https://zhuanlan.zhihu.com/p/65086715
本文转自微信公众号CAA模式识别与机器智能专委会
严骏驰
计算机科学与工程系
人工智能教育部重点实验室
上海交通大学
摘要
针对连续时间域上的异步事件序列建模问题,时序点过程已经成为一种重要的解决方法。以机器学习的视角来看,时序点过程的发展可以分为两个方向:传统统计点过程和深度点过程。统计点过程有多种点过程函数形式,其建模的成功往往依赖于正确的模型选择。由于其函数形式和参数表示一般具有一点物理意义,统计点过程具有更强的解释性,对于样本数量的依赖也较小。相比之下,深度点过程(亦被称为神经点过程)利用神经网络的强大容量,通过大规模数据,试图学习拟合能力更强的模型,并减少对先验知识的依赖,而一定程度上牺牲了模型解释性。本文从这两方面对时序点过程的相关进展做初步介绍和梳理,通过若干方法实例对时序点过程做具体技术展示。最后,简要介绍了国际机器学习会议ICML2018的相关tutorial等信息,以及作者近期在IEEE TNNLS期刊上组织的时空点过程专题特刊和在IJCAI19上即将举办的关于时序点过程学习的tutorial。
引言
时序点过程(temporal point process)可以对众多真实场景中产生的数据建模,例如设备故障日志,地震的位置和震级等等。这些数据都是多维异步事件数据,它们互相影响并在连续时间域上呈现出复杂的动态规律。与同步时间序列等间隔采样形成的离散特性不同的是,异步事件的时间戳处于连续时间域。对这些动态过程的研究和其潜在关联的挖掘为微观层面和宏观层面的事件预测、溯源、因果推断等应用奠定基础。事实上,“面向异步序列的类人感知及计算”已经列入国务院印发的《新一代人工智能发展规划》中人工智能基础理论发展的重点任务。而中国工程院重大咨询研究项目“中国人工智能 2.0 发展战略研究”中第四章“跨媒体智能”也就“面向异步序列的类人感知及计算”进行了相关论述。
图1给出了多维异步事件序列的一个示意图,三个用户的行为被表征为不同的事件序列,不同类型的事件由不同形状箭头表征,红色箭头代表事件间前后关联。
尽管基于时间序列的序列模型已经被现有文献广泛研究,比如马尔科夫链,隐马尔可夫模型,向量自回归模型等等,但是对于解决异步生成的连续时间域事件数据问题,时序点过程成为了一个被有效的解决方法。
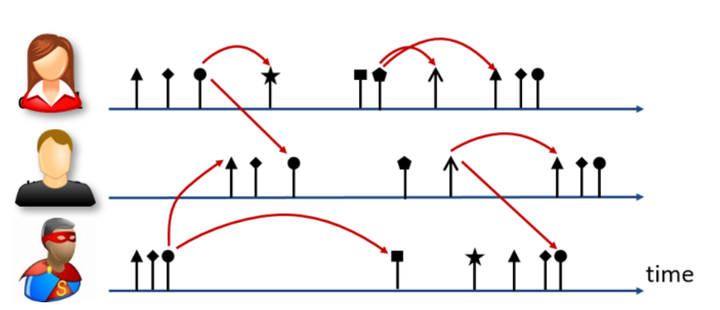 图1. 带类别标记的连续时间域异步事件序列及其相互影响
图1. 带类别标记的连续时间域异步事件序列及其相互影响
1.1时序点过程
时序点过程[1]是在连续时间域上建模的经典数学工具,而其一个常见实例就是事件序列(event sequence)。时序点过程是由连续时间域上的一系列(带标值)事件构成的随机过程。
传统时间序列(time series)模型一般预先设定好时间间隔的长度,将事件序列转换成多段等长的时间间隔,进而对每一段时间间隔内的事件进行聚合并求得特征表示。时序点过程将每一个事件的原始时间戳进行保留并用于建模,从而最大程度上保留了事件序列的时间信息和动态变化模式。事实上,时间序列模型的效果很大程度上受到预先设定的时间间隔长度的影响,即所谓的可塑性面积单元问题[2]。相比时间序列模型,时序点过程模型避免了事件聚合过程中引入的精确时间戳信息丢失。另外,时序点过程模型也不同于马尔科夫链模型,后者的阶数即为要考虑的历史事件数量,阶数过高对建模带来了困难。而时序点过程模型则是可以考虑所有历史事件的影响来实现对历史信息的充分利用。
时序点过程等价于一个计数过程,形式化为N(t),表示时刻t之前发生的事件数量。时序点过程的核心是其条件强度函数,有时可以简称为强度函数,用 表示。给定一个无穷小的时间窗口[t,t+dt),基于时刻t之前的历史事件
,这里 表示时刻
上的标值(例如发生在$$t\_i$$时刻的余震的震级),
表示未来事件的出现几率,形式化定义如下:
其中, 表示基于历史事件
在时间窗口[t,t+dt)内发生事件次数的期望。同很多文献基于的假设一样,我们也假设这是常规点过程[3](regularized point process),也就是不会有两个事件在同一时刻发生,dN(t)∈{0,1}。
,在本文中
表示基于历史事件,即省略给定的条件
得到简写
。不同点过程模型的主要差别就是强度函数形式的不同。感兴趣的读者可以通过参考文献[1]获得关于点过程理论更详细的介绍。
1.2传统统计点过程与深度点过程
时序点过程经常被用于未来事件的预测和因果关联关系的发现,这两个任务一定意义上对应机器学习中的两个核心问题:模型的容量(预测的准确性)和模型的可解释性[4]。时序点过程由传统统计点过程发展到新兴的深度点过程(deep point processes),亦叫神经点过程(neural point processes)。
传统统计点过程中的参数化方法拥有明确的强度函数形式,建模前需要人工预先确定相应的强度函数形式。深度点过程是近两三年才兴起的方向[5][6][7]。相比之下,传统参数化点过程的参数往往对应特定物理意义,其模型的可解释性往往强于深度点过程。另一方面,依靠神经网络强大的容量,深度点过程在挖掘隐藏的事件规律从而对未来事件做出预测的性能上往往要强于传统参数化点过程,这一差别在先验知识匮乏、数据分布复杂的情形下更为突出。我们将分别从这两个方向来介绍。由于深度点过程是一个新兴的领域,我们将更详细的介绍其代表性的工作及相应的表示形式。由于之前传统参数化点过程(以及更为复杂的非参数化版本)的相关研究工作经常发表在统计领域,因此我们将其称作统计点过程来区别基于神经网络的深度点过程。
传统统计点过程
在本文中,统计点过程被分为参数化点过程和非参数化点过程两类。后者对点过程条件强度函数的形式并未事先加以指定。
2.1似然函数
我们首先基于条件强度函数来推导得到联合似然函数,推导的前提是假设点过程是常规点过程[3]。为了简化符号表示,我们省略了事件的标值(event marker),这并不会对公式的表示产生本质的改变。若对于区间[0,T]内的一个事件序列 ,其联合似然函数的表示为:
其中 ,
表示
不发生事件的概率。对于条件密度函数
,其可以由条件强度函数
通过推导得到:
是生存函数,表示上一时刻t_i到时刻t没有事件发生的概率,可以由条件强度函数求得:
即可得到 时刻条件密度函数的表示:
进而可以得到对数似然函数为:
上述公式是针对不带标记的点过程形式。关于带标记的点过程的更多细节可以参考[8],这里不再赘述。
2.2典型点过程模型
泊松过程(Poisson process):最早关于泊松过程的研究可以追溯到1900年左右,早先提出的是齐次泊松过程,$$λ(t)= λ\_0>0$$,认为强度函数值是一个恒定的值,独立于历史事件。与齐次泊松过程相比,非齐次泊松过程则认为λ(t)是随时间变化的函数。而Cox提出了经典的重随机泊松过程[9],将强度函数看成是一个受到各种外部因素影响的随机变量。
强化泊松过程(reinforced Poisson processes):强化泊松过程[10]获取的是一种“强者更强”(类似马太效应)机制,其只关注历史事件的影响, ,其中
是衰退函数,
是历史事件影响的累计函数。
自/互激励过程(self/mutual-exciting process):自激励过程[11],亦称为霍克斯过程(Hawkes processes,后以1971年提出者Hawkes教授姓氏命名),其内部机制表示发生的历史事件对于未来事件的发生有激励作用,并且历史事件的影响以累加的形式进行叠加。强度函数为
上述第一项 和第二项
分别代表了基础强度与历史事件对当前的激励作用。
活性点过程(reactive point processes):活性点过程[12]可以认为是对霍克斯过程的一种扩展,霍克斯过程只考虑事件的激励影响,而活性点过程既考虑历史事件的激励影响又考虑历史事件的抑制影响,强度函数为:
上述第二项 与第三项
分别代表了历史事件的激励与抑制效应。
自校正过程(self-correcting process):自纠正过程[13]的强度函数是随着时间稳步提升,一旦有事件发生,则强度函数乘以 就会回落,强度函数为:
通常基于自校正过程的事件比基于其它如齐次泊松过程、自激励过程的事件更加均匀。
通过不同的条件强度函数形式,可以建立不同特点的序列模型。图2给出了关于泊松点过程、自激励和自校正点过程的示意图,不同箭头形状代表不同事件类型。
2.3基于最大似然的学习算法
参数化时序点过程模型
参数化时序点过程模型大多数都是通过优化对数似然函数或者其下界来达到模型学习的目的。由于似然函数(目标函数)中存在对于之前所有点的累积,为分析优化带来了很大的问题。Ozaki等人[14]在1979年提出可以直接计算出对数似然函数的梯度值和海森矩阵,但是这种方法收敛很慢。Veen和Schoenberg[15]开创性地提出了针对一大类点过程的期望最大化(expectation-maximization,EM)算法框架。通过构造目标函数的下界,在每一次迭代中,将所有参数解耦,使得每一个参数可以独立求解,成为目前参数化时序点过程的主要学习框架。对于含有事件类型的多维点过程,为了解决维度爆炸问题,一般引入稀疏和低秩正则来加速收敛[16]。由于霍克斯过程可以看成是一个分支过程,背景函数和激励项可以通过类似于EM算法估计混合高斯模型一样来求解。然而,该属性为霍克过程所独有,并不适用于其他点过程。除EM算法,一些其他的技术,例如基于采样的方法,可用于解决活性点过程[12]的学习。
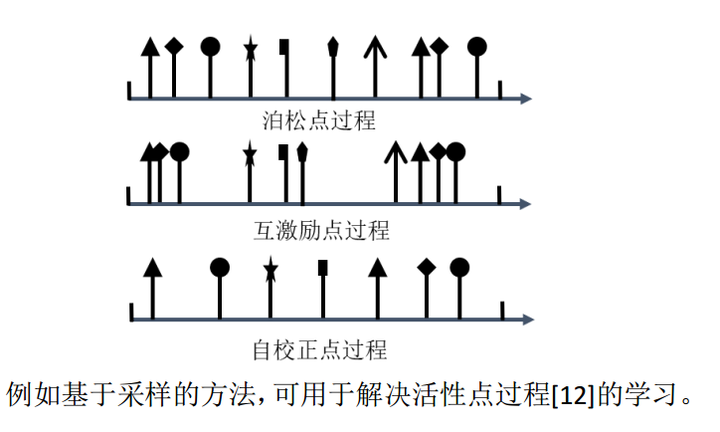 图2. 三类典型点过程模型对应的连续时间域事件序列示意图。
图2. 三类典型点过程模型对应的连续时间域事件序列示意图。
非参数时序点过程模型
为了提高模型容量,非参数化时序点过程模型也成为一个重要的研究方向。本文中也将其归纳到统计点过程范畴中,与深度点过程模型加以区分。非参数化时序点过程模型不会给出明确的强度函数形式,而是采用隐式正则项。对非参数化的霍克斯过程的研究引起了很多关注。由于霍克斯过程的分支特性,基于EM算法被广泛的应用:Marsan和Lengline开创性地提出了模型独立随机分离法(MISD)[17],在此基础上增加正则项即可得到带惩罚的极大似然估计法(MPLE)[18],结合常微分方程相关技术,该方法被用来求解非参数化的激励核。这些工作促进了多维霍克斯过程非参数化方法的发展[19]。
2.4霍克斯过程实例
在统计学和机器学习文献中,霍克斯过程已经成为一种重要的点过程形式。这里将展示基于最大似然估计的参数化霍克斯过程和其非参数化变体的学习方法。
参数化模型
首先给出霍克斯过程经典的强度函数形式:
一般情况下 ,表示衰减函数,其中w代表历史事件对当前影响的衰减指数。
参数化模型一般通过极大似然估计来估计模型参数,令 ,则
其中G(t)是激励项g(τ)从τ=0到τ=t的积分,因此G(0)=0。为了求解参数,可以使用EM算法,我们可以通过引入辅助变量 和
,利用琴生不等式来得到对数似然函数的下界:
在expectation步,估计 以及
,分别可以表示为事件
是由基础强度引起μ的和由事件
所激励而引起的。在maximization步,求其偏微分,即令
和
为0求得μ和α得解析解。不断迭代求解直到模型收敛,可以得到参数的估计值。这一算法亦属于Majorization-minimization的优化框架。
非参数化模型
我们将上述模型转化成非参数化的形式,没有了明确的μ(t)和g(t),而是增加了针对背景函数和激励项的正则化项:
使用EM算法解决非参数化模型的学习问题,首先引入辅助变量 (若事件i由事件j的触发,则
,否则为0)和
(若事件i受到自身背景影响而发生,则
,否则为0)。目标函数重写为:
EM算法将求解μ(t)和g(t)转化成两个子问题来分别求解,求解μ(t)对应的子问题为(类似地可以求解g(t)对应的子问题):
令 ,我们可以得到欧拉-拉格朗日公式:
其中,C和D是固定的参数。该问题在对时间变量离散化后,可以利用现成的ODE数学工具求解。
深度点过程
正如前面提到过的,传统统计点过程模型中的参数化模型存在人工模型选择错误的风险,如果人工预先选择的强度函数和事件数据规律是不符的,那模型的效果往往大打折扣。而非参数化模型由于学习算法更为复杂,给实际应用带来了不便。随着深度神经网络的发展,深度学习技术在多个领域展现出强大的能力,点过程和深度学习技术的融合已成为大势所趋。
3.1循环神经网络和点过程
循环神经网络(RNNs)及其变体,比如长短时记忆循环神经网络(LSTMs)已经成为深度点过程的基石。给定事件序列 ,经过循环神经网络得到输出序列
,利用这些输出可以预测事件标记的取值以及事件的发生时间。使用深度点过程最大的好处就是可以构建端到端学习模型,不必专门为某一种点过程模型设计专用的学习算法。
3.2极大似然学习
与第二章中介绍的传统时序点过程模型一样,很多基于神经网络的时序点过程模型[5][6]也采用极大似然的思想来设计目标函数。对于给定的带标记(例如事件类型)事件序列 ,可以假设事件的标记
和时间戳
是独立的,这样目标函数可以分解为两部分:
目标损失函数可以看成由两种损失构成:事件标记似然损失和事件时间似然损失,具体到表示这两种损失有多种损失函数可供选择。例如Du等人[6]使用交叉熵损失来表示离散标记,即常见的事件类别预测 ,而用条件密度函数来表示
。Mei等人[5]与[6]的区别在于[6]专门为每一种事件类型都构造了一个强度函数,而后者是只构造了一个强度函数用于表示所有类型的事件。
在上面提到的这种深度时序点过程框架下,Xiao等人[7]提出使用两个RNN网络来建模时序点过程。一个RNN建模时间序列,用于表示瞬时变化的动态信息,例如人体体温,心跳等连续变化数据;另一个RNN建模事件序列,用于表示突发的异步事件信息,例如设备突发故障等发生间隔不等的特征。某种意义下,时间序列RNN可以看作一种属性特征,类似于强度函数中的背景函数;而事件序列RNN表示的是一种历史事件的依赖,类似于强度函数中的激励项。
由于深度点过程引入了神经网络,使得模型的可解释性大打折扣,提高深度点过程模型可解释性的工作也一直受到大家的关注。Wang等人[20]将注意力机制(Attention Mechanism)应用于RNN来提高模型的可解释性。其将神经网络中的节点看成对应的事件类型,则权重边就可以认为是不同类型事件之前的互相影响,[20]引入了覆盖策略来解决传统注意力机制由于没有记忆而导致的注意力错误分配问题。Choi等人[4]使用两级注意力机制构造了逆向时间注意力模型(Reverse Time AttentIon model)。
3.3非似然学习
最大化似然其实等价于最小化KL散度(Kullback-Leibler divergence),而KL散度要求两个概率分布严格匹配,使得其对噪声和异常值非常敏感,特别是遇到多重模态分布(multi-modal distributions)时往往不够稳定。近来生成对抗网络(GAN)在很多任务中展现出出色的效果,GAN具有一定的理论基础和经验验证,是一个替代KL散度的方案。将原始GAN[21]中最优判别器下的JS距离(Jensen-Shannon distance)替换为沃瑟斯坦距离(Wasserstein distance),可以得到性能更为优秀的WGAN[24](Wasserstein GAN)。与KL散度相比,沃瑟斯坦距离能够挖掘数据底层的几何结构信息,应对多重模态分布中经常发生的模式降低(mode dropping)问题,具有较好的鲁棒性。我们将介绍两个应用在时序点过程的代表性WGAN技术:无条件生成模型[22]与条件生成模型[23]。
3.4 WGAN应用于时序点过程的实例
基于随机输入的WGAN
在WGAN中,一方面要构造一个参数化的生成器 ,其产生的序列分布应该尽量接近于真实数据分布ξ。另一方面要构造判别器,沃瑟斯坦距离和映射函数
就构成了WGAN的判别器。在文献[22]中,对梯度的近似加入了Lipschitz光滑正则,得到下述目标函数:
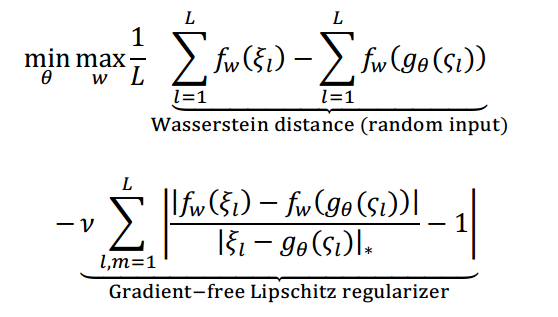
其中 是序列生成器,而
是泊松分布中随机采样得到的序列,类似于与GAN中使用[0,1]均匀分布。
上式中正则项的关键在于如何定义两个序列的沃瑟斯坦距离,也就是分母 。这个问题等价于最优传输问题,最优传输问题利用双随机矩阵将序列的点映射成两部分,根据Birkhoff的理论,双随机矩阵集的极值点是一个置换。根据这些理论,沃瑟斯坦距离可以被写成如下形式:
其中s是给定的空间边界点,表示覆盖m个点的最小的边界。若出现长度不一致的情况,则对未匹配点加以第二项作为惩罚项。这里σ是对事件序列的一个排列函数,可以证明σ(i)=i就可以得到最小值[22],对于时间窗口为[0,T),沃瑟斯坦距离表示为:
条件WGAN
基于随机输入的WGAN只能建模整个训练集的分布,而不能对单独的一条序列建模。在文献[23]中,作者将条件对抗生成网络引入时序点过程,以完成单条序列级别的预测和生成。其目标函数为:
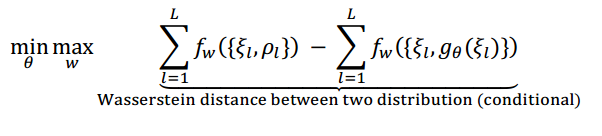
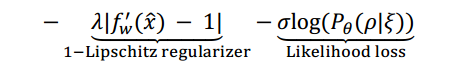
其中 是第l条序列观察到的部分,
是待预测的部分,λ和σ是用于调节不同损失占比的权重参数。
是观察到的真实序列,不同于无条件生成模型中的从泊松分布中采样得到的随机输入,
是一个序列到序列(sequence-to-sequence)的循环神经网络模型。受到WGAN[24]启发,此处采用了一个基于梯度的正则项。其中
是
和
的插值,通过采样可以得到。尽管似然损失或者KL散度仅考虑两个样本的相对概率而非接近程度,但似然损失是无偏估计而沃瑟斯坦距离是有偏的。因此将沃瑟斯坦距离和似然损失结合往往可以达到更好的效果。
应用场景与相关技术
4.1事件预测
在众多点过程模型中,自激励霍克斯过程受到的关注最多,应用的场景也最多。霍克斯过程可以用于金融[25]、生物信息学[26]、犯罪学[27]、设备维护[12]、恐怖主义[28]、社会网络[29]等众多领域。这些应用大多使用生成模型,一般基于极大似然估计来学习模型的参数。
给定一个完成训练的时序点过程模型,一个重要的应用就是对未来的事件进行预测。由于随机性的存在,一些近似和启发式纠正技术也被融入进来提高模型的预测准确率[44][45]。普遍采用的预测方法都是通过仿真来生成未来的事件。常见的仿真方法包括Shedler-Lewis细化算法(Shedler-Lewis thinning algorithm)和Ogata改进的细化算法[30](Ogata’s modified thinning algorithm)。最近Wang等人[31]采用带跳跃随机微分方程模型,将微观事件建模与宏观层面预测进行有机联系。
最后,基于模型预测的视角,也可以将时序点过程与传统分类/回归模型进行比较。首先,分类/回归模型往往通过特征工程将时序行为信息(例如历史事件序列)通过一些聚合指标(例如均值、方差、最大最小值等)进行抽取,形成固定长度的模型输入特征向量。相比之下,时序点过程模型则可以通过似然函数将原始各个事件时间戳信息加以保留,避免了聚合过程引入的信息缺失。此外,从输出的角度来看,时序点过程在时序事件预测方面也具有一些优势。通过对条件强度函数的积分和仿真采样,原则上可以获得将来任意时间窗口的事件发生次数期望,乃至置信度区间。然而,对于传统分类/回归模型,其预测变量的定义往往与预测窗口绑定(例如未来三天发生某事件的期望),无法灵活应对在预测时感兴趣窗口发生变化的情况(往往需要重新定义预测变量及重新训练模型)。事实上,在预防性维护保养等场景中,不同利益方对风险窗口的关注点往往并不相同。例如对于维保预算规划方,其感兴趣的是下一年度的设备整体风险;而对于设备维护方,其可能更关心短期的故障风险。时序点过程模型有望使用和训练一个统一模型,满足不同需求。
4.2异步序列聚类
由于很难得到一个事件序列的准确表示,对于事件序列的聚类是一个极富挑战的任务。之前对聚类任务的解决思路是先学到每一个事件序列对应的点过程模型,然后基于每一个事件序列对应的点过程模型(参数)来计算事件序列之间的距离,这样就可以使用常用的聚类算法来完成事件序列的聚类。学到的点过程模型可以是参数化的[32],也可以是非参数化的[33]。这种方法的缺点在于聚类时的聚类效果对前一步模型的学习效果很敏感,而前一步学习事件序列对应点过程的模型由于要融合多种点过程模型从而很容易发生过拟合。Xu等人[34]在2017年提出了基于狄利克雷混合霍克斯过程模型,采用联合学习的方式,同时进行事件序列学习和聚类两个任务。该方法还处理了局部可辨别性问题(local identifiability problem)。
4.3因果关联发现
这个方面最基本的任务就是利用多维点过程来学习格兰杰因果关系[35](Granger causality)。一开始是用于离散时间上,然后扩展到连续时间域上的带标值点过程。Didelez等人[36]使用多维点过程建立了一个格兰杰因果关联图(Granger causality graph)。相比于时间序列的格兰杰因果关系可以使用向量自回归模型进行学习,利用多维点过程进行关联关系学习难度更大。对于霍克斯过程,Eichler等人[37]建立起格兰杰因果关系和影响函数之间的联系:类型为u的事件和类型为v的事件是否存在格兰杰因果关联等价于影响函数ϕ_uv (t)是否为全零。基于这一结论,文献[38]采用EM算法来学习影响函数。
4.4删失/截断数据
目前大多数的时序点过程方法都假设一开始的观察窗口是完整的,也就是得到的数据是完整的序列,但是这个条件在真实场景下是很难保证的。例如,一个个体往往会去多家医院就诊,每家就诊医院记录仅为个体完整就诊记录的子序列。因此针对一家医院的观察窗口,得到的数据经常是删失和截断的。可以利用生存分析[39](survival analysis)框架处理这一问题。不同于传统的自举法[42](bootstrap method),相关文献提出了一些基于点过程的全局[40]或者局部[41]最大似然估计的方法。针对用途广泛的霍克斯过程,Xu等人提出了一种序列增强的方法[43],使用采样-拼接的序列生成方法对较短序列进行拼接得到更长的序列,试图提高模型学习效果。
4.5事件缺失属性复原
实际问题中,一些事件的属性往往缺失,影响了标准方法的建模。例如对于一次被报告的黑帮团伙冲突事件,作为事件属性信息的一部分,参与一方乃至双方的信息往往缺失,需要进行推断。
事件属性复原(event attribution)涉及对未观察到的属性进行逆向估计。逆向估计的可行性往往取决于事件本身的动态关联结构。在极端情形,对于由独立的齐次泊松过程产生的数据,事件缺失的标签就几乎无法被恢复。但幸运的是真实场景中数据都展现出高度的非齐次或者历史依赖的时序特征,也就是一种非平凡的依赖,为有效的属性复原提供了可能。Stomakhin等人[46]假设霍克斯模型的参数已知来估计帮派网络中缺失的未知的成员,而[47][48][49]致力于迭代地估计缺失的成员和点过程模型参数。其中,[48]利用平均场变分优化方法构造了一个更紧致的替代目标函数,而[49]设计了隐式点过程模型和变分EM算法同时考虑空间和时间来进行模型的学习和推断。
总结
我们见证了时序点过程在机器学习领域的快速发展。时序点过程包括传统的统计点过程和新兴的基于神经网络的方法。深度点过程为点过程的发展打开了一扇新的大门,使得点过程模型更具表达能力,并且需要更少的先验知识。可以看到,随着引入深度强化学习、生成对抗网络等技术,基于点过程的深度学习有望成为机器学习领域里一个前沿引性的研究方向。
我们注意到,在国际机器学习大会ICML2018上,德国马普所的研究人员Rodriguez和Valera组织了关于时序点过程的tutorial[50],对其学习、推断与调控等内容进行了梳理与介绍,相关的tutorial还包括[51][52][53]。而在IEEE TNNLS期刊上,笔者与杜克大学、美国雅虎研究院、谷歌DeepMind的研究人员一道组织了时空点过程的特刊《Robust Learning of Spatio-Temporal Point Processes: Modeling, Algorithm, and Applications》[54]。而在IJCAI2019上,笔者也将和雅虎的研究人员一道举办一个关于点过程学习的tutorial《Temporal Point Processes Learning for Event Sequences》[55]。期望通过上述专题和tutorial,在大数据时代吸引更多的研究者在点过程学习的各个前沿方向,特别是时序与潜在结构信息的协同学习与调控方面进行开拓,进而推动连续时间域事件序列的精细化建模与学习的发展。
值得一提的是,霍克斯过程发明者[11]英国西斯旺大学管理学院荣誉教授Alan Hawkes教授为Quantitative Finance 期刊的专题Hawkes Processes in Finance亲自撰写了霍克斯过程在金融应用的简短综述[56]。而美国史蒂文斯理工学院则将在今年6月举办主题为Hawkes Process in Finance and Data Science的夏季会议[57]。
【参考文献】
【1】D.J. Daley and Vere-Jones David. An Introduction to the Theory of Point Processes: Volume II: General Theory and Structure. Springer Science & Business Media, 2007
【2】A S. Fotheringham and D. WSWong. The modifiable areal unit problem in multivariate statistical analysis. Environment and planning A,23(7):1025–1044, 1991.
【3】I. Rubin. Regular point processes and their detection. IEEE Transactions on Information Theory, 18(5):547–557, 1972.
【4】E. Choi, M. T. Bahadori, J. Sun, J. Kulas, A. Schuetz, andW. Stewart. Retain: An interpretable predictive model for healthcare using reverse time attention mechanism. In NIPS, pages 3504–3512, 2016.
【5】H. Mei and J.MEisner. The neural hawkes process: A neutrally self-modulating multivariate point process. In NIPS, pages 6757–6767, 2017.
【6】N. Du, H. Dai, R. Trivedi, U. Upadhyay, M. Gomez-Rodriguez, and L. Song. Recurrent marked temporal point processes: Embedding event history to vectore. In KDD, 2016.
【7】S. Xiao, J. Yan, X. Yang, H. Zha, and S. Chu. Modeling the intensity function of point process via recurrent neural networks. In AAAI, 2017.
【8】T. Liniger. Multivariate hawkes processes. PhD thesis, ETH Zurich, 2009.
【9】David R Cox. Some statistical methods connected with series of events. Journal of the Royal Statistical Society. Series B (Methodological), pages 129–164,1955.
【10】R. Pemantle. A survey of random processes with reinforcement. Probability Survey, 4(0):1–79, 2007.
【11】A. G Hawkes. Spectra of some self-exciting and mutually-exciting point processes. Biometrika,58, 1971
【12】S. Ertekin, C. Rudin, and T. H McCormick. Reactive point processes: A new approach to predicting power failures in underground electrical systems. The Annals of Applied Statistics, 9(1):122–144, 2015.
【13】V. Isham and M. Westcott. A self-correcting pint process. Advances in Applied Probability, 37:629–646, 1979.
【14】T. Ozaki. Maximum likelihood estimation of hawkes’ self-exciting point processes. Annals of the Institute of Statistical Mathematics, 31(1):145 155, 1979.
【15】A. Veen and F. P Schoenberg. Estimation of space–time branching process models in seismology using an em–type algorithm. Journal of the American Statistical Association, 103(482):614–624, 2008.
【16】K. Zhou, H. Zha, and L. Song. Learning social infectivity in sparse low-rank networks using multi-dimensional hawkes processes. In AISTATS, 2013.
【17】D. Marsan and O. Lengline. Extending earthquakes’reach through cascading. Science, 319(5866):1076–1079, 2008.
【18】E. Lewis and E. Mohler. A nonparametric em algorithm for multiscale hawkes processes. Journal of Nonparametric Statistics, 2011.
【19】K. Zhou, H. Zha, and L. Song. Learning triggering kernels for multi-dimensional hawkes processes. In ICML, pages 1301–1309, 2013.
【20】Y. Wang, H. Shen, S. Liu, J. Gao, and X. Cheng. Cascade dynamics modeling with attention-based recurrent neural network. In AAAI, pages 2985–2991, 2017.
【21】I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarialnets. In NIPS, pages 2672–2680, 2014.
【22】S. Xiao, M. Farajtabar, X. Ye, J. Yan, L. Song, and H. Zha. Wasserstein learning of deep generative point process models. In NIPS, 2017.
【23】S. Xiao, H. Xu, J. Yan, M. Farajtabar, X. Yang, L. Song, and H. Zha. Learning conditional generative models for temporal point processes. In AAAI, 2018.
【24】M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein generative adversarial networks. In ICML, pages 214–223, 2017.
【25】E. Errais, K. Giesecke, and L. R Goldberg. Affine point processes and portfolio credit risk. SIAM Journal on Financial Mathematics, 1(1):642–665, 2010.
【26】P. Reynaud-Bouret, S. Schbath, et al. Adaptive estimation for hawkes processes; application to genome analysis. The Annals of Statistics, 38(5):2781–2822, 2010.
【27】G. O Mohler, M. B Short, P J. Brantingham, F. P. Schoenberg, and G. E Tita. Self-exciting point process modeling of crime. Journal of the American Statistical Association, 106(493):100–108, 2011.
【28】M. D Porter, G. White, et al. Self-exciting hurdle models for terrorist activity. The Annals of Applied Statistics, 6(1):106–124, 2012.
【29】N. Du, M. Farajtabar, A. Ahmed, A. J Smola, and L. Song. Dirichlethawkes processes with applications to clustering continuous-time document streams. In SIGKDD, pages 219–228. ACM, 2015.
【30】Y. Ogata. On lewis’ simulation method for point processes. IEEE Transactions on Information Theory, 27(1):23–31, 1981.
【31】Y. Wang, X. Ye, H. Zhou, H. Zha, and L. Song. Linking micro event history to macro prediction in point process models. In AISTATS, pages 1375–1384, 2017.
【32】D. Luo, H. Xu, Y. Zhen, X. Ning, H. Zha, X. Yang, and W. Zhang. Multi-task multi-dimensional hawkes processes for modeling event sequences. In IJCAI, pages 3685–3691, 2015.
【33】W. Lian, R. Henao, V. Rao, J. Lucas, and L. Carin. A multitask point process predictive model. In ICML, pages 2030–2038, 2015.
【34】H. Xu and H. Zha. A dirichlet mixture model of hawkes processes for event sequence clustering. In NIPS, pages 1354–1363, 2017.
【35】C. WJ Granger. Investigating causal relations by econometric models and cross-spectral methods. Econometrica: Journal of the Econometric Society, pages 424–438, 1969.
【36】V. Didelez. Graphical models for marked point processes based on local independence. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 70(1):245–264, 2008.
【37】M. Eichler, R. Dahlhaus, and J. Dueck. Graphical modeling for multivariate hawkes processes with nonparametric link functions. Journal of Time Series Analysis, 38(2):225–242, 2017.
【38】H. Xu, M. Farajtabar, and H. Zha. Learning granger causality for hawkes processes. In ICML, pages 1717–1726, 2016.
【39】J. P Klein and M. L Moeschberger. Survival analysis: techniques for censored and truncated data. Springer Science & Business Media, 2005.
【40】R. L Streit. Poisson point processes: imaging, tracking, and sensing. Springer Science & Business Media, 2010.
【41】Chun-Po Steve Fan. Local likelihood for interval-censored and aggregated point process data. PhD thesis, 2009.
【42】A. Cowling, P. Hall, and M. J Phillips. Bootstrap confidence regions for the intensity of a poisson point process. Journal of the American Statistical Association, 91(436):1516–1524, 1996.
【43】H. Xu, D. Luo, and H. Zha. Learning hawkes processes from short doubly-censored event sequences. In ICML, pages 3831–3840, 2017.
【44】S. Gao, J. Ma, and Z. Chen. Modeling and predicting retweeting dynamics on microblogging platforms. In WSDM, pages 107–116. ACM, 2015.
【45】Q. Zhao, M. A Erdogdu, H. Y He, A. Rajaraman, and J. Leskovec. Seismic: A self-exciting point process model for predicting tweet popularity. In SIGKDD, pages 1513–1522. ACM, 2015.
【46】A. Stomakhin, M. B Short, and A. L Bertozzi. Reconstruction of missing data in social networks based on temporal patterns of interactions. Inverse Problems, 27(11):115013, 2011.
【47】R Hegemann, E Lewis, and A Bertozzi. An “estimate & score algorithm” for simultaneous parameter estimation and reconstruction of missing data on social networks. Security Informatics, 2:1–14, 2012.
【48】L. Li and H. Zha. Dyadic event attribution in social networks with mixtures of hawkes processes. In CIKM, pages 1667–1672. ACM, 2013.
【49】Y. Cho, A. Galstyan, P J. Brantingham, and G. Tita. Latent self- exciting point process model for spatial-temporal networks. Discrete & Continuous Dynamical Systems-B, 19(5):1335–1354, 2014.
【50】Learning with Temporal Point Processes
【51】Research Problems, Probabilistic Models and Machine Learning Methods
【52】NetRate
【53】Machine Learning for Dynamic Social Network Analysis
【54】Information on Special Issues - IEEE Computational Intelligence Society
【55】https://www.ijcai19.org/tutorials.html
【56】A. G. Hawkes, Hawkes processes and their applications to finance: a review, Quantitative Finance 18 (2), 193-198
【57】Hawkes Process in Finance and Data Science Conference 2019