前言:在web服务端开发的过程中,redis+mysql是最常用的存储解决方案,mysql存储着所有的业务数据,根据业务规模会采用相应的分库分表、读写分离、主备容灾、数据库集群等手段。但是由于mysql是基于磁盘的IO,基于服务响应性能考虑,将业务热数据利用redis缓存,使得高频业务数据可以直接从内存读取,提高系统整体响应速度。
利用redis+mysql进行数据的CRUD时需要考虑的核心问题是数据的一致性。下面对读写场景的技术方案做个简单说明:
业务数据读操作流程:
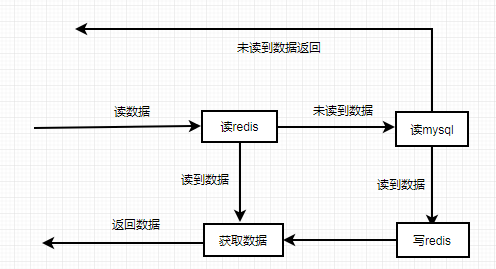
业务数据更新操作流程:
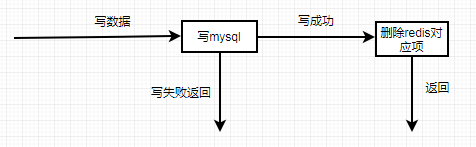

这里采用了mysql数据更新成功后,直接删除redis中对应项的方式。目的是在保证一致性的过程中以mysql中数据为准,redis中的数据始终保持和mysql的同步。
有的方案在这里采用的是更新完mysql成功后,然后进行相应的更新redis中数据的操作。这里的问题是,要考虑到更新的操作可能是并发的,而写mysql和写redis是两个步骤,不是原子性的。例如有线程1和线程2同时进行写操作,执行顺序可能是如下的情况:
线程1写mysql->线程2写mysql->线程2写redis->线程1写redis
这样的话,结果变成了mysql的内容是线程2写入的,而redis的内容是线程1写入的,mysql和redis中的数据就不一致了,后续的数据读取都是错的。
而采用每次写完mysql后就清除redis的方式,就保证了写完后的读取必然会重新从mysql读取数据,然后写入redis。这样就保证了redis里的数据最终和mysql中是一致的,保证了数据的最终一致性。