾驶者使用2D导航地图,都会出现立交上认错路口,高速上错过匝道,不知何时该并线的问题。路口图形诱导的出现,一定程度上缓解了路口偏航的问题。业内通俗几种做法,如下图:

从左到右顺序:
- 实景图:基于现实建模,但是只展示了一个角度的图像,成本过高。
- 模式图:1对多的映射关系,跟现实路口形态道路弯曲度差异会很大。
- 矢量大图:基于2d道路属性制作,算法驱动可以上量。
- 街景大图:路口和街景图像做挂接,然后叠加引导箭头。依赖街景采集成本巨大。
- 卫星大图:路口真实但只有2D视角。
上述所有方案都只能静态展示,而且不能精确区分车道。滴滴地图中的MJO导航技术,通过加入与实景图同级别的精细场景模型,准确表达复杂桥区的层次穿越关系。极大地降低了读图成本。
三维全景导航的技术难点在于模型复杂度高,数据量较大,相比2D导航地图需要更多的CPU和GPU资源支持。为了在更广泛的设备上实现该功能,需要大幅优化资源的内存、CPU及GPU消耗。
▍1.2 数据压缩
较大的模型尺寸带来了网络传输的压力,对数据压缩提出了较高的要求。原始数据全国总量高达41G,无法适应移动端的内存需求。性能攻坚阶段,团队融合了多种压缩技术进行优化:
- 纹理压缩
- 提取共享资源
- 模型压缩
- 格式二进制转换
- 次要模型过滤
▍1.3 Metal/Vulkan技术
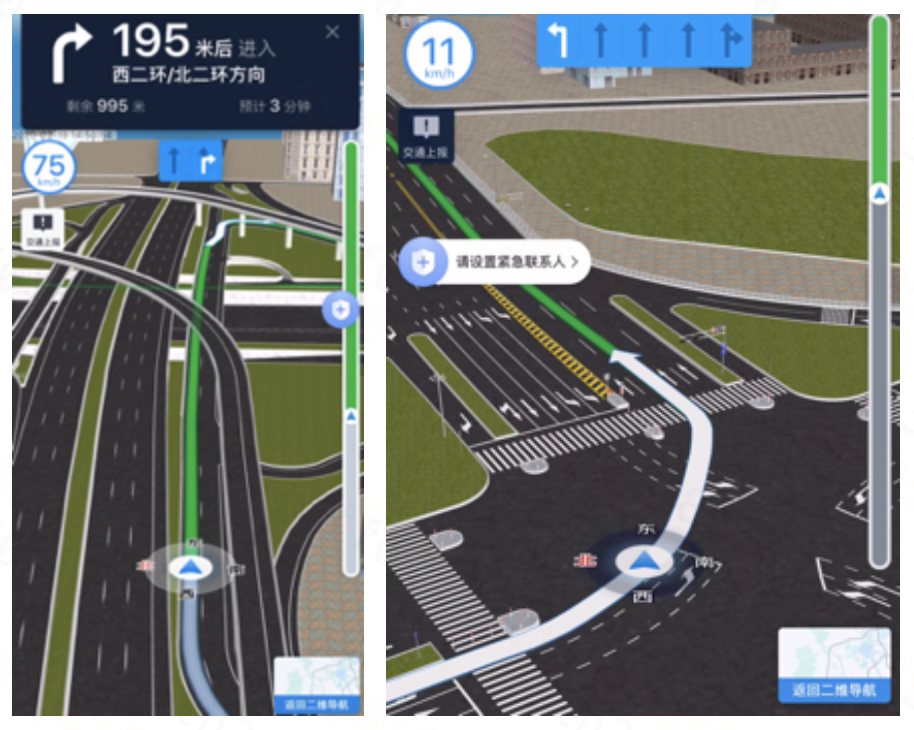
滴滴渲染引擎引入了下一代的图形API,Metal及Vulkan技术。苹果宣称Metal可以提供10倍于OpenGL的性能,而Vulkan则是由khronos组织提出的开放标准,可以支持Apple以外的平台。对比传统的OpenGL ES技术,Metal/Vulkan更加贴近底层硬件,可以更精确地控制GPU,有着更好的线程模型。Metal和Vulkan可以支持更多的draw calls,非常适合应用于MJO这种模型数量较多的场景。通过适配Metal/Vulkan,解决了渲染引擎中shared context的兼容问题,提高了多线程加载的性能,对整体性能和稳定性都有了较大的提升。▍1.4 渲染性能优化由于模型数据量较大,数据加载耗时,使用传统的加载方式会造成明显的卡顿问题,影响用户体验。通过利用Metal/OpenGL ES/Vulkan的多线程技术,资源加载使用了独立的加载线程。加载过程对渲染线程没有直接影响,使程序更加流畅。渲染场景的管理采用了八叉树技术,用于快速选取可见元素,降低渲染负载。对比顺序遍历的O(N)复杂度,八叉树降到了O(logN)。
MJO原始模型粒度较细,一个桥区包含2000多个模型,如果直接进行渲染会造成draw call数量过多,每个draw call都会产生额外的消耗。通过材质合并模型后,draw calls降低到40多个,大幅降低了渲染和内存消耗。

▍1.5 导航实现
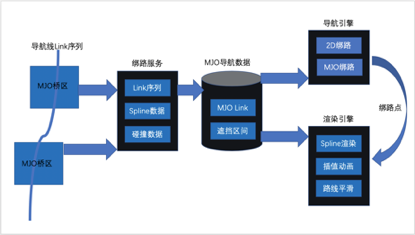
MJO导航虽然提供了高精度的道路模型和车道级的导航线数据,但由于移动端设备并不包含高精度的定位设备,需要利用现有的2D导航逻辑,将GPS点映射到MJO的导航线上。具体步骤如下:
-
根据2D导航的link序列过滤出经过MJO桥区的部分
-
绑路服务计算映射出的MJO link序列并拼装MJO导航线
-
MJO导航线和GPS点传入导航引擎,计算出MJO中的绑路点
-
MJO导航线传入渲染引擎,经过Bezier插值进行平滑处理并渲染
-
绑路点在导航线上进行投影得到3D高度,并插值成平滑移动的动画进行渲染
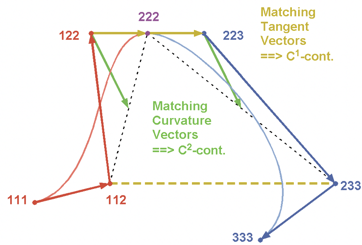
 其中平滑算法使用了Bezier插值,p1 p4是曲线端点,p2 p3用于控制形状,t是插值参数。
其中平滑算法使用了Bezier插值,p1 p4是曲线端点,p2 p3用于控制形状,t是插值参数。
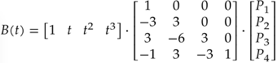
导航线由多个点构成,端点可以从导航线中直接得到。中间的2个控制点需要进行计算。这里的技术要点是保证连接两段线的切向一致(C1连续),在平滑的同时保证曲率不要过分偏离端点。团队通过优化参数和算法,得到了比较满意的效果。
▍1.6 总结
MJO涉及了多种渲染及建模相关的技术,范围广难度高。团队在有限的人力和时间预算条件下,攻克了多个技术难点,实现了一套完整的动画诱导方案。极大地降低了驾驶过程的瞬时读图成本,有效地缓解了复杂路口的偏航问题。
2. 滴滴主辅路偏航识别的应用实践
偏航是车辆实际行驶路线偏离了原定规划路线的行为,而偏航识别用以确定车辆是否偏航,对偏航重新规划行驶路线。主辅路作为特殊的道路场景,其由于平行的特殊性,导致主辅路偏航较一般偏航更具有挑战性。本文将介绍滴滴在主辅路偏航识别上的一些探索和实践。
▍2.1 应用背景
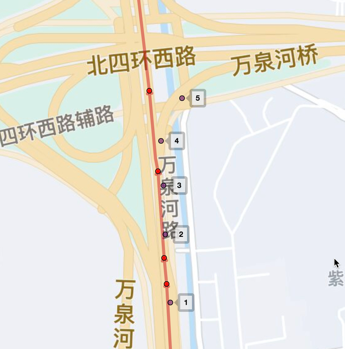
偏航是车辆实际行驶路线偏离了原定规划路线的行为,如图1所示,红色的是规划路线,带偏航的点是车辆gps点,整体轨迹上来看车辆已经偏离了规划路线,则为偏航。
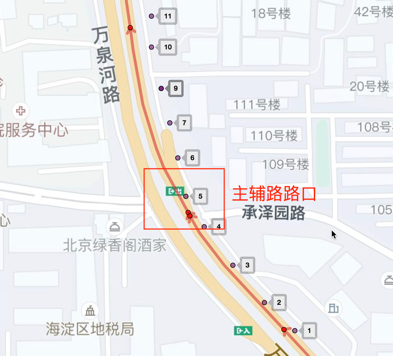
而主辅路偏航场景如图2所示,车辆在图中红框路口处车辆由主路切换到了辅路,则为一次主辅路偏航。
▍2.2 主辅路偏航识别难点
偏航识别作为典型的二分类问题,通常会使用有监督学习的模型求解。由于主辅路的特殊性,有监督学习的标签就成为整个技术方案的难点。
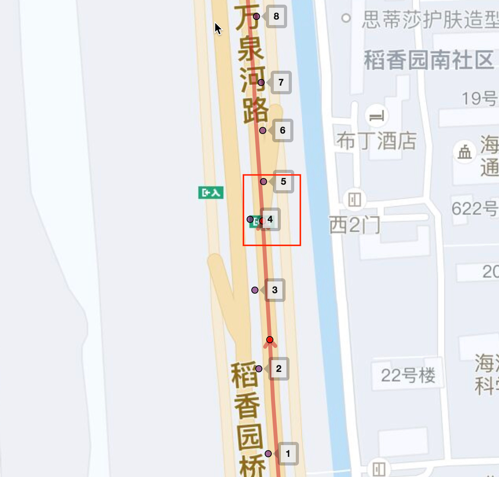
图3 主辅路轨迹如图3的轨迹,车辆在主辅路附近有一个偏移动作,但是单纯从轨迹上很难辨别车辆是切换了个车道还是有主辅路切换,无法单纯从轨迹上是无法获得真值。因此,需要引入额外的信息,而滴滴拥有广大司机上报的图像数据就是一个很好的补充。除了标签这个核心问题外,还有一些主要问题:
- GPS点漂移:GPS点受信号强弱等影响,会出现位置偏差。主辅路场景下,主辅路之间距离不会很远,则GPS的位置偏差会更容易造成误判。
- 路网形状偏差:地图数据往往用有向线段表示客观道路,但是数据探查录入等原因,和客观世界道路位置形状会有偏差,给识别带来难度。
为了解决以上问题,提升用户主辅路偏航上的体验,我们提出了一种基于图像识别的主辅路偏航识别系统。
▍2.3 技术方案
2.3.1 整体方案设计
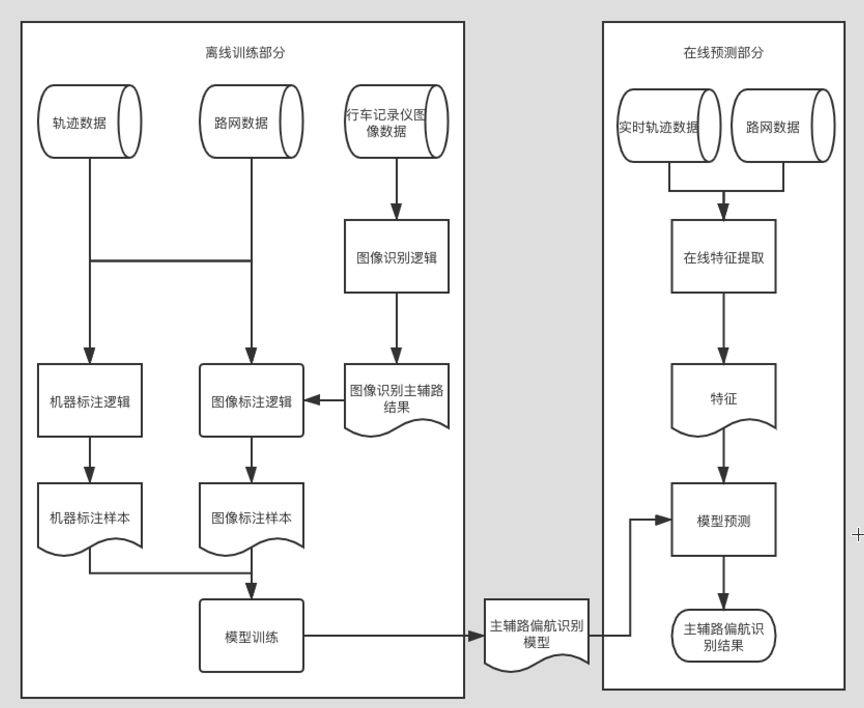
整体方案如图4,主辅路偏航识别整体方案涉及到左侧的离线模型训练部分和在右侧线预测部分,其中离线训练主要包括:
- 机器标注逻辑 根据轨迹和路网连通性进行标注的样本。由于存在路网连通性的约束,因此标注结果准确率高,但是路型覆盖会有局限
- 图像标注逻辑 根据司机上报图像识别车辆在行为(车辆在主路/在辅路,或序列模型识别主辅路切换动作),结合轨迹和路网数据生成样本。因为不受路网形态约束,因此路型覆盖会更全;但是由于需要对路面图像进行图像识别,依赖图像识别的准确率,存储和计算成本较高
- 模型训练 将机器标注样本和图像标注样本进行合并后进行训练,由于图像标注样本成本更高,所以会对图像样本用一些上采样方式。
在线预测部分就是标准的线上预测流程,不做过多赘述。
2.3.2 机器标注逻辑
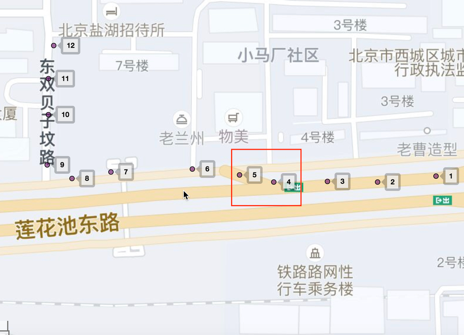
机器标注逻辑是根据轨迹和路网连通性进行标注的逻辑。如图5所示,轨迹有拐入“东双贝子坟路”,但是主路根据路网连通性是不可能拐入的,因此可以推断在红框路口处,车辆从主路切换到了辅路。通过路网连通性的规则能很容易的筛出这类样本,且这类样本准确性极高。
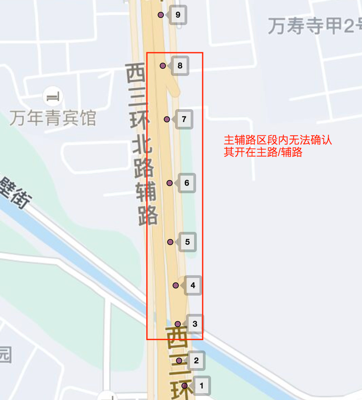
但是机器标注逻辑的局限也很明显,就是诸如图6的轨迹,机器标注是无法确认红框的主辅路区间内车辆是开在主路或辅路的。以北京的轨迹为例,机器标注能处理的路口小于30%,如果仅使用这部分样本进行训练,会因样本有偏导致效果不理想。
2.3.3 图像标注逻辑
滴滴拥有司机上报的图像数据,可以根据图像识别司机行为(车辆在主路/在辅路,或主辅路切换动作),再结合轨迹和路网数据,生成图像标注集合。

如上图是一个图像数据示例,序号表示其序列关系,由图所示,车辆由辅路切换到了主路。图像识别使用了两套逻辑:
- 单图识别序列中对每张图片进行识别,给出其分类结果,类别包括:高架上主路、高架下主路、高架下辅路、主路、辅路。然后根据序列的分类结果,只要有类别的连续性变化视为切换行为,如序列(主路、主路、辅路、辅路)就可以视为切换。
- 序列识别根据图片序列识别是否有主辅路切换动作。采用端到端的注意力与类别层级融合损失约束模型进行特征学习与计算;为了更好的利用序列的语义信息,将主辅路单图特征集成到序列模型中,进行序列约束,识别序列结果。
序列模型准确率更高,但是对于图像序列要求较高(比如时间间隔不能太长);单图识别的召回更高,但是在有遮挡或高架下场景表现不好。将两个模型的结果进行融合,引入司机轨迹、路网数据得到最终的图像标注结果。图像标注结果的准确率在93%以上。
2.3.4 模型训练
由于线上只能使用到轨迹和路网的数据,因此使用特征主要分为以下几类:
- 点特征:GPS点的特征,包括坐标、速度、方向等
- 道路(link)特征:包括道路属性(国道等)、车道数、道路方向等
- 点-link特征:包括点方向同道路方向角度差、点到道路的距离等
- 序列特征:包括当前点同上一个点的角度差、距离差,以及累计角度变化等
同时,针对GPS点信号不准确漂移的情况,使用卡尔曼滤波对原始GPS点位移,减少个别点漂移对于模型的影响;针对整段轨迹漂移,使用Frechet距离衡量其形状相似度,加入到特征中。针对路网形状偏差,使用历史轨迹统计的方式(热力图),对原始路网进行平移、弯曲等形状变化。偏航是典型的二分类问题,初版模型使用Xgboost快速上线,目前在进行Wide&Deep和LSTM等模型的尝试。
2.3.5 效果评估
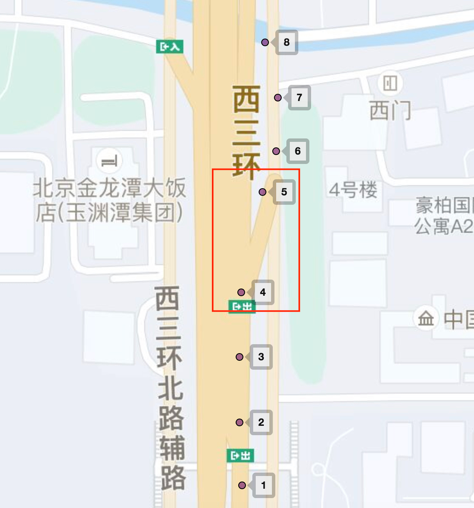
随机抽取了2000个司机上报的图像数据,对经过的主辅路路口进行人工标注其主辅路切换行为,为人工标注集。同时,人工只根据轨迹信息进行判定轨迹行为,识别拐弯的准确率92%、召回率91%。形成这类问题的主要原因是估计漂移,如图7的轨迹,人工如果只根据轨迹判断,会认为车辆在路口由主路切换到辅路,但是根据图像可以确认其一直在主路上。
在人工标注集上的识别拐弯的准确率88%、召回率89%,接近人工只根据轨迹的判定的准召,但是还有一定提升空间。
▍2.4 总结
主辅路偏航作为偏航识别里的特殊类型,由于其平行的特殊性,给识别带来了较大的挑战。本文介绍了滴滴在主辅路偏航识别上的一些探索和实践,借助滴滴的数据优势,建立了一套依赖图像识别的主辅路偏航真值标注体系,并在最后主辅路偏航识别取得了预期的效果。
3. 深度学习在偏航引擎前端的探索和实践
▍3.1 导读
导航作为地图出行的核心场景,根据起终点、路线数据及路况信息为用户定制出行方案。导航为用户提供规划路径,但现实出行中充满变数,用户随时可能有意或无意中偏离原始规划路线。这个时候,及时且智能化的提示显得尤为重要。偏航引擎,负责实时跟踪用户位置,检测用户是否偏离规划路线,并提供及时可靠的偏航提醒,发起新的路线规划请求等;在实际行驶的过程中,偏航提示对用户必不可少,其准确率和及时性对用户体验至关重要。
▍3.2 传统偏航算法
传统偏航算法,通常基于地图匹配(map matching)和垂直场景下的特定规则来进行偏航判定。
地图匹配是将一系列有序的用户或者交通工具的位置关联到地图路网上的过程。因为GPS给定的用户位置往往会有误差,如果不进行地图匹配,可能并不会显示在路网上。在实际应用中,基于隐马尔可夫模型(HMM)的地图匹配就有比较良好的效果。
偏航判定基于地图匹配的结果(匹配到特定路网的置信度),以及当前GPS状态信息(位置,方位角,速度,精度等),GPS与匹配点及规划路线之间的关系,同时依据GPS历史轨迹特征,判定用户是否偏离规划路线。
传统的偏航判定往往基于大量人工编码的规则。通常情况下,由于GPS的可靠性并不稳定,偏航准确性与灵敏性存在一定的互斥关系。
为了同时提升两方面的指标,常常需要针对特定场景进行特定的优化。如在轨迹质量较高的时候,可以提高偏航的灵敏度;在轨迹质量较低的情况下,为了提升准确率,相应的降低偏航灵敏度。
另外,由于低质量的GPS在不同的行驶状态下会展现出不同的轨迹特征,我们也可以根据规划路线的特征(如直行,转弯,掉头等),结合GPS轨迹特征(减速,掉头,精度降低等),在垂直场景下设置不同的偏航阈值。
▍3.3 移动端应用深度学习模型
3.3.1 为什么引入深度学习
传统偏航判定中,无论是轨迹质量,还是规则编写都具有较大的局限性。轨迹质量常常依赖于一系列固定的数学公式,难以融入大量GPS特征进行综合考量,其准确性和召回率不尽如人意。偏航规则随着产品迭代日渐复杂化,变得难以维护,特别是面对人员迭代,更是难以处理。基于偏航判定问题的特征,我们尝试在端上引入深度学习模型。通过自动化的模型学习,为偏航判定提供更加统一和简单的特征指标,简化编码逻辑和维护代价,提升偏航准确性和灵敏度。
3.3.2 移动端应用深度学习算法的限制
-
推算性能
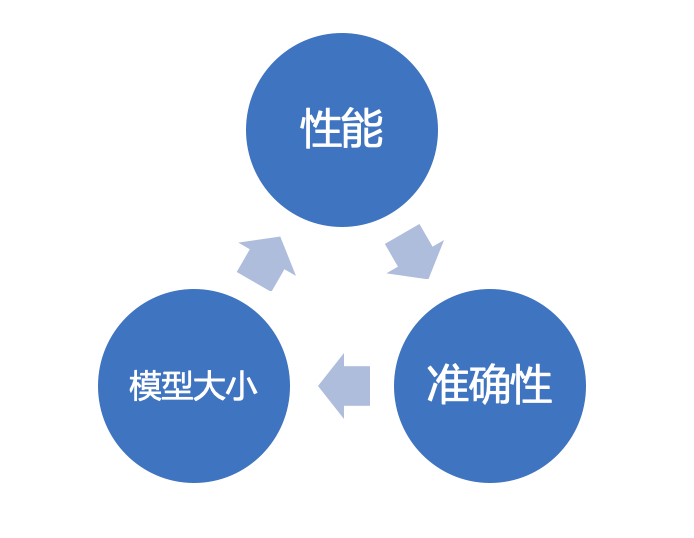
由于前端机型种类繁多,性能参差不齐。考虑兼容性,做模型推算时往往中低端机型为准。采用相关算法库需要针对arm处理器做相应的优化。 -
模型大小
移动端特别是地图对App大小通常较为敏感。深度学习的应用需要引入算法库及模型文件,如果使用开源库文件,可能需要做适当的剪裁;或者根据最终引入的模型结构定制相应的算法库,从而控制库文件大小。另外,针对不同的模型类型、深度及输入特征,模型大小会产生较大的变化,最终选择的模型可能并非最好,但综合而言最为合适即可(比如200k模型比100k模型准确率提升0.2%,可能我们仍然会选择100k模型)。 -
算法限制
使用特定第三方算法库如tensorflow lite,不支持部分运算符等。事实上,移动端应用深度学习也是一个多方权衡的过程,最终的目标是实现性能,模型大小,准确性等指标的理想平衡。
▍3.4 GPS轨迹质量模型
前面提到,轨迹质量对于高灵敏度的偏航判定尤为重要。但基于规则的方法能够提取的高质量GPS轨迹,在保证准确率的前提下,召回率往往较低。在偏航场景下,利用深度学习的方式来做质量判定,我们需要重新定义该问题。
3.4.1 问题定义及样本标准
如果以GPS偏离路线的距离或角度来认定轨迹质量的优劣,标准会变得比较模糊。如此一来会大大增加样本的采集的难度和统一性。此外,轨迹质量的判定与偏航判定不具有相关性,最终能否对偏航指标带来提升存在很大的不确定性。
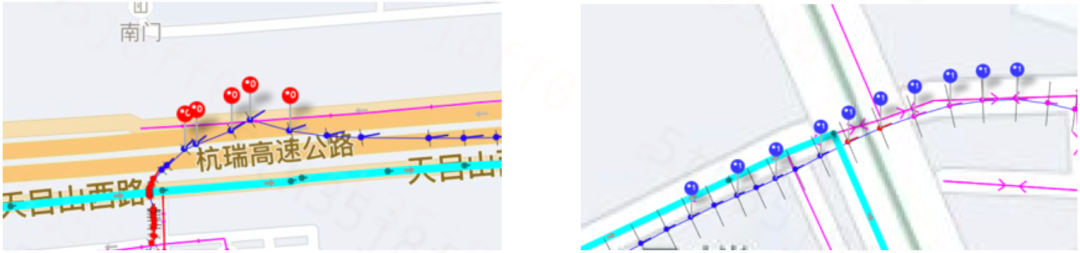
从偏航判定的角度出发,我们认为在人工校验下:
-
发生误偏航的GPS点,其轨迹质量基本是不可靠的(以上左图)。
-
偏航灵敏度较低,但足以判定为偏航的情形,其轨迹质量是可靠的(以上右图)。
-
为排除干扰,将GPS点聚集等不影响偏航判定的情形,归类为其它;
于是我们的问题转化为简单的多分类问题。
3.4.2 特征工程
GPS轨迹质量模型中,我们提取了两类样本特征。分别为原始GPS属性(速度,时间,方位角,精度等),和人工属性(距离,几何角,角变量,积分推算偏移等)。部分人工属性的提取虽然不能提升模型的准确率上限(比如在特定模型下适当增加神经元数量,可以以较少的属性达到较多属性的准确率),但却能降低模型复杂度,从而降低模型大小,提升性能。这对于移动端而言是非常有益的。
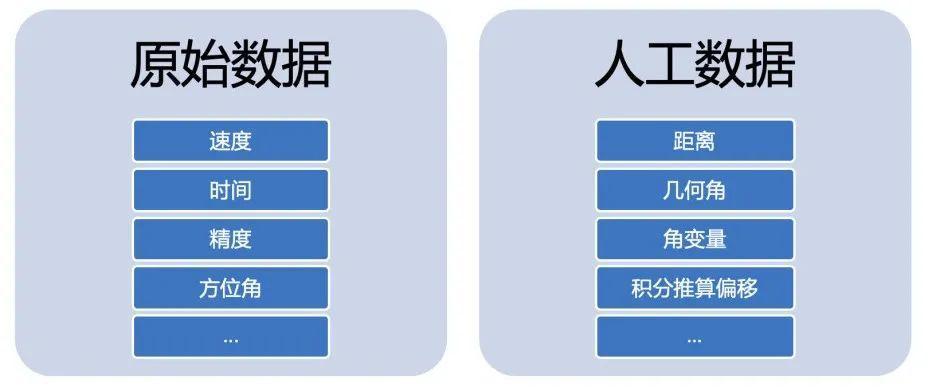
对于低重要度的特征,最终做了删除,从而降低模型大小。例如我们发现方位角的重要度在实际模型训练中不如角变量。推测方位角本身的不连续性(0 = 2pi)可能对模型训练是一种干扰。
对于异常值,做了基本的数据清洗,如无效的速度值,无效的方位角;对于不足的GPS序列长度,用0进行填充(但需要额外注意起点属性)等。
3.4.3 模型选择、训练与效果
DNN:只需要相对简单的算法实现,引入较小的模型库。然而GPS轨迹数据具有典型的时间序列特征,在4万样本下,应用利用DNN模型调参优化后,训练结果准确率最高达到91%。Bad case中存在大量时间不敏感的情形,最典型的情形就是——轨迹由差转优时,判定结果未能及时转变为高质量。
CNN:这里可以尝试两种实现方式,一种是通过生成bitmap进行识别,然而GPS跨度不确定性较高,方向性不易表达,在实现上具有一定困难。第二种将序列化数据转化为二维数组,C模型能够识别出前后时间戳之间的变化特征,但并不能保留更长的时间的变化特征。最终训练出的准确率在93%左右。另外,CNN模型应用在移动端有一个明显的缺点,即模型尺寸一般较大。
LSTM(长短期记忆网络):一种特殊的RNN模型,相比前述模型对轨迹质量序列判定有明显优势。在轨迹质量由好转差,或由差转好的识别上具有非常高的灵敏度,使用128个unit能够达到97%的准确率。缺点是LSTM模型训练速度相对较慢,算法库实现相对复杂。
最终我们选择了使用LSTM模型。使用LSTM的训练结果,准确率大幅提升。在剩余3%的错误样例中,很多轨迹在形态上表现出较高的真实性,但却无法同路网进行匹配。理论上通过引入路网属性能够上带来准确率的进一步提升,然而这种数据的耦合脱离了轨迹质量判定的初衷——服务于偏航引擎专家系统,而非直接用于偏航判定。对此我们将会在最后进行更详细的介绍。
3.4.4 移动端性能优化
模型推算性能对于移动端尤为重要。偏航场景下,GPS更新频繁,选择在必要的时候进行模型推算能够避免不必要的计算开销。通常我们会计算当前GPS点与规划路线的偏离度,只有偏离度大于阈值时才会进行轨迹质量判定。
▍3.5 基于深度学习的专家系统探索
轨迹质量模型作为偏航判定的重要依据,能够以较小的代价移植到移动端。如果不考虑前端性能及数据限制,我们完全可以定义整个偏航判定问题,训练相应的偏航模型。然而偏航场景种类繁多,过于复杂,训练出一套通用的偏航模型需要大量的数据,充足的路网信息,和较大的模型存储,这对于移动端而言不太现实。
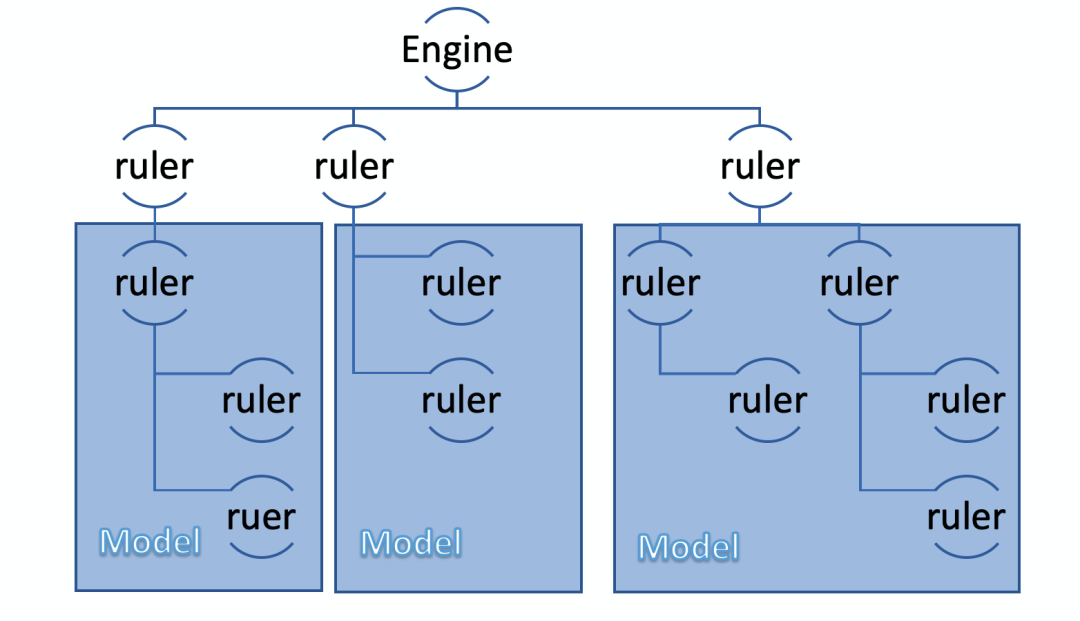
传统偏航算法类似于实现一套基于规则的偏航专家系统。推算过程依赖了大量复杂的规则,这些规则难以概括和抽象为更简单的模块,算法的优化和维护都比较困难。因此我们考虑将偏航场景重新细化分类,依据不同的场景训练相应的偏航模型。例如轨迹质量较差的直行或转弯路线,能够分别能训练出不同的模型。用这些模型替代原有的复杂规则,对移动端而言,可移植性及可控性都会更好。这种基于深度学习的专家系统,是我们接下来完善优化偏航算法的重要方向。
本文作者




延伸阅读



内容编辑 | Charlotte
联系我们 | DiDiTech@didiglobal.com

滴滴技术 出品