这篇关系抽取的论文来自清华大学的刘知远教授团队,是2016年关系抽取-远程监督最经典的nn模型
论文总体描述:
运用attention机制来尽量减轻错误label的负面影响;
运用CNN(PCNN)将关系用sentence embedding的语义组合来表示,以此充分利用训练知识库的信息。
讲解参考:https://blog.csdn.net/xg123321123/article/details/53218870
给出了一组句子{x_1……x_n}和两个对应的实体,我们的模型测量每个关系r的概率。在本节中,我们将在两个主要部分介绍我们的模型:
句子编码器:给定一个句子x和两个目标实体,卷积神经网络(RNN)用于构造句子的分布式表示x。
对实例的选择性注意:当学习所有句子的分布向量表示时,我们使用句子层次的注意来选择真正表达对应关系的句子。

细致描述:
一)论文的贡献
这篇论文要解决的问题,就是多实例学习会遗漏大量信息的问题。所以这篇论文用句子级别的注意力机制代替多实例学习,对于包含某实体对的所有句子,给每一个句子计算一个注意力得分,动态地降低标注错误的样本的得分,再进行加权求和,从而充分利用所有句子的信息。
多实例学习相当于硬注意力机制(Hard Attention),而我们耳熟能详的以及论文中用到的注意力机制是选择性注意力机制(Selective Attention)或者说软注意力机制(Soft Attention),所以多实例学习其实是选择性注意力机制的特殊情况(只有一个句子的权重为1,其他全为0)。
(二)模型介绍
模型主要分为两个部分:句子编码器和注意力层。
1、句子编码器
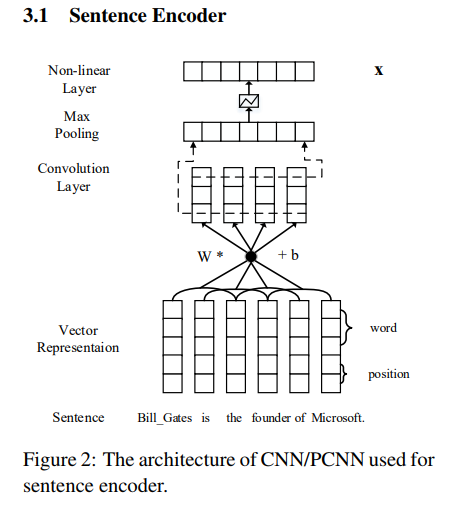
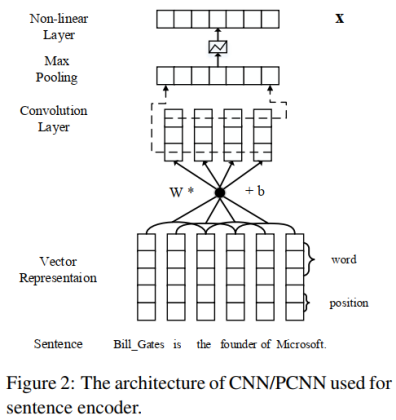
句子编码器就是上一篇论文中的PCNN或CNN网络结构,由卷积神经网络的输入层、卷积层、池化层、非线性映射层(或者说激活函数)构成。
文本特征同样用词嵌入和位置特征嵌入,池化层用普通的最大池化或者分段最大池化。
因此,本文的句子编码器部分输出的是一个句子经过最大池化并且非线性激活后的特征向量,用于输入到注意力层。这部分和上一篇论文基本相同,无须赘述。
2、注意力层
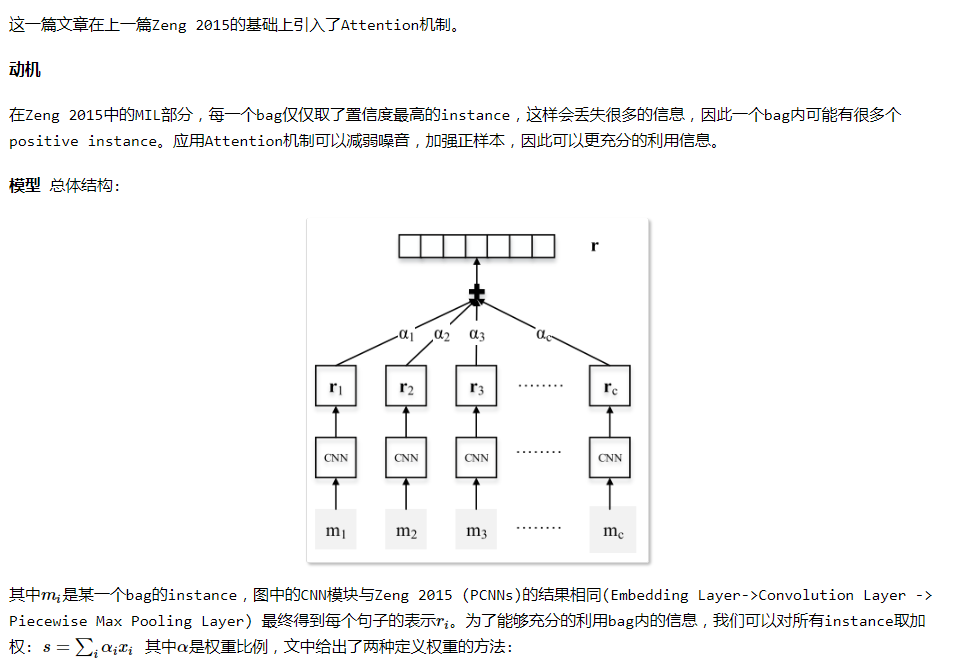
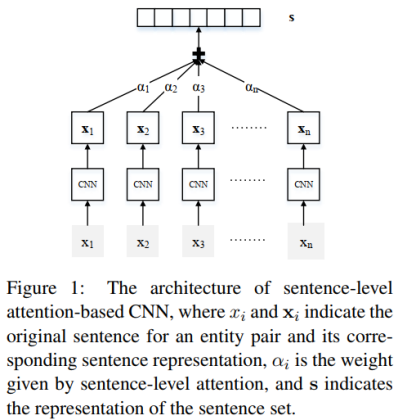
句子编码器的作用是抽取一个句子的特征,得到一个特征向量。如果外部文档库中包含某实体对的句子有n条,那么经过句子编码器的处理后,可以得到n个特征向量:x1, x2, ..., xn。在句子编码器和softmax层之间加一个选择性注意力层,那么处理的步骤如下:
第一步:计算句子的特征向量xi和关系标签r的匹配度ei,并计算注意力得分αi。公式中的r是关系标签的向量表示。

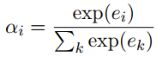
第二步:计算该实体对的特征向量s。该实体对的特征向量是所有句子的特征向量xi的加权之和,权重为每个句子的注意力得分αi。

第三步:经过softmax层得到该实体对关于所有关系的概率分布,概率值最大的关系为预测的关系标签。
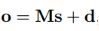
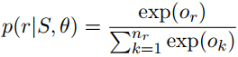
3、误差反向传播
如果一个batch-size有s个实体对,那么用s个实体对的概率分布,计算交叉熵损失:
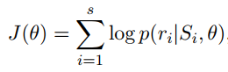
最后用梯度下降法求出梯度,并进行误差反向传播。
(三)实验细节
1、数据集和评估方法
数据集和上一篇论文一样,知识图谱是Freebase,外部的文档库是NYT(New York Times corpus)。划分数据集的做法也一致。
评估方法采用留出法,不再赘述。
2、词嵌入和参数设置
用NYT数据集训练Word2Vec,用网格搜索(Grid Search)确定参数。

3、选择性注意力机制的效果
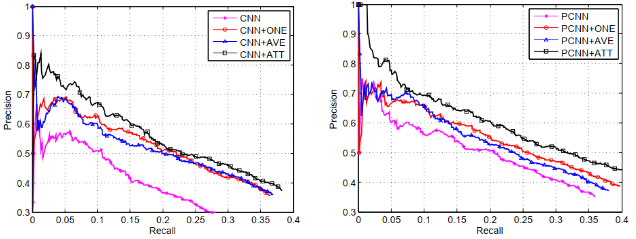
句子编码器分别采用CNN和PCNN的网络结构,PCNN+ONE表示PCNN结合多实例学习的模型,PCNN+ATT表示论文中的选择性注意力模型,PCNN+AVE表示对各句子求算术平均的模型(每个句子的注意力得分相同)。
实验结果表明,无论是CNN还是PCNN,加入注意力机制的模型在查准率和查全率上,都显著优于其他模型。
论文还有其他更细致的实验,欲知详情,请自行翻看论文。
(四)评价
这篇论文把注意力机制和CNN句子编码器结合,用来解决多实例学习存在的遗漏信息问题,更好地缓解了远程监督算法中的样本错误标注问题。
注意力机制在NLP任务中的效果是有目共睹的,PCNN+ATT的模型看起来非常漂亮,那么有什么改进方向呢?
开头我们说了,关系抽取可以分为流水线式抽取(Pipline)和联合抽取(Joint Extraction)两种,流水线式抽取就是把关系抽取的任务分为两个步骤:首先做实体识别,再抽取出两个实体的关系;而联合抽取的方式就是一步到位,同时抽取出实体和关系。
因此上面介绍的三篇论文中的模型都属于流水线式抽取的方法,实体识别和关系抽取的模型是分开的,那么实体识别中的误差会影响到关系抽取的效果。而联合抽取用一个模型直接做到了实体识别和关系抽取,是一个值得研究的方向。
(转载)