


实验
同样用held-out以及P@N 结果如下:

从结果看, 本文的方法比Lin 2016 要好, 毕竟考虑了关系的依赖性,不过提升不是很明显,可能原因是数据问题,relation的overlapping比较少。 再看一组对比实验: 分别是去掉word-attention 以及去掉 relation-attention:
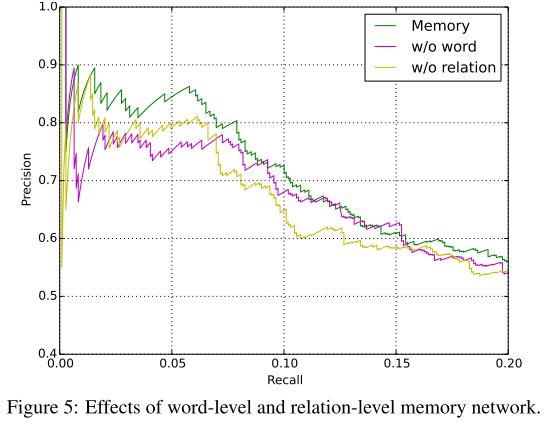
可以看出来,去掉relation之后,下降相对来说比去掉word-level更加明显。
总结
这篇文章虽然以Memory Network 为题,不过可以本质还是用Attention引入相关性。 word-level的动机来自Multi-Level 的那篇文章,计算word与target entity的相关性,并且可以多层,从而挖掘更深层次的关系。relation-level的动机则是考虑到数据中的关系依赖性,使用attention来考虑关系之间的相关性。
这篇文章创新的地方在于引入relation之间的依赖关系。 可能改进的地方有,完全从embedding的角度考虑相关性,抛弃Attention,计算量会少一些。包括word-entity embedding; relation-relation embedding;