目录
0. 摘要
1. nginx内存结构设计
2. nginx内存数据结构
3. nginx内存管理原理
4. 一个简单的内存模型
5. 小结
6. 参考资料
0. 摘要
内存管理,是指软件运行时对计算机内存资源的分配和使用的技术。其最主要的目的是如何高效,快速的分配,并且在适当的时候释放和回收内存资源。
在讲解nginx内存管理之前,先思考以下几个问题。(在小结中会一一回答)
(1)nginx为什么要进行内存管理?
(2)nginx如何进行内存管理?
(3)nginx的内存管理解决了哪些问题?
1. nginx内存结构设计
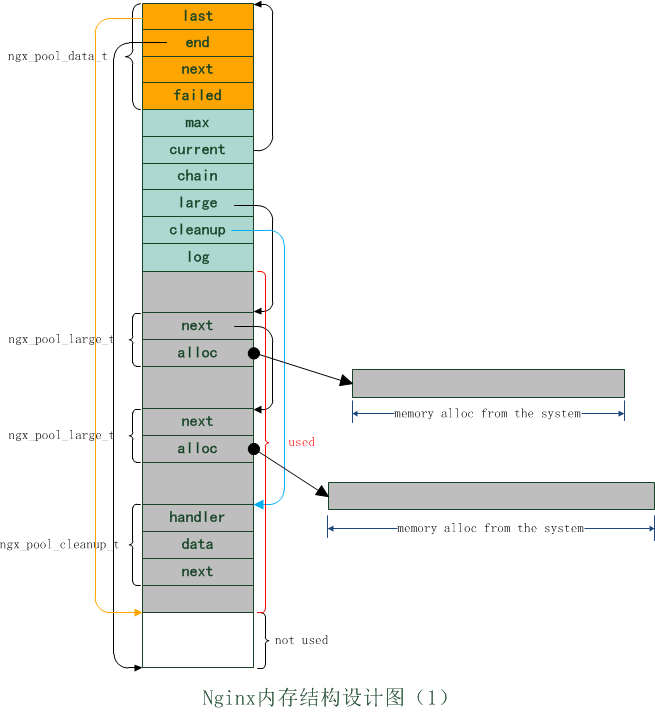
图1.1 nginx内存结构设计图(1)
nginx采用内存池的结构设计来管理内存。内存池是由若干固定大小的内存块组成的单向链表。每个内存块的设计图如图1.1。一个简单的内存池如图1.2
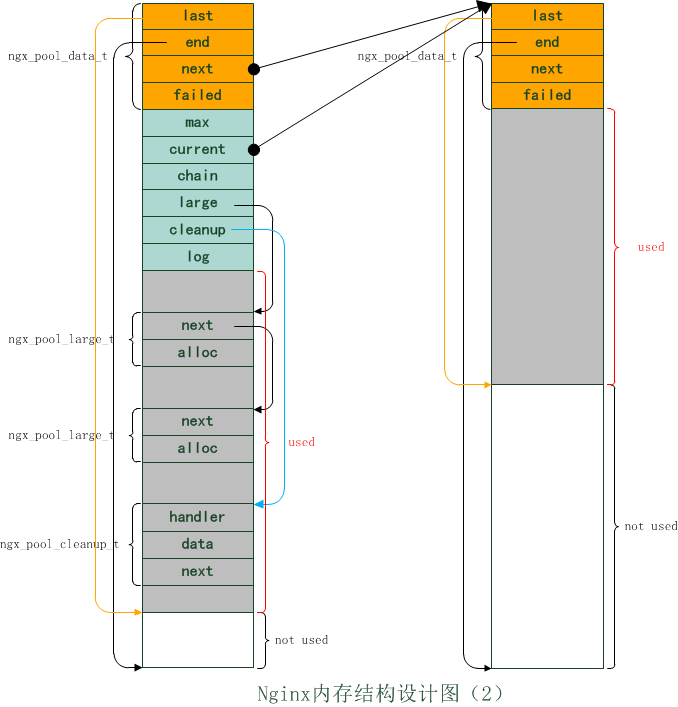
图1.2 nginx内存结构设计图(2)
从图1.2中可以看出,内存池的头结点维护着内存池的总体信息,从头结点开始,可以访问内存池的小块内存(单向链表,由ngx_pool_data_t维护),大块内存(单向链表,由ngx_pool_large_t维护),以及抽象内存数据(单向链表,由ngx_pool_chain_t维护)。内存池结构涉及的具体数据结构在第2节讲解,内存池的管理包括初始化、创建、分配、销毁四部分,在第3节讲解。
2. nginx内存数据结构
2.1 内存池基础数据结构
(1)内存池 ngx_pool_t:负责整个内存池的管理。
1 typedef struct ngx_pool_s ngx_pool_t; 2 struct ngx_pool_s { // 内存池的管理分配模块 3 ngx_pool_data_t d; // 内存池的数据块 4 size_t max; // 数据块大小,小块内存的最大值 5 ngx_pool_t *current; // 指向内存池可用数据块 6 ngx_chain_t *chain; // 该指针挂接一个ngx_chain_t结构 7 ngx_pool_large_t *large; // 指向大块内存分配,nginx中,大块内存分配直接采用标准系统接口malloc 8 ngx_pool_cleanup_t *cleanup; // 析构函数,挂载内存释放时需要清理资源的一些必要操作 9 ngx_log_t *log; // 内存分配相关的日志记录 10 };
(2)ngx_pool_data_t:负责内存池小块数据的管理。
1 typedef struct { // 内存池的数据结构模块 2 u_char *last; // 当前内存分配结束位置,即下一段可分配内存的起始位置 3 u_char *end; // 内存池的结束位置 4 ngx_pool_t *next; // 链接到下一个内存池,内存池的很多块内存就是通过该指针连成链表的 5 ngx_uint_t failed; // 记录内存分配不能满足需求的失败次数,当失败次数大于指定值时 current 指向下一内存池单元 6 } ngx_pool_data_t; // 结构用来维护内存池的数据块,供用户分配小块内存使用。
(3)ngx_chain_t:负责内存池抽象数据的管理,比如缓存数据,文件数据。
1 typedef struct ngx_buf_s ngx_buf_t; 2 struct ngx_buf_s { 3 u_char *pos; // 当buf所指向的数据在内存里的时候,pos指向的是这段数据开始的位置。 4 u_char *last; // 当buf所指向的数据在内存里的时候,last指向的是这段数据结束的位置。 5 off_t file_pos; // 当buf所指向的数据是在文件里的时候,file_pos指向的是这段数据的开始位置在文件中的偏移量。 6 off_t file_last; // 当buf所指向的数据是在文件里的时候,file_last指向的是这段数据的结束位置在文件中的偏移量。 7 /* 当buf所指向的数据在内存里的时候,这一整块内存包含的内容可能被包含在多个buf中(比如在某段数据中间插入了其他的数据,这一块数据就需要被拆分开)。那么这些buf中的start和end都指向这一块内存的开始地址和结束地址。而pos和last指向本buf所实际包含的数据的开始和结尾。 8 */ 9 u_char *start; 10 // 解释参考 start 11 u_char *end; /* end of buffer */ 12 ngx_buf_tag_t tag; 13 ngx_file_t *file; // 当buf所包含的内容在文件中是,file字段指向对应的文件对象。 14 /* 当这个buf完整copy了另外一个buf的所有字段的时候,那么这两个buf指向的实际上是同一块内存,或者是同一个文件的同一部分,此时这两个buf的shadow字段都是指向对方的。那么对于这样的两个buf,在释放的时候,就需要使用者特别小心,具体是由哪里释放,要提前考虑好,如果造成资源的多次释放,可能会造成程序崩溃!*/ 15 ngx_buf_t *shadow; 16 17 /* the buf's content could be changed */ 18 // 为1时表示该buf所包含的内容是在一个用户创建的内存块中,并且可以被在filter处理的过程中进行变更,而不会造成问题。 19 unsigned temporary:1; 20 21 /* 22 * the buf's content is in a memory cache or in a read only memory 23 * and must not be changed 24 */ // 为1时表示该buf所包含的内容是在内存中,但是这些内容确不能被进行处理的filter进行变更。 25 unsigned memory:1; 26 27 /* the buf's content is mmap()ed and must not be changed */ 28 // 为1时表示该buf所包含的内容是在内存中, 是通过mmap使用内存映射从文件中映射到内存中的,这些内容确不能被进行处理的filter进行变更。 29 unsigned mmap:1; 30 31 unsigned recycled:1; 32 unsigned in_file:1; // 为1时表示该buf所包含的内容是在文件中。 33 /* 遇到有flush字段被设置为1的的buf的chain,则该chain的数据即便不是最后结束的数据(last_buf被设置,标志所有要输出的内容都完了),也会进行输出,不会受postpone_output配置的限制,但是会受到发送速率等其他条件的限制。 34 */ 35 unsigned flush:1; 36 unsigned sync:1; 37 unsigned last_buf:1; // 数据被以多个chain传递给了过滤器,此字段为1表明这是最后一个buf。 38 /* 在当前的chain里面,此buf是最后一个。特别要注意的是last_in_chain的buf不一定是last_buf,但是last_buf的buf一定是last_in_chain的。这是因为数据会被以多个chain传递给某个filter模块。 39 */ 40 unsigned last_in_chain:1; 41 42 unsigned last_shadow:1; 43 unsigned temp_file:1; 44 45 /* STUB */ int num; 46 };
(4)ngx_pool_large_t:负责内存池大块数据(size>max)的管理,大块内存直接实时向系统申请。
1 typedef struct ngx_pool_large_s ngx_pool_large_t; 2 struct ngx_pool_large_s { 3 ngx_pool_large_t *next; 4 void *alloc; 5 };
(5)ngx_pool_cleanup_t:负责内存池数据的回收。引用:“cleanup字段管理着一个特殊的链表,该链表的每一项都记录着一个特殊的需要释放的资源。对于这个链表中每个节点所包含的资源如何去释放,是自说明的。这也就提供了非常大的灵活性。意味着,ngx_pool_t不仅仅可以管理内存,通过这个机制,也可以管理任何需要释放的资源,例如,关闭文件,或者删除文件等。”从这点来说,本篇文章确切地说,应该是资源管理,而不只是内存管理。
1 typedef void (*ngx_pool_cleanup_pt)(void *data); 2 typedef struct ngx_pool_cleanup_s ngx_pool_cleanup_t; 3 struct ngx_pool_cleanup_s { 4 ngx_pool_cleanup_pt handler; // 函数指针 5 void *data; // 实际数据 6 ngx_pool_cleanup_t *next; 7 };
(6)ngx_log_t:当内存池数据操作出现错误(一般是申请失败)时打印日志。
1 typedef struct ngx_log_s ngx_log_t; 2 struct ngx_log_s { 3 ngx_uint_t log_level; 4 ngx_open_file_t *file; 5 ngx_atomic_uint_t connection; 6 ngx_log_handler_pt handler; 7 void *data; 8 /* 9 * we declare "action" as "char *" because the actions are usually 10 * the static strings and in the "u_char *" case we have to override 11 * their types all the time 12 */ 13 char *action; 14 };
2.2 内存池主要基本操作
(1)创建内存池:ngx_pool_t *ngx_create_pool(size_t size, ngx_log_t *log);分配一个内存页,并初始化相应字段。
ngx_pool_t * ngx_create_pool(size_t size, ngx_log_t *log) { ngx_pool_t *p; p = ngx_memalign(NGX_POOL_ALIGNMENT, size, log); if (p == NULL) { return NULL; } p->d.last = (u_char *) p + sizeof(ngx_pool_t); p->d.end = (u_char *) p + size; p->d.next = NULL; p->d.failed = 0; size = size - sizeof(ngx_pool_t); p->max = (size < NGX_MAX_ALLOC_FROM_POOL) ? size : NGX_MAX_ALLOC_FROM_POOL; p->current = p; p->chain = NULL; p->large = NULL; p->cleanup = NULL; p->log = log; return p; }
(2)分配内存:void * ngx_palloc(ngx_pool_t *pool, size_t size); 根据size大小决定具体行为:a.在当前内存页分配 b. 在新内存也分配 c. 向系统申请大块内存
1 // ngx_palloc和ngx_pnalloc都是从内存池里分配size大小内存,至于分得的是小块内存还是大块内存,将取决于size的大小; 2 // 他们的不同之处在于,palloc取得的内存是对齐的,pnalloc则否。 3 void * 4 ngx_palloc(ngx_pool_t *pool, size_t size) 5 { 6 u_char *m; 7 ngx_pool_t *p; 8 9 if (size <= pool->max) { 10 p = pool->current; 11 do { 12 m = ngx_align_ptr(p->d.last, NGX_ALIGNMENT); 13 if ((size_t) (p->d.end - m) >= size) { 14 p->d.last = m + size; 15 return m; 16 } 17 p = p->d.next; 18 } while (p); 19 //如果遍历完整个内存池链表均未找到合适大小的内存块供分配,则执行ngx_palloc_block()来分配。 20 //ngx_palloc_block()函数为该内存池再分配一个block,该block的大小为链表中前面每一个block大小的值。 21 //一个内存池是由多个block链接起来的。分配成功后,将该block链入该poll链的最后, 22 //同时,为所要分配的size大小的内存进行分配,并返回分配内存的起始地址。 23 return ngx_palloc_block(pool, size); 24 } 25 return ngx_palloc_large(pool, size); 26 }
(3)销毁内存池:void ngx_destroy_pool(ngx_pool_t *pool); 分三步走:一,执行cleanup清理;二,释放大块内存;三,释放小块内存(内存页)。
1 #define ngx_free free 2 void 3 ngx_destroy_pool(ngx_pool_t *pool) 4 { 5 ngx_pool_t *p, *n; 6 ngx_pool_large_t *l; 7 ngx_pool_cleanup_t *c; 8 9 printf("ngx_destroy_pool::ngx_destroy_pool:%p ", ngx_destroy_pool); 10 get_systime(buf, 100); 11 // printf("ngx_destroy_pool:%s ",buf); 12 13 // 执行资源(比如文件关闭,删除等)清理函数 14 for (c = pool->cleanup; c; c = c->next) { 15 if (c->handler) { 16 ngx_log_debug1(NGX_LOG_DEBUG_ALLOC, pool->log, 0, 17 "run cleanup: %p", c); 18 c->handler(c->data); 19 } 20 } 21 // 释放大块内存 22 for (l = pool->large; l; l = l->next) { 23 24 ngx_log_debug1(NGX_LOG_DEBUG_ALLOC, pool->log, 0, "free: %p", l->alloc); 25 26 if (l->alloc) { 27 ngx_free(l->alloc); 28 } 29 } 30 31 // 释放小块内存,一个pagesize 32 for (p = pool, n = pool->d.next; /* void */; p = n, n = n->d.next) { 33 ngx_free(p); 34 35 if (n == NULL) { 36 break; 37 } 38 } 39 }
(4)其他:src/core/ngx_palloc.c其他函数说明
1)void ngx_reset_pool(ngx_pool_t *pool);
// 该函数释放pool中所有大块内存链表上的内存,小块内存链上的内存块都修改为可用。但不会去处理cleanup链表上的项目。 // 这说明重置pool只是要利用小块内存资源
2)void * ngx_pnalloc(ngx_pool_t *pool, size_t size);
// ngx_palloc和ngx_pnalloc都是从内存池里分配size大小内存,至于分得的是小块内存还是大块内存,将取决于size的大小; // 他们的不同之处在于,palloc取得的内存是对齐的,pnalloc则否。
3)static void * ngx_palloc_block(ngx_pool_t *pool, size_t size);
// ngx_palloc_block()函数为该内存池再分配一个block,该block的大小为链表中前面每一个block大小的值。 // 一个内存池是由多个block链接起来的。分配成功后,将该block链入该poll链的最后, // 同时,为所要分配的size大小的内存进行分配,并返回分配内存的起始地址。
4)static void * ngx_palloc_large(ngx_pool_t *pool, size_t size);
// 执行ngx_palloc和ngx_pnalloc时,若size>max,则会调用ngx_palloc_large // 新的大块内存将会被挂接到pool->large上,即加入链表头部
5)void * ngx_pmemalign(ngx_pool_t *pool, size_t size, size_t alignment);
// ngx_pmemalign将在分配size大小的内存并按alignment对齐,然后挂到large字段下,当做大块内存处理。 // 内存对齐的好处就是提高了CPU取数据的效率
6)ngx_int_t ngx_pfree(ngx_pool_t *pool, void *p);
// 释放指定大块内存 // 该函数的实现是顺序遍历large管理的大块内存链表。所以效率比较低下。 // 如果在这个链表中找到了这块内存,则释放,并返回NGX_OK。否则返回NGX_DECLINED。 // 由于这个操作效率比较低下,除非必要,也就是说这块内存非常大,确应及时释放,否则一般不需要调用。
7)void * ngx_pcalloc(ngx_pool_t *pool, size_t size);
// ngx_pcalloc是直接调用palloc分配好内存,然后进行一次0初始化操作。
8)ngx_pool_cleanup_t * ngx_pool_cleanup_add(ngx_pool_t *p, size_t size);
// 这个 size就是要存储这个data字段所指向的资源的大小。 // 比如我们需要最后删除一个文件。那我们在调用这个函数的时候,把size指定为存储文件名的字符串的大小, // 然后调用这个函数给cleanup链表中增加一项。该函数会返回新添加的这个节点。我们然后把这个节点中的data字段拷贝为文件名。 // 把hander字段赋值为一个删除文件的函数(当然该函数的原型要按照void (*ngx_pool_cleanup_pt)(void *data);)。
9)void ngx_pool_run_cleanup_file(ngx_pool_t *p, ngx_fd_t fd);
// 对内存池进行文件清理操作,即执行handler,此时handler==ngx_pool_cleanup_file
10)void ngx_pool_cleanup_file(void *data);
// 关闭data指定的文件句柄
11)void ngx_pool_delete_file(void *data);
// 删除data指定的文件
3. nginx内存管理原理
3.1 内存管理初始化
我们知道,在nginx正式进入事件处理流程之前,nginx在主流程中(main函数)会进行一系列的初始化工作,这是为以后的master-worker运行模式准备资源,也为各模块的运行准备条件。同样,在创建一个内存池之前,nginx需要知道程序处在什么样的系统环境中,这些系统变量会影响nginx的内存管理效率。
3.1.1 内存对齐
(1)为什么要内存对齐
内存对齐是操作系统为了快速访问内存而采取的一种策略。因为处理器读写数据,并不是以字节为单位,而是以块(2,4,8,16字节)为单位进行的,而且由于操作系统的原因,块的起始地址必须整除块大小。如果不进行对齐,那么本来只需要一次进行的访问,可能需要好几次才能完成,并且还要进行额外的数据分离和合并,导致效率低下。更严重地,有的CPU因为不允许访问unaligned address,就报错,或者打开调试器或者dump core,比如sun sparc solaris绝对不会容忍你访问unaligned address,都会以一个core结束你的程序的执行。所以一般编译器都会在编译时做相应的优化以保证程序运行时所有数据地址都是在'aligned address'上的,这就是内存对齐的由来。
为了更好理解上面的意思,这里给出一个示例。在32位系统中,假如一个int变量在内存中的地址是0x00ff42c3,因为int是占用4个字节,所以它的尾地址应该是0x00ff42c6,这个时候CPU为了读取这个int变量的值,就需要先后读取两个4字节的块,分别是0x00ff42c0~0x00ff42c3和0x00ff42c4~0x00ff42c7,然后通过移位等一系列的操作来得到,在这个计算的过程中还有可能引起一些总线数据错误的。但是如果编译器对变量地址进行了对齐,比如放在0x00ff42c0,CPU就只需要一次就可以读取到,这样的话就加快读取效率。
综合,内存对齐的原因有2点:
1) 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2) 性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要至少要两次内存访问;而对齐的内存访问仅需要一次访问。
(2)在linux上如何内存对齐
内存对齐可以用一句话来概括:"数据项只能存储在地址是数据项大小的整数倍的内存位置上"。
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。程序员可以通过预编译命令#pragma pack(n),n=1,2,4,8,16 来改变这一系数,其中的n 就是你要指定的“对齐系数”。
规则1:
数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0 的地方,以后每个数据成员的对齐按照#pragma pack 指定的数值和这个数据成员自身长度中,比较小的那个进行。
规则2:
结构(或联合)的整体对齐规则:在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行。
规则3:
结合1、2 颗推断:当#pragma pack 的n值等于或超过所有数据成员长度的时候,这个n值的大小将不产生任何效果。
在这就不展开讨论内存对齐的细节了。
(3)nginx为内存对齐做了哪些
#define NGX_POOL_ALIGNMENT 16 #ifndef NGX_ALIGNMENT #define NGX_ALIGNMENT sizeof(unsigned long) /* platform word */ #endif // 两个参数d和a,d代表未对齐内存地址,a代表对齐单位,必须为2的幂。假设a是8,那么用二进制表示就是1000,a-1就是0111. // d + a-1之后在第四位可能进位一次(如果d的前三位不为000,则会进位。反之,则不会), // ~(a-1)是1111...1000,&之后的结过就自然在4位上对齐了。注意二进制中第四位的单位是8,也就是以8为单位对齐。 // 例如,d=17,a=8,则结果为24.所以该表达式的结果就是对齐了的内存地址 #define ngx_align(d, a) (((d) + (a - 1)) & ~(a - 1)) // 对指针地址进行内存对齐,原理同上 #define ngx_align_ptr(p, a) (u_char *) (((uintptr_t) (p) + ((uintptr_t) a - 1)) & ~((uintptr_t) a - 1))
3.1.2 内存分页
本小节主要解释创建内存池函数中的语句:p->max = (size < NGX_MAX_ALLOC_FROM_POOL) ? size : NGX_MAX_ALLOC_FROM_POOL;该语句限制了内存池可用内存的最大值。也就是说当创建内存池的size>NGX_MAX_ALLOC_FROM_POOL时会造成内存浪费。但nginx为什么会这么做呢?
(1)为什么要内存分页
在存储器管理中,连续分配方式会形成许多“碎片”,虽然可通过“紧凑”方法将许多碎片拼接成可用的大块空间,但须为之付出很大开销。如果允许将一个进程直接分散地装入到许多不相邻的分区中,则无须再进行“紧凑”。基于这一思想而产生了离散分配方式。如果离散分配的基本单位是页,则称为分页存储管理方式。
分页管理器把地址空间划分成4K大小的页面(非Intel X86体系与之不同),当进程访问某个页面时,操作系统首先在Cache中查找页面,如果该页面不在内存中,则产生一个缺页中断(Page Fault),进程就会被阻塞,直至要访问的页面从外存调入内存中。
综上,内存分页管理使得进程的地址空间可以为整个物理内存地址空间(如4G),一个页面经过映射后在实际物理空间中是连续存储的。根据程序局部性原理,如果程序的指令在一段时间内访问的内存都在同一页面内,则会提高cache命中率,也就提高了访存的效率。
(2)nginx内存分页好处
从上可以看出,内存分页管理使得程序向系统申请一个页面的内存时,该页内存地址在物理内存地址空间中是连续分布的,这提高了cache命中率。如果申请的内存大于一个内存页,则会降低程序指令访存cache命中率。所以,在nginx内存池小块内存管理单元中,其有效内存的最大值为一个页面大小。
3.2 内存池的创建
经过测试,nginx在为每个http连接(connection)创建size为256的pool,为每个请求(request)创建size为4096的pool。当客户端使用长连接向服务器请求资源时,nginx完成request后会释放request对应的pool,而不立即释放connection对应的pool,等超时后再释放。在一次简单的会话中(请求首页),连接建立到关闭期间,至少有30次的内存分配(调用ngx_palloc)。
3.3 内存池的分配
从第二节的函数介绍可以看到,nginx内存分配有种形式,小块内存分配包括用户数据、维护内存池链表数据结构数据等,大块数据包括大的资源文件等。
3.3.1 小块内存分配(size<=max)
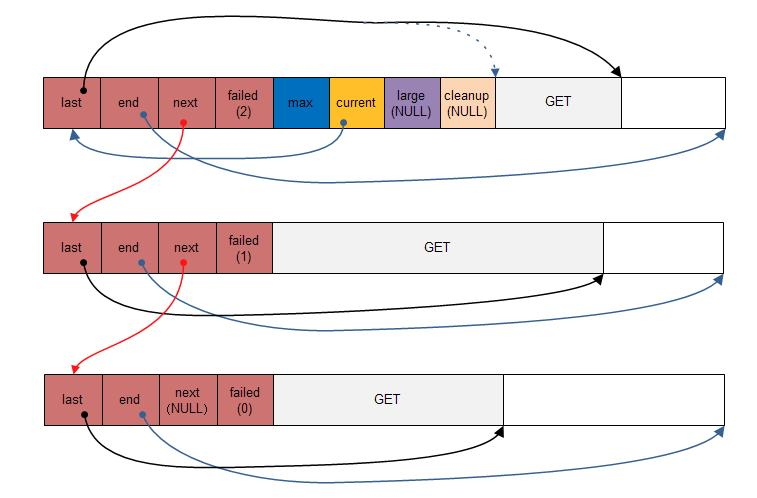
图3.1 nginx小块内存池分配图
上图这个内存池模型是由上3个小内存池构成的,由于第一个内存池上剩余的内存不够分配了,于是就创建了第二个新的内存池,第三个内存池是由于前面两个内存池的剩余部分都不够分配,所以创建了第三个内存池来满足用户的需求。
failed表示的是当前这个内存池的剩余可用内存不能满足用户分配请求的次数,即是说:一个分配请求到来后,在这个内存池上分配不到想要的内存,那么就failed就会增加1;这个分配请求将会递交给下一个内存池去处理,如果下一个内存池也不能满足,那么它的failed也会加1,然后将请求继续往下传递,直到满足请求为止(如果没有现成的内存池来满足,会再创建一个新的内存池)。
current字段会随着failed的增加而发生改变,如果current指向的内存池的failed达到了4的话,current就指向下一个内存池了。猜测:4这个值应该是Nginx作者的经验值,或者是一个统计值。
3.3.2 大块内存分配(size>max)
大块内存的分配请求不会直接在内存池上分配内存来满足,而是直接向操作系统申请这么一块内存(就像直接使用malloc分配内存一样),然后将这块内存挂到内存池头部的large字段下。内存池的作用在于解决小块内存池的频繁申请问题,对于这种大块内存,是可以忍受直接申请的。为什么大块内存分配后是挂在链表头部而不是尾部呢?根据程序局部性原理,最近分配的内存一般经常使用,挂在头部可以提高查找效率。
图3.2展示了大块内存分配情况:
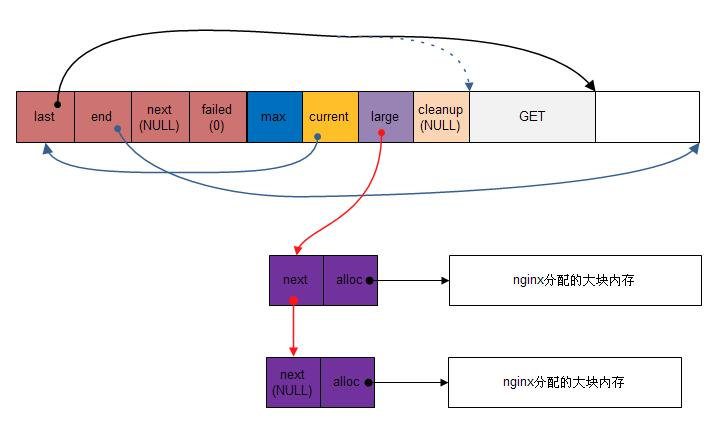
图3.2 nginx大块内存池分配图
注意每块大内存都对应有一个头部结构(next&alloc),这个头部结构是用来将所有大内存串成一个链表用的。这个头部结构不是直接向操作系统申请的,而是当做小块内存(头部结构没几个字节)直接在内存池里申请的。这样的大块内存在使用完后,可能需要第一时间释放,节省内存空间,因此nginx提供了接口函数:
ngx_int_t ngx_pfree(ngx_pool_t *pool, void *p);
此函数专门用来释放某个内存池上的某个大块内存,p就是大内存的地址。ngx_pfree只会释放大内存,不会释放其对应的头部结构,毕竟头部结构是当做小内存在内存池里申请的;遗留下来的头部结构会作下一次申请大内存之用。
3.3.3 资源内存分配
nginx内存池中除了存放物理内存资源,还存放着其他资源,比如文件、缓存等。每个进程能打开的文件句柄是有限的,所以分配了文件资源后需要及时释放。nginx定义了chain和cleanup字段来支持灵活的自主资源分配,这样当连接关闭时,通过销毁内存池就可以一次性回收这次连接占用的系统资源。
图3.3展示了自定义资源分配情况:
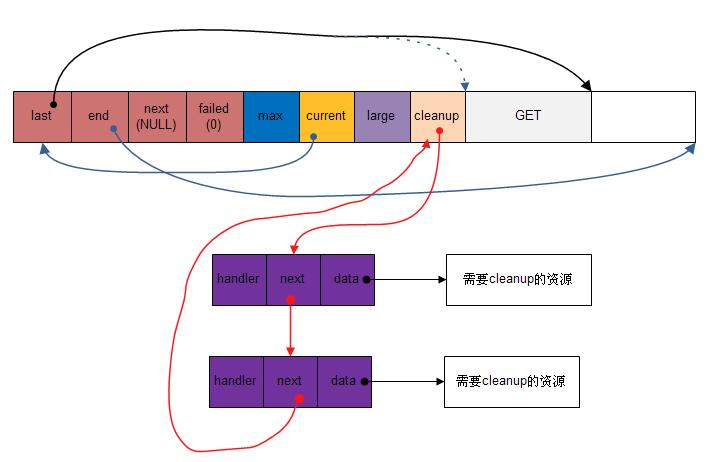
图3.3 nginx自定义资源分配图
可以看到所有挂载在内存池上的资源将形成一个循环链表。
由图可知,每个需要清理的资源都对应有一个头部结构,这个结构中有一个关键的字段handler,handler是一个函数指针,在挂载一个自定义资源到内存池上的时候,同时也会注册一个清理资源的函数到这个handler上。即是说,内存池在清理cleanup的时候,就是调用这个handler来清理对应的资源。
比如:我们可以将一个开打的文件描述符作为资源挂载到内存池上,同时提供一个关闭文件描述的函数注册到handler上,那么内存池在释放的时候,就会调用我们提供的关闭文件函数来处理文件描述符资源了。
3.4 内存池的销毁
一个web server总是不停的接受connection和request,所以nginx就将内存池分了不同的等级,有进程级的内存池、connection级的内存池、request级的内存池。也就是说,创建好一个worker进程的时候,同时为这个worker进程创建一个内存池,待有新的连接到来后,就在worker进程的内存池上为该连接创建起一个内存池;连接上到来一个request后,又在连接的内存池上为request创建起一个内存池。这样,在request被处理完后,就会释放request的整个内存池,连接断开后,就会释放连接的内存池;worker进程退出后就会释放worker级的内存池。因而,就保证了内存有分配也有释放。
通过内存的分配和释放可以看出,nginx内存池的主要作用将小块内存的申请聚集到一起申请,然后一起释放。避免了频繁申请小内存,降低内存碎片的产生等问题。
4. 一个简单的内存模型
学以致用,对源码的学习不能只停留在阅读上,而应该去实践。如果能够对目前的工作有所帮助那就更好了。为此,本人从nginx源码中提取内存管理模块代码,供以后的工作借鉴,参考。
5. 小结
先回答摘要中的问题
(1)nginx为什么要进行内存管理?
1)nginx作为高性能web服务器,在各个环节都必须考虑如何提高性能的问题。
2)《编程珠玑》中文第2版第9章-“代码调优”中讲了一个典型的故事,主要讲Chris Van Wyk花了几个小时把一个3000行的图形程序的运行时间减少了一半,而其中的主要优化就是减少不必要的malloc。这说明malloc操作是很耗时的。
3)使用系统的malloc和free面临几个问题:web服务器对内存的需求有大有小,系统运行久了会产生大量的内存碎片,最终造成内存操作更加耗时直到无可用内存,导致服务器宕机。
(2)nginx如何进行内存管理?
nginx首先将内存池分级:进程级、连接级、请求级;然后按照内存使用情况的不同分类:小块内存、大块内存、自定义资源内存。
进程级内存池通过fork完成创建(fork()创建子进程时,子进程复制了父进程的数据段和堆栈段);根据web server的特点,客户端建立连接时创建连接级内存池(在void ngx_event_accept(ngx_event_t *ev);函数中调用),客户端请求资源时创建请求级内存池(在 void ngx_http_init_connection(ngx_connection_t *c)函数中调用)。
进程在处理http请求过程中需要的内存均在该连接对应的内存池中分配,根据需要的内存大小和资源种类进行不同的分配操作。()
进程在处理完http请求后释放请求级内存池;当连接超时或断开时,释放连接级内存;当进程退出时,销毁该进程占用的所有内存池资源。
(3)nginx的内存管理解决了哪些问题?
1)简化了内存操作:程序员不必担心何时释放内存,当连接释放时,就回收该连接对应的内存池。
2)避免了内存碎片:从外部内存碎片来看,采用一次性申请一个内存页,避免了外部内存碎片;从内部内存碎片来看,对大小内存申请分别管理,提高了内存利用率,避免了内部内存碎片。
3)避免了内存泄露:在同一内存池上进行内存申请和回收,当连接关闭后,不存在没有回收的内存。
4)提高了内存访问效率:充分利用程序局部性原理,结合内存对齐和内存分页机制,有效提高了CPU访存的cache命中率。
6. 参考资料
网络博客及nginx-1.4.0源码。
1. 内存对齐:关于内存对齐问题的一些资料整理 内存对齐
2. 内存分页:基本分页存储管理方式 分页内存和非分页内存区别
3. nginx内存分配:Nginx源码剖析之内存池,与内存管理
4. nginx-1.4.0源码: